




- @pika2002
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
C++与matlab进行联合编程。由于我需要使用fftw库进行编程,因此我需要在Visual Studio中进行编译。如果程序没有使用额外的库,可以直接在Matlab的命令窗口中进行编译,这样就无需配置Visual Studio,更加方便。需要注意的是,使用到的.dll文件需要复制到.mexw64C文件的同级目录中。这样,我们就能够直接调用该函数(函数名即为mexw64C文件的名称)进行编程。
传统大语言模型通过预测下一个token的概率来生成文本,其损失函数通常采用softmax分类器,这使得它们难以直接处理回归任务(需要输出连续数值)。然而,大模型具备强大的高维特征编码能力,我们可以利用预训练模型作为特征提取器,通过微调适配回归任务,从而获得优异的性能表现。• 训练方式:取最后一个token的隐藏状态(1,896),使用RMS损失函数计算回归结果。本示例使用大模型计算句子相似度,输出
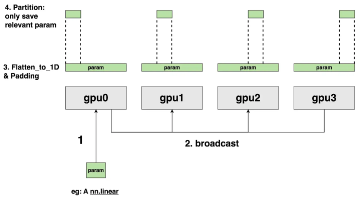
摘要: DeepSpeed ZeRO3通过全面切分模型参数、梯度与优化器状态,显著降低单卡显存占用。每张GPU仅保留本地数据分片,通过all_gather临时聚合参数进行前向计算,反向传播使用reduce_scatter同步梯度。以4卡为例,显存占用从17GB降至5GB。通信操作(如all_gather、reduce_scatter)伴随短暂全量数据缓存,结合Offload策略可进一步优化显存。该
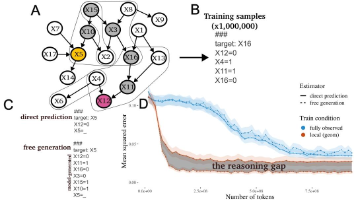
举个例子,假设训练数据中 A 与 C 的共现概率极低,那么模型在没有 CoT 的情况下,面对需要同时推断出 A 和 C 的情境时,表现往往不佳。但如果存在一个中间变量 B,且训练数据中 A 与 B、B 与 C 的共现概率都较高,CoT 就能引导模型先推理到 B,再由 B 推理到 C,从而成功实现 A 与 C 的关联。当训练数据由强相关变量形成的局部重叠集群时,模型可以通过串联这些局部推断,间接学习
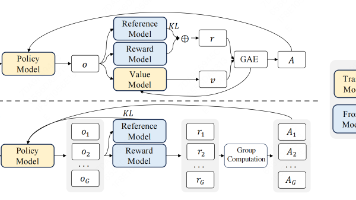
是强化学习中常用的一种策略优化方法,尤其在大模型训练中应用广泛。其核心思想是通过限制新旧策略之间的变化幅度,保证训练过程的稳定性。
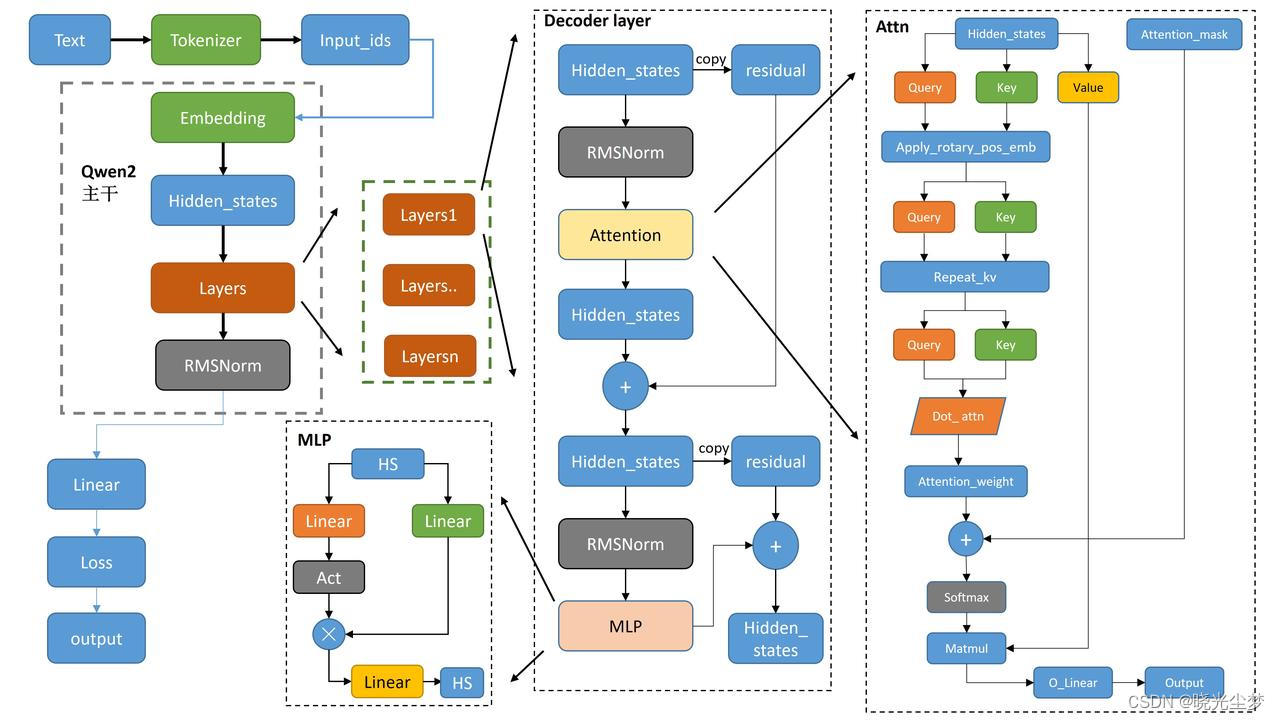
DeepSpeed是微软开发的深度学习优化库,专注于大模型训练加速。其核心技术包括:1) ZeRO优化器,通过分片优化器状态、梯度和参数,将内存需求降低至1/16;2) Sparse Attention,通过固定模式或动态稀疏化将注意力计算复杂度从O(n²)降至O(n),速度提升3-5倍;3) 1 bit Adam,通过梯度量化减少5倍通信量,训练速度提升3.4倍。这些技术显著提升了大规模模型训练