- @november_chopin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Buffer 类的实例类似于整数数组,但 Buffer 的大小是固定的、且在 V8 堆外分配物理内存。 Buffer 的大小在被创建时确定,且无法调整。Buffer 类在 Node.js 中是一个全局变量,因此无需使用 require('buffer').Buffer。Buffer有三种形式的构造方法:1、以字节为单位指定构造函数的参数new Buffer(size)被创建的B
程序主程序n8_routehtml.jsvar http = require('http');var url = require('url');var router = require('./models/router');http.createServer(function(request,response){if(request.
//导入一个http对象var http = require('http');//创建一个http服务器,参数request表示客户端向服务端发送的请求,response表示服务端向客户端的回应http.createServer(function(request,response){response.writeHead(200,{'Content-Type':'text/html;cha
上篇文章 强化学习 13 —— DDPG算法详解 中介绍了DDPG算法,本篇介绍TD3算法。TD3的全称为 Twin Delayed Deep Deterministic Policy Gradient(双延迟深度确定性策略)。可以看出,TD3就是DDPG算法的升级版,所以如果了解了DDPG,那么TD3算法自然不在话下。一、算法介绍TD3算法主要对DDPG做了三点改进,将会在下面 一一讲解,两者的

前面几篇文章价值函数近似、DQN算法、DQN改进算法DDQN和Dueling DQN我们学习了 DQN 算法以及其改进算法 DDQN 和 Dueling DQN 。他们都是对价值函数进行了近似表示,也就是 学习价值函数,然后从价值函数中提取策略,我们把这种方式叫做 Value Based。一、Value Based 的不足回顾我们的学习路径,我们从动态规划到蒙地卡罗,到TD到Qleaning再到D

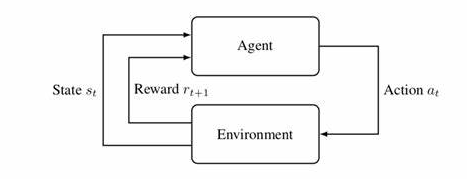
上篇文章强化学习——时序差分 (TD) 控制算法 Sarsa 和 Q-Learning我们主要介绍了 Sarsa 和 Q-Learning 两种时序差分控制算法,在这两种算法内部都要维护一张 Q 表格,对于小型的强化学习问题是非常灵活高效的。但是在状态和可选动作非常多的问题中,这张Q表格就变得异常巨大,甚至超出内存,而且查找效率极其低下,从而限制了时序差分的应用场景。近些年来,随着神经网络的兴起,

强化学习 — 马尔科夫决策过程(MDP)一、马尔科夫过程(Markov Process)马尔科夫性某一状态信息包含了所有相关的历史,只要当前状态可知,所有的历史信息都不再需要,当前状态就可以决定未来,则认为该状态具有马尔科夫性P(St+1∣St)=p(St+1∣S1,S2,⋯ ,St)P(S_{t+1}|S_t) = p(S_{t+1}|S_1, S_2, \cdots , S_t)P(St+1
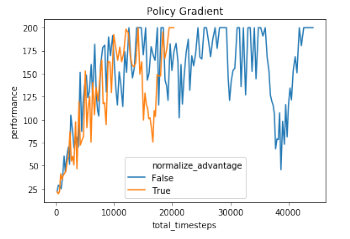
在Policy Gradient推导和REINFORCE算法两篇文章介绍了PG算法的推导和实现,本篇要介绍的算法是Proximal Policy Optimization (PPO),中文叫近短策略优化算法。PPO由于其非常的好的性能与易于实现等特性,已被作为OpenAI公司的首选算法,可见这个算法的优秀性能,具体可以查看OpenAI-PPO一、Policy Gradient 的不足采样效率低下:
上篇文章强化学习——详解 DQN 算法我们介绍了 DQN 算法,但是 DQN 还存在一些问题,本篇文章介绍针对 DQN 的问题的改进算法一、Double DQN 算法1、算法介绍DQN的问题有:目标 Q 值(Q Target )计算是否准确?全部通过 max Qmax\;QmaxQ 来计算有没有问题?很显然,是有问题的,这是因为Q-Learning 本身固有的缺陷—过估计过估计是指估计得值函数比

上篇文章介绍了强化学习——Actor-Critic算法详解加实战 介绍了Actor-Critic,本篇文章将介绍 DDPG 算法,DDPG 全称是 Deep Deterministic Policy Gradient(深度确定性策略梯度算法) 其中 PG 就是我们前面介绍了 Policy Gradient,在强化学习10——Policy Gradient 推导 已经讨论过,那什么是确定性策略梯度呢