




- @oceancoco
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在前面的章节中,我们遇到过图像数据。这种数据的每个样本都由一个二维像素网格组成,每个像素可能是一个或者多个数值,取决于是黑白还是彩色图像。到目前为止,我们处理这类结构丰富的数据方式还不够有效。我们仅仅通过将数据展平成一维向量而忽略每个图象的空间结构信息,再将数据送入一个全连接的多层感知机中。因为这些网络特征元素的顺序是不变的,因此最优的结果是利用先验知识,即利用相近像素之间的互关联性,从图像数据中
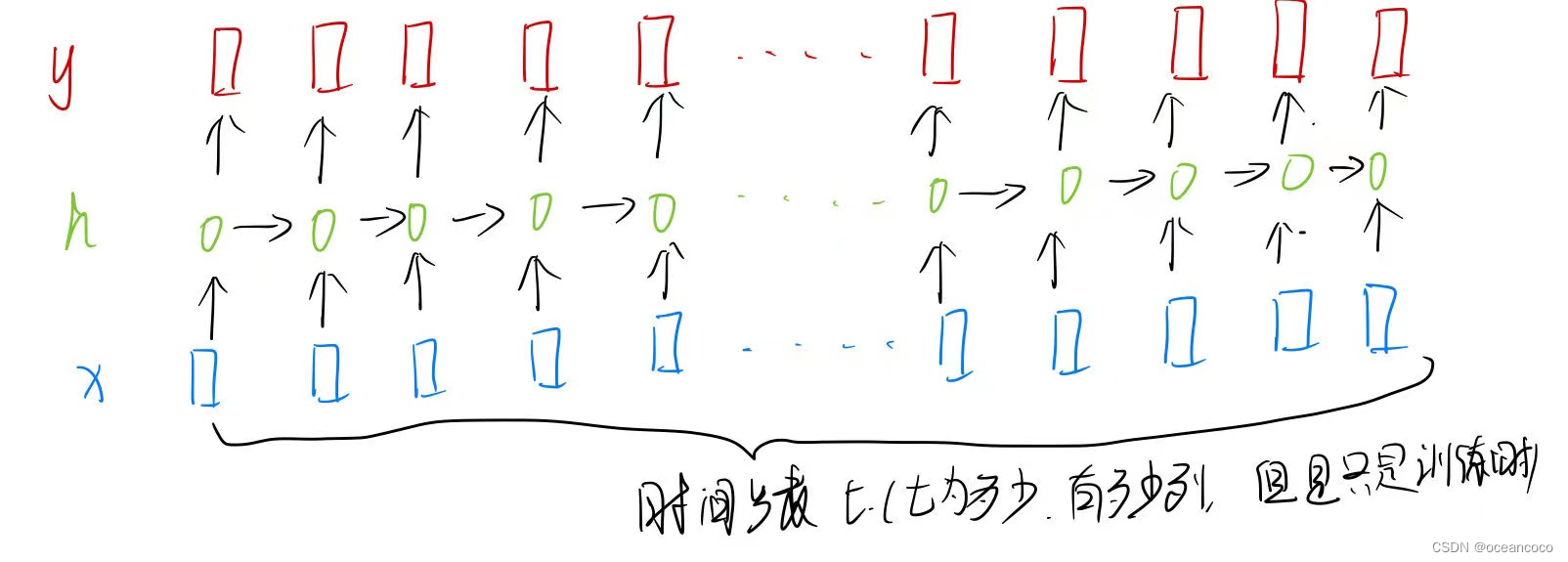
循环神经网络1. 序列模型1.1 马尔可夫模型假设已知τττ个序列预测下一个或下几个数据(假设当前数据只跟前τττ个数据有关)1.2 潜变量模型假设一个潜变量hhth_tht来表示过去信息ht=f(x1,x2,...,xt−1)h_t=f(x_1,x_2,...,x_{t-1})ht=f(x1,x2,...,xt−1)这样xt=p(xt∣ht)x_t=p(x_t|h_t)xt=p(xt
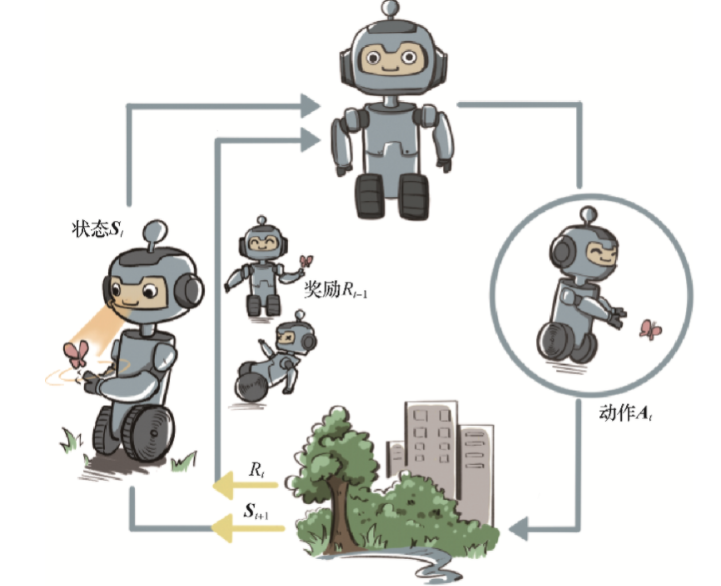
强化学习和python一起学,适用于有c++基础的同学哦!前半部分是代码和理论部分,后半部分是python函数
现代循环神经网络上一章节(循环神经网络)介绍了循环神经网络的基础知识,这种网络可以更好的处理序列数据。我们在文本数据上实现了基于循环神经网络的语言模型,但是对于当今各种各样的序列学习问题,这些技术可能不够用。例如,循环神经网络在实践中一个常见的问题是数值不稳定。尽管我们已经应用了梯度裁剪等技巧来缓解这个问题,但是仍需要通过设计更复杂的序列模型来进一步处理它。具体来说,可以引用两个广泛使用的网络,即
强化学习和python一起学,适用于有c++基础的同学哦!前半部分是代码和理论部分,后半部分是python函数
循环神经网络1. 序列模型1.1 马尔可夫模型假设已知τττ个序列预测下一个或下几个数据(假设当前数据只跟前τττ个数据有关)1.2 潜变量模型假设一个潜变量hhth_tht来表示过去信息ht=f(x1,x2,...,xt−1)h_t=f(x_1,x_2,...,x_{t-1})ht=f(x1,x2,...,xt−1)这样xt=p(xt∣ht)x_t=p(x_t|h_t)xt=p(xt
强化学习和python一起学,适用于有c++基础的同学哦!前半部分是代码和理论部分,后半部分是python函数
之前的章节提到过在线策略算法的采样效率比较低,我们通常更倾向于使用离线策略算法。然而,虽然DDPG是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018年,一个更加稳定的离线策略算法Soft Actor-Critic (SAC)被提出。SAC的前身是Soft Q-Learning,它们都属于最大熵强化学习的范畴。Soft Q-learning不存在
现代循环神经网络上一章节(循环神经网络)介绍了循环神经网络的基础知识,这种网络可以更好的处理序列数据。我们在文本数据上实现了基于循环神经网络的语言模型,但是对于当今各种各样的序列学习问题,这些技术可能不够用。例如,循环神经网络在实践中一个常见的问题是数值不稳定。尽管我们已经应用了梯度裁剪等技巧来缓解这个问题,但是仍需要通过设计更复杂的序列模型来进一步处理它。具体来说,可以引用两个广泛使用的网络,即
现代循环神经网络上一章节(循环神经网络)介绍了循环神经网络的基础知识,这种网络可以更好的处理序列数据。我们在文本数据上实现了基于循环神经网络的语言模型,但是对于当今各种各样的序列学习问题,这些技术可能不够用。例如,循环神经网络在实践中一个常见的问题是数值不稳定。尽管我们已经应用了梯度裁剪等技巧来缓解这个问题,但是仍需要通过设计更复杂的序列模型来进一步处理它。具体来说,可以引用两个广泛使用的网络,即