




- @qq_25078673
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了Agent Skills的概念与应用。Skills是一种模块化指令集合,通过文件夹形式为AI智能体扩展专业能力,具有开放标准、可复用等特点。文章详细说明了Skills的核心结构(包含指令、脚本和资源文件)以及SKILL.md的标准格式。Skills适用于专业知识传递、工作流程标准化等场景,能显著提升智能体任务执行的效率和一致性。通过为不同领域Agent(如编程、营销、金融等)配备相应Sk
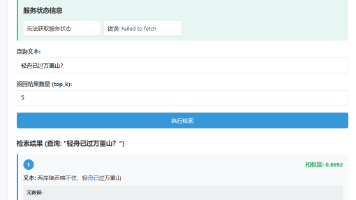
本文介绍了基于Faiss的文本和图像语义检索实战案例。在文本检索部分,展示了如何构建李白诗歌问答系统,包括数据预处理、向量生成和API开发;图像检索部分则演示了论坛图片相似检索系统的实现方法。文章还详细讲解了工程化部署的三大核心问题:索引增量更新策略(直接添加/索引合并)、性能监控(Prometheus指标采集)和容错处理(备份机制/服务高可用)。最后总结了文本和图像检索系统的实践经验,并提供了相
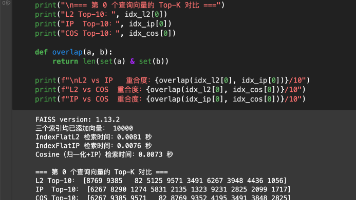
Auto-Tune(自动参数调优):Faiss提供的工具链,旨在自动找到满足检索精度(Recall)约束的最优参数配置,平衡精度与检索速度(QPS/Latency)目标:给定Recal阈值前提下,最小化检索延迟,同时兼顾内存占用。没有评估的调优就是盲目试错。HNSW关键参数说明。
文章摘要: 在大模型(如Transformer架构)中,总参数量(Total Parameters)和活跃参数(Active Parameters)是两个关键但不同的概念,它们的关系和意义直接影响模型的效率、性能和落地可行性。
摘要 Faiss索引类型对比与选择指南:IndexFlat作为基础精确检索索引,提供L2、内积和余弦三种距离度量,适用于小数据基准测试。IVF系列索引通过聚类分桶和局部检索实现高效搜索,核心参数nlist和nprobe需要权衡精度与效率。PQ量化索引采用"拆分-量化-编码"技术压缩高维向量,IndexPQ适用于中小规模数据,IndexIVF_PQ结合倒排文件技术更适合大规模应用
本文介绍了Faiss向量数据库的核心概念与使用方法。主要内容包括:1)环境依赖与CPU版本安装验证;2)Faiss的数据结构体系,重点解析Index基类及其常见派生类的特性与适用场景;3)向量存储的数据格式要求与维度约束;4)ID映射机制的使用方法;5)通过随机向量检索示例演示基础API使用流程。文章最后指出Faiss作为算法库的特性,强调其需要结合其他系统实现完整存储功能,并提供了参考文档链接。
本文介绍了大语言模型(LLM)相关参数的设置建议。在Token设置方面,针对不同场景(如问答、RAG、代码生成等)推荐了合适的max_new_tokens值。在解码参数方面,分析了Top-K对生成多样性的影响及推荐取值,并解释了SimilarityThreshold在RAG中的作用和推荐阈值。最后详细说明了segmentMaxTokens在文本切分中的用途和不同应用场景下的推荐取值,如通用问答推荐
本文详细介绍了如何从零开发并部署自定义MCP Server的全流程。首先解释了MCP协议作为LLM与外部交互的标准协议,及其核心架构。然后通过Python代码示例展示了本地开发调试过程,包括定义MCP工具方法和启动SSE服务。重点演示了在Function AI平台上部署MCP服务的完整步骤,包含WebIDE调试、依赖安装和部署测试。最后介绍了如何在MCP广场调用自定义服务,并提供了丰富的参考文档和