写文章




- @qq_20144897
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
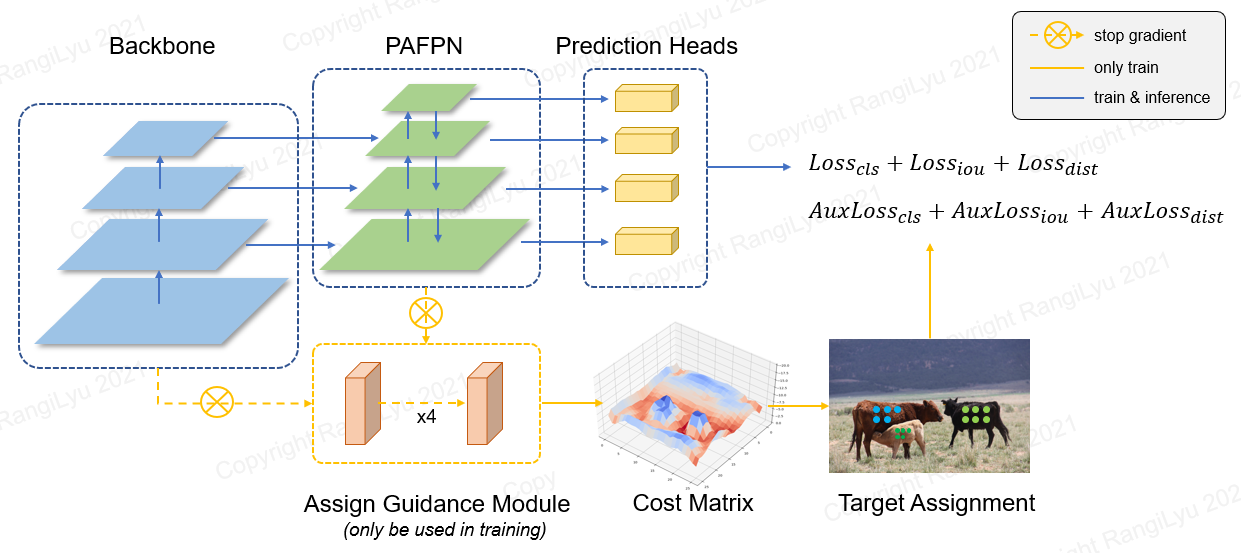
轻量级目标检测模型NanoDet-Plus微调、部署(保姆级教学)
超轻量级目标检测模型NanoDet-Plus微调、ONNRuntime部署保姆级教学!
强化学习(探险者寻宝藏)
强化学习(探险者寻宝藏)
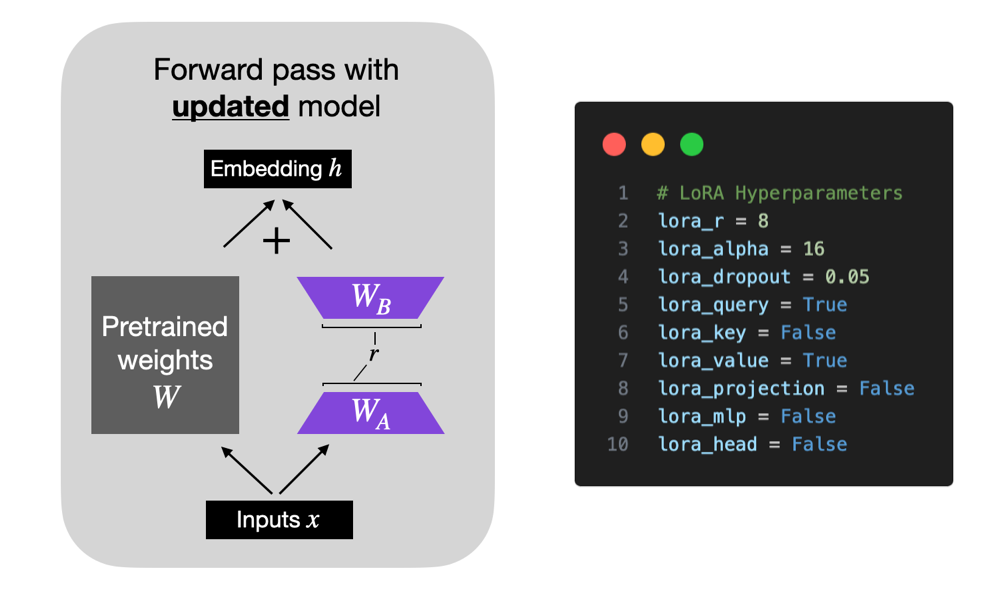
使用LoRA和QLoRA微调LLMs:数百次实验的见解
使用LoRA和QLoRA微调LLMs模型的最佳实践,以及调参建议
大语言模型的简易可扩展增量预训练策略
大语言模型(LLMs)通常需要在数十亿个tokens上进行预训练,一旦有了新数据,又要重新开始训练。更有效的解决方案是增量预训练(Continue PreTraining)这些模型,这与重新训练相比可以节省大量的计算资源。然而,新数据带来的分布偏移通常会导致在旧数据上的性能下降或者对新数据的适应性不佳。


Phi-2小语言模型QLoRA微调教程
微软发布的Phi-2模型在kaggle平台上的QLoRa微调教程

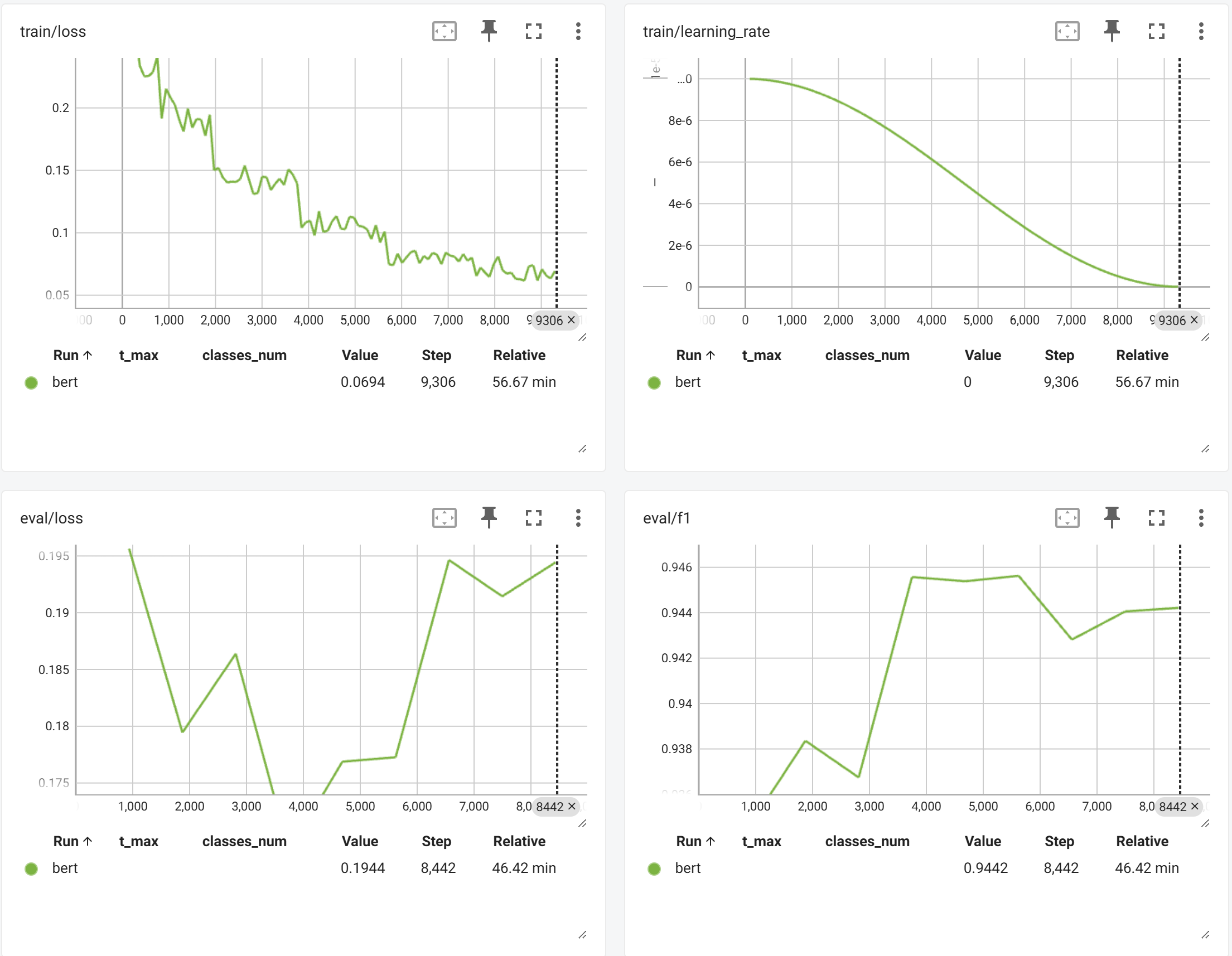
文本分类任务Qwen3-0.6B与Bert:实验见解
本文通过实验比较了Qwen3-0.6B和Bert在文本分类任务中的表现。实验使用AG News数据集,Bert通过添加线性层进行微调,而Qwen3-0.6B则通过构造Prompt进行SFT训练。结果显示,Bert在测试集上的F1得分为0.945,而Qwen3-0.6B的F1得分为0.944,两者表现接近。实验表明,尽管Qwen3-0.6B参数量较大,但在文本分类任务中并未显著优于Bert。实验还指
微调Hugging Face中图像分类模型
在kaggle平台上使用P100 GPU微调Hugging Face中图像分类模型vit-base-patch16-224

轻量级目标检测模型NanoDet-Plus微调、部署(保姆级教学)
超轻量级目标检测模型NanoDet-Plus微调、ONNRuntime部署保姆级教学!