- @nyseo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
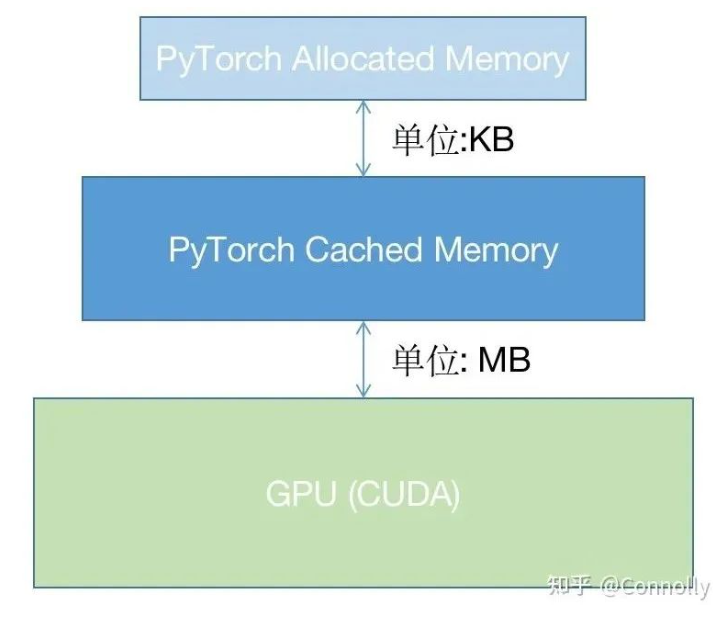
随着互联网和自媒体的繁荣,文本形式的在线旅游(Online Travel Agency,OTA)和游客的用户生成内容(User Generated Content,UGC)数据成为了解旅游市场现状的重要信息来源。OTA和UGC数据的内容较为分散和碎片化,要使用它们对某一特定旅游目的地进行研究时,迫切需要一种能够从文本中抽取相关的旅游要素,并挖掘要素之间的相关性和隐含的高层概念的可视化分析工具。为此
R-Drop:两次前向+KL loss约束Post Training: 在领域语料上用mlm进一步预训练EFL: 少样本下,把分类问题转为匹配问题,把输入构造为NSP任务形式.混合精度fp16: 加快训练速度,提高训练精度多卡ddp训练的时候,用到梯度累积时,可以使用no_sync减少不必要的梯度同步,加快速度对于验证集或者测试集特别大的情况,可以尝试多卡inference,需要用的就是dist.
R-Drop:两次前向+KL loss约束Post Training: 在领域语料上用mlm进一步预训练EFL: 少样本下,把分类问题转为匹配问题,把输入构造为NSP任务形式.混合精度fp16: 加快训练速度,提高训练精度多卡ddp训练的时候,用到梯度累积时,可以使用no_sync减少不必要的梯度同步,加快速度对于验证集或者测试集特别大的情况,可以尝试多卡inference,需要用的就是dist.
随着互联网和自媒体的繁荣,文本形式的在线旅游(Online Travel Agency,OTA)和游客的用户生成内容(User Generated Content,UGC)数据成为了解旅游市场现状的重要信息来源。OTA和UGC数据的内容较为分散和碎片化,要使用它们对某一特定旅游目的地进行研究时,迫切需要一种能够从文本中抽取相关的旅游要素,并挖掘要素之间的相关性和隐含的高层概念的可视化分析工具。为此
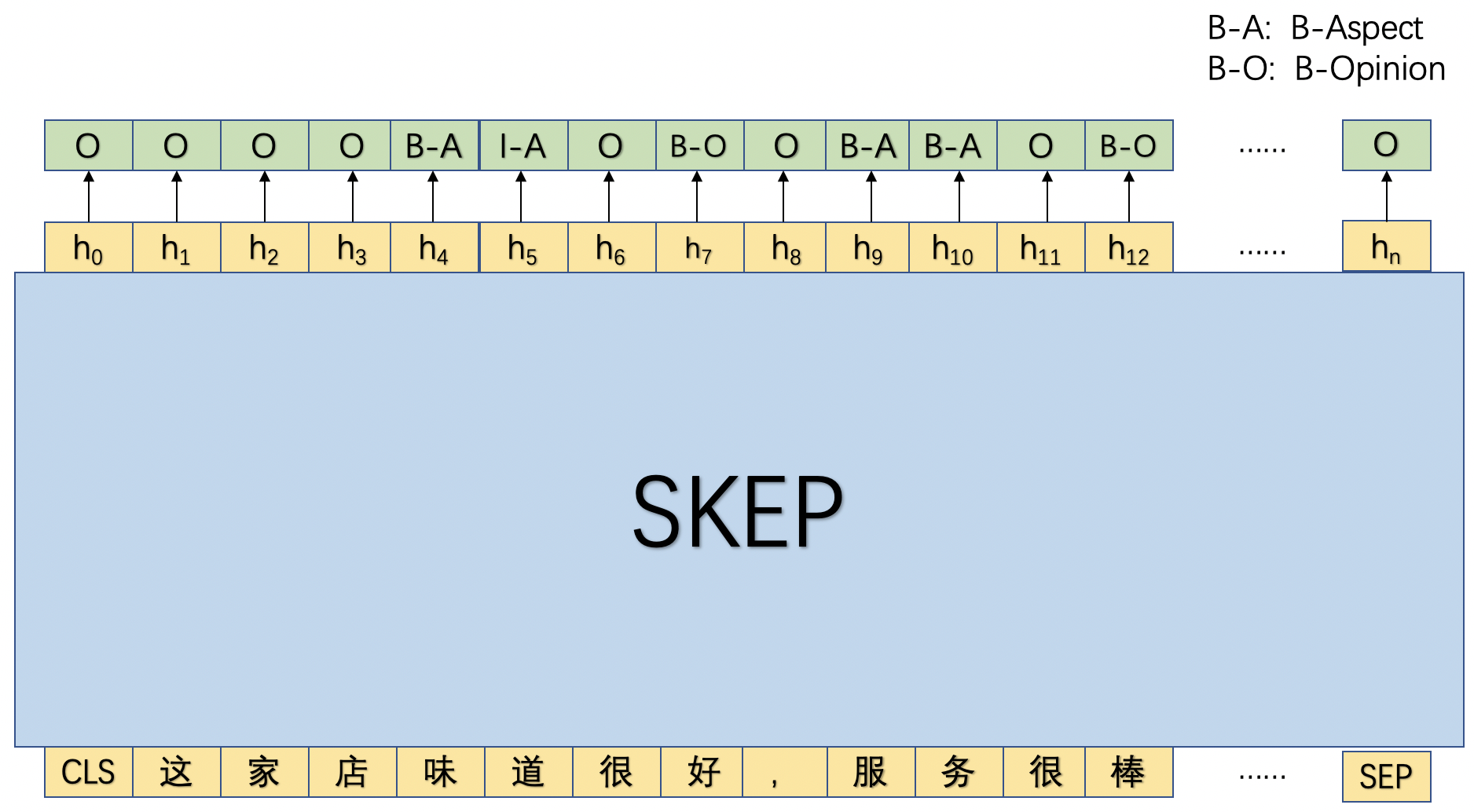
我从研一开始学习NLP自然语言处理,经常使用PyTorch框架。一开始用的时候对于PyTorch的显存机制也是一知半解,连蒙带猜的,经常来知乎上来找答案。经过两年的研究,现在回过头来看,能从大家的答案中找出不足的地方。但是两年过去了,也没有一篇很好的文章来总结PyTorch的显存机制的方方面面,那么我就吸收大家的看法,为PyTorch的显存机制做个小的总结吧。实验环境:OS: Window 11p