




- @qq_22472047
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
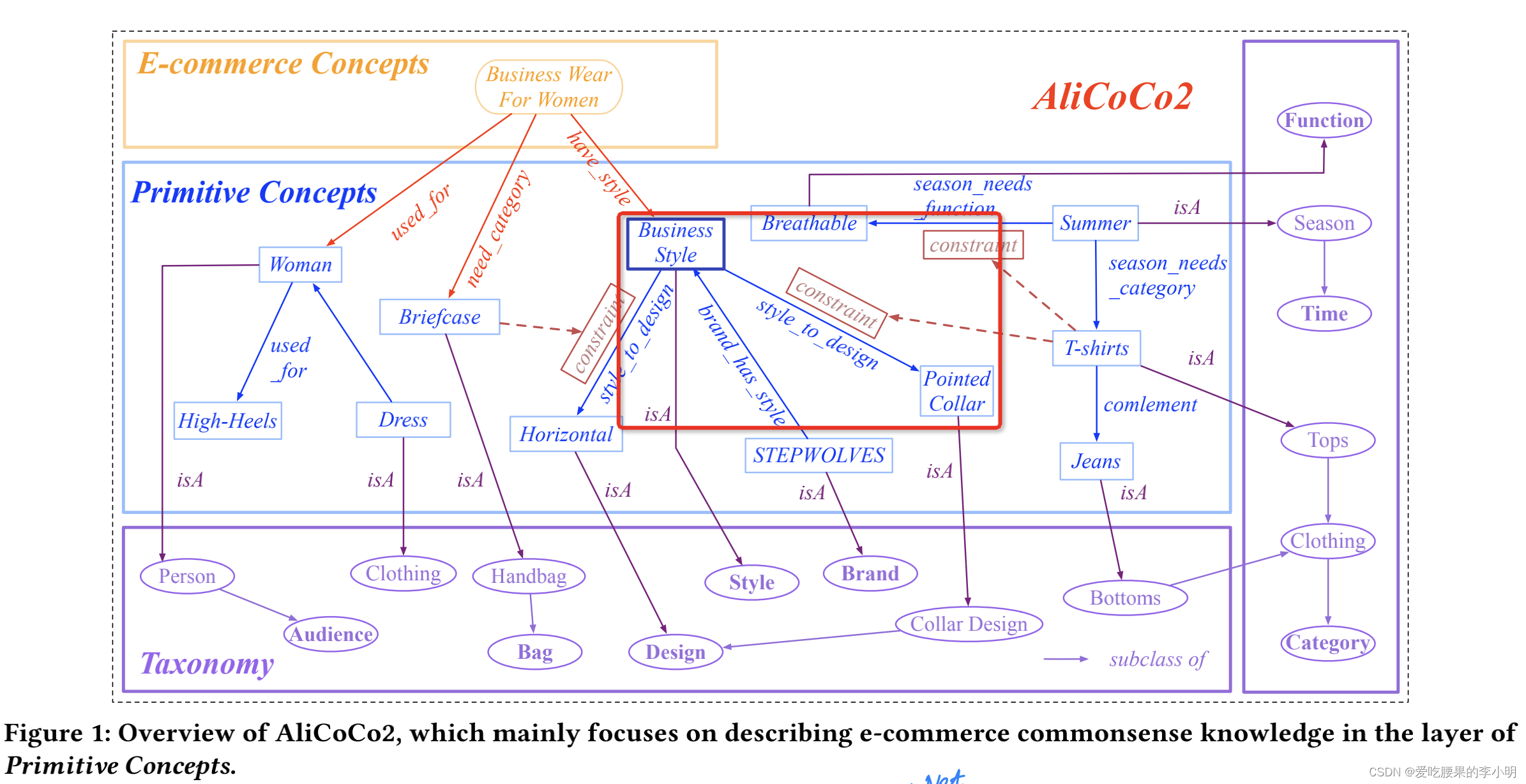
原文标题:《AliCoCo2: Commonsense Knowledge Extraction, Representation and Application in E-commerce》背景在网购时,消费者会输入query检索自己想要的商品,在人的主观意识中,搜索query隐含着许多常识性的知识,比如“天气转凉时需要穿更厚更保暖的衣服”,“商务风格的衬衫通常的立领的”,“孕妇需要防滑的鞋子和防
一、Mean Rank方法:对于每个评测三元组,移去头部实体(迭代的方式替换尾部实体)、轮流替换成词表中的其他实体,构建错误的三元组实体。利用关系函数计算头部实体和尾部实体的相似度。对于这个相似度来讲,正确的三元组的值应该比较小,而错误样本的相似度值会比较大。用关系函数对所有的三元组(包括正确的三元组和错误的三元组)进行计算,并按照升序排序。并找出所有正确三元组在该排序中的排名位置做平均。对于一个
一、前言关系抽取作为知识图谱三元组抽取任务中最最重要的算法,一直受到工业界和学术界的广泛研究。关系抽取任务要做的是识别文本中的实体,并对相应的实体词预测正确的关系。其主要可以归纳为两种主要的技术框架:1. pipeline方式的抽取:即先抽取实体,在预测已抽取实体之间存在的关系2. joint方式的抽取:即实体和关系的联合抽取模式由于pipeline抽取方法存在的误差积累、冗余实体计算、实体关系抽
预训练模型给各类NLP任务的性能带来了巨大的提升,预训练模型通常是在通用领域的大规模文本上进行训练的。而很多场景下,使用预训练语言模型的下游任务是某些特定场景,如金融,法律等。这是如果可以用这些垂直领域的语料继续训练原始的预训练模型,对于下游任务往往会有更大的提升。以BERT为例,利用huggingface的tranformers介绍一下再训练的方式:1. 定义tokenizerbert的预训练模
踩了无数坑,总结出来的首先安装miniforge,注意miniforge的版本,这里有很多教程,可以搜索mac M1 miniforge安装然后创建虚拟环境:conda create -n d2l python=3.8conda info --envconda activate d2l安装torch,torchvision等包conda install pytorch torchvision -c
错误详情:ERROR: Command errored out with exit status 1:command: '/Users/XXX/...''/Users/XXX/..._in_process.py' build_wheel '/Users/XXX/...'cwd: /Users/XXX/.../pip-install-sza2_lmj\tokenizersComplete outpu
pyhanlp是基于Java开发的自然语言处理工具包,由于我整个工程是基于Python写的,在安装pynlp时踩了很多坑,记录下来给其他需要的人一个参考。1. 升级TensorFlow到指定版本pip install tensorflow==版本号 -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com...
Mac M1芯片安装sentence-transformers报错:Failed to find sentencepiece pkg-config解决方法
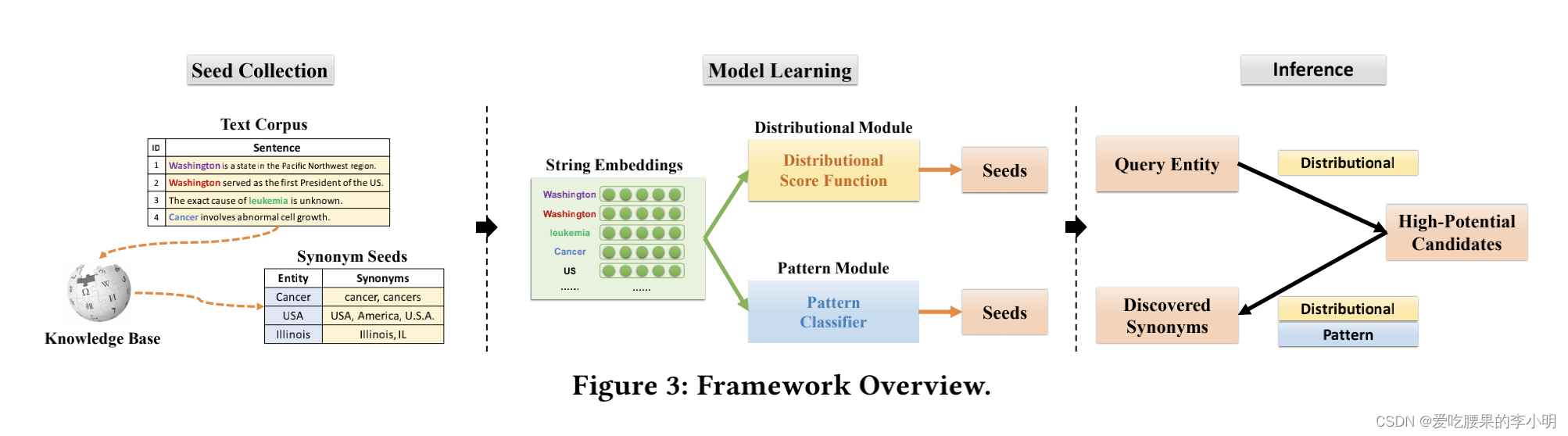
原论文:《Automatic Synonym Discovery with Knowledge Bases》背景知识同义词抽取是一种NLP领域下游任务使用广泛的基础任务,可以用于实体归一、融合,实体链接,query改写,提高召回等任务。现有的方法有:1)直接利用Freebase, WordNet等知识库直接扩充,但这对于领域的实体覆盖率很低;2)人工维护同义词典,成本非常高;3)监督/弱监督方法,
Mac M1芯片安装sentence-transformers报错:Failed to find sentencepiece pkg-config解决方法