




- @private_void_main
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
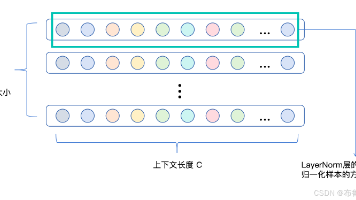
摘要:归一化是训练深层网络的关键技术,用于解决梯度消失或爆炸问题。文本领域采用LayerNorm(LN)而非BatchNorm(BN),因文本长度不固定且含无意义padding。LN对每个样本所有特征归一化,而RMSNorm简化计算仅用均方根。DeepNorm则针对超深层网络设计,结合残差连接优化数据分布。归一化位置分为层前(Pre-Norm)和层后(Post-Norm),前者更易训练但后者能力更
本文系统梳理了深度学习优化器的进化历程:从牛顿法的理论理想出发,到AdaGrad引入梯度平方和模拟曲率,RMSProp改进为指数加权平均避免学习率衰减过快,再到集大成的Adam结合动量和自适应学习率。特别指出Adam在处理L2正则化时的缺陷,以及AdamW如何通过解耦权重衰减来解决这一问题,使其成为大模型训练的首选。各优化器的核心思想与适用场景形成鲜明对比,展现了算法设计中对计算效率与优化效果的持
摘要:本文对比了批量标准化(BN)和层标准化(LN)在深度学习中的差异及其适用场景。BN通过mini-batch的统计量进行特征维度标准化,能有效缓解内部协变量偏移问题,但难以处理NLP中的变长序列。而LN则在单个样本内部进行标准化,天然适配变长数据且不受batch size影响。Transformer选择LN主要基于三点:1)适应NLP变长序列特性;2)对小batch size不敏感;3)提供更
本文深入探讨了旋转位置编码(RoPE)及其扩展方法YaRN。RoPE通过旋转矩阵在query和key向量中注入位置信息,巧妙利用不同频率编码近距离和远距离位置关系。传统上下文窗口扩展方法(如位置内插)存在分辨率下降问题。YaRN基于NTK理论,提出非均匀缩放策略:高频维度保持原样,低频维度进行压缩。该方法通过引入阈值参数区分不同频率区域,实现更精细的扩展控制。相比直接内插,YaRN能在保持模型微观
linux 下安装cuda 11.8 驱动以及开发包教程,以centos 7为例
摘要:归一化是训练深层网络的关键技术,用于解决梯度消失或爆炸问题。文本领域采用LayerNorm(LN)而非BatchNorm(BN),因文本长度不固定且含无意义padding。LN对每个样本所有特征归一化,而RMSNorm简化计算仅用均方根。DeepNorm则针对超深层网络设计,结合残差连接优化数据分布。归一化位置分为层前(Pre-Norm)和层后(Post-Norm),前者更易训练但后者能力更
本文系统梳理了深度学习优化器的进化历程:从牛顿法的理论理想出发,到AdaGrad引入梯度平方和模拟曲率,RMSProp改进为指数加权平均避免学习率衰减过快,再到集大成的Adam结合动量和自适应学习率。特别指出Adam在处理L2正则化时的缺陷,以及AdamW如何通过解耦权重衰减来解决这一问题,使其成为大模型训练的首选。各优化器的核心思想与适用场景形成鲜明对比,展现了算法设计中对计算效率与优化效果的持
本文深入探讨了旋转位置编码(RoPE)及其扩展方法YaRN。RoPE通过旋转矩阵在query和key向量中注入位置信息,巧妙利用不同频率编码近距离和远距离位置关系。传统上下文窗口扩展方法(如位置内插)存在分辨率下降问题。YaRN基于NTK理论,提出非均匀缩放策略:高频维度保持原样,低频维度进行压缩。该方法通过引入阈值参数区分不同频率区域,实现更精细的扩展控制。相比直接内插,YaRN能在保持模型微观
虽然esp8266有很多种,但是对于我们初学者来说,只需要有RXD,TXD,VCC,GND四个引脚,简单入门足够了1. 引脚说明:VCC连接正极(有些是3.3V,有些是5V,我的这个是5V),GND连接负极RXD:数据的接收端 (连接单片机或者USB转TTL模块的TXD)TXD:数据的发送端 (连接单片机或者USB转TTL模块的RXD)RST: 复位,低电平有效IO_0:用
总器件:Esp8266模块,USB转TTL模块,同时电脑上要有”网络调试助手”和”串口助手”一般而言,当我们用USB转TTL模块与Esp8266连接之后,波特率默认为115200当我们用这个模块箱Esp8266发送数据的时候,串口助手记得勾选”发送新行”当我们上电之后Esp8266 我们串口助手一直接受到乱码,可能是电压过低,可以考虑将3.3V换成5V我们直接利用AT指...