




- @plmm__
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
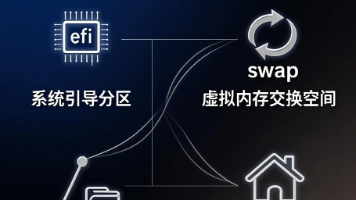
本文介绍了Linux系统安装时的分区方案建议。对于单硬盘用户,推荐创建三个基本分区:EFI分区(200-500MB FAT32格式)、swap分区(内存1-2倍)、根分区(剩余空间ext4格式)。多硬盘用户可额外增加/var和/home分区。作者倾向于不单独创建/boot分区,将其合并到根分区以便灵活管理多内核版本。文章还提供了Windows+Ubuntu双系统引导的参考链接。
本文介绍了基于TensorRT 8.6.1和CUDA 11.8环境的YOLOv8目标检测模型推理实现。通过YOLOv8TRTInference类封装了完整的推理流程,包括图像预处理、模型推理和后处理。关键实现包括:1)使用letterbox保持图像宽高比;2)支持COCO数据集80类检测;3)包含NMS后处理优化;4)提供详细的推理时间统计。测试结果表明,该方法能有效完成目标检测任务,并支持结果可

本文介绍了基于OpenVINO 2025.3的YOLO模型推理实现方案。主要内容包括:1) 环境配置(Python 3.11);2) 支持YOLOv5及后续版本的通用推理框架,采用动态输入尺寸和LetterBox预处理;3) ONNX模型转换OpenVINO格式的完整代码;4) YOLOv13推理实现,包含预处理、推理、后处理全流程;5) 支持多设备推理(CPU/GPU)。该系统具有通用性强、自动

本文探讨了在无独立显卡环境下部署大语言模型的三种方案:Ollama(简单易用但定制性差)、vLLM(GPU优化但CPU兼容性差)和OpenVINO(针对Intel CPU优化)。作者基于i7-13700H/32G内存环境,选择OpenVINO方案部署Qwen3-8B模型,详细介绍了使用Optimum-Intel工具进行INT4量化的转换过程(包括命令行和Python接口两种方式),以及转换前后的目

本文介绍了基于OpenVINO的本地AI模型部署方案,包含前端交互界面和后端服务器实现。前端采用HTML/CSS/JavaScript构建聊天界面,支持状态检测和消息交互;后端使用Flask框架提供REST API,通过OpenVINO GenAI实现模型推理优化。系统在CPU上运行DeepSeek-R1-8B量化模型,内存占用约10GB,推理耗时40秒左右。文章详细展示了前后端代码实现,包括模型

本文介绍了在RK3588开发板上基于DRMPrime和RGA硬件加速的视频处理优化方案。通过FFmpeg的RKmpp插件实现硬件解码,输出为DRMPrime格式的DMA缓冲区,避免了CPU参与的数据拷贝。作者详细阐述了如何修改解码器设置以支持DRMPrime输出,并展示了如何将解码后的NV12格式数据直接送入RGA进行硬件加速的色彩空间转换。文章还探讨了处理H264编码中stride对齐问题的解决
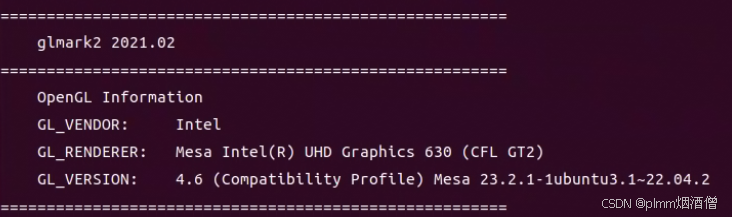
Ubuntu使用独立显卡运行glmark2跑分
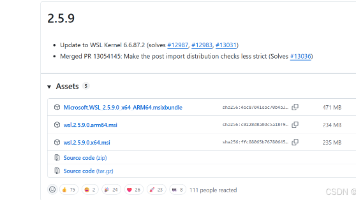
摘要:Win11更新WSL至2.6.2版本后出现systemd启动失败问题,经确认是官方已知BUG。建议降级至2.5.9版本(内核6.6.87.2-1),只需下载安装wsl.2.5.9.0.x64.msi包即可解决该问题,且不影响系统稳定性。若需保留新版本功能,可参考Github社区其他解决方案。(98字)
将本地 git 仓库推送到远程新仓库(建立连接)
github配置SSH公钥后无法连接
