




- @qq_25443541
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
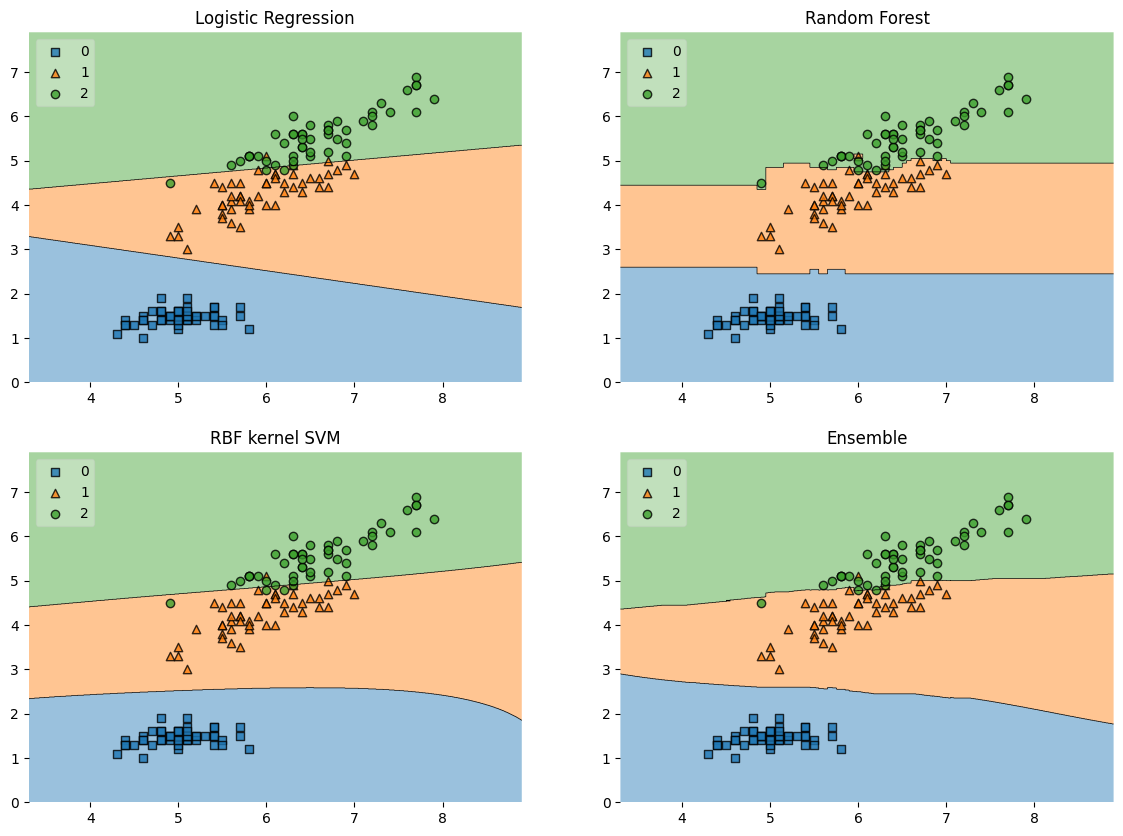
公众号:尤而小屋编辑:Peter作者:Peter大家好,我是Peter~今天给大家介绍一个强大的机器学习建模扩展包:mlxtend。mlxtend(machine learning extensions,机器学习扩展)是一个用于日常数据分析、机器学习建模的有用Python库。mlxtend可以用作模型的可解释性,包括统计评估、数据模式、图像提取等。mlxtend是一个Python第三方库,用于支持
深入浅出Pandas数据分析大家好,我是Peter~《深入浅出Pandas数据分析》第一版本终于可以和大家见面咯!文末有资料领取方式从4月24号的第一篇Pandas文章:《一切从爆炸函数开始》,到昨天8月5号的《图解Pandas的轴旋转函数:stack和unstack》,总共历时103天,让Pandas来见证吧:两行代码告诉你两个日期之间的时间差,这就是Pandas????什么是Pandas什么是

公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~
公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~本文记录了第一个基于卷积神经网络在图像识别领域的应用:猫狗图像识别。主要内容包含:数据处理神经网络模型搭建数据增强实现本文中使用的深度学习框架是Keras;图像数据来自kaggle官网:https://www.kaggle.com/c/dogs-vs-cats/data数据处理数据量数据集包含25000张图片,猫和狗各有125

小批量随机梯度下降(Mini Batch Stochastic Gradient Descent, MB-SGD)是梯度下降算法的一种改进,结合了批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent, SGD)的优点。具体来说,AdaGrad通过累积过去所有梯度的平方和来为每个参数动态调整学习率,使得较少更新频繁出现的特

公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~写过很多关于Pandas的文章,本文开展了一个简单的综合使用,主要分为:如何自行模拟数据多种数据处理方式数据统计与可视化用户RFM模型用户复购周期构建数据本案例中用的数据是小编自行模拟的,主要包含两个数据:订单数据和水果信息数据,并且会将两份数据合并import pandas as pdimport numpy as npim

公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~今天给大家介绍一款超赞的空间(地理)数据可视化神器:keplergl。小编最近偶然发现的这个神器是Uber完全开源的,也是Uber内部进行空间数据可视化的默认工具。通过其面向Python开放的接口包keplergl,我们可以在jupyter notebook中通过书写Python代码的方式传入多种格式的数据,在其嵌入noteb

公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~本文介绍3个案例来帮助读者认识和入门深度学习框架Keras。3个案例解决3个问题:回归、二分类、多分类目录为什么选择Keras相信很多小伙伴在入门深度学习时候首选框架应该是TensorFlow或者Pytorch。在如今无数深度学习框架中,为什么要使用 Keras 而非其他?整理自Keras中文官网:Keras 优先考虑开发人员

公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~本文记录了第一个基于卷积神经网络在图像识别领域的应用:猫狗图像识别。主要内容包含:数据处理神经网络模型搭建数据增强实现本文中使用的深度学习框架是Keras;图像数据来自kaggle官网:https://www.kaggle.com/c/dogs-vs-cats/data数据处理数据量数据集包含25000张图片,猫和狗各有125
公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~本文记录了第一个基于卷积神经网络在图像识别领域的应用:猫狗图像识别。主要内容包含:数据处理神经网络模型搭建数据增强实现本文中使用的深度学习框架是Keras;图像数据来自kaggle官网:https://www.kaggle.com/c/dogs-vs-cats/data数据处理数据量数据集包含25000张图片,猫和狗各有125