




- @n9ecommunity
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 本文介绍了如何利用Prometheus监控Kubernetes集群。作为CNCF开源项目,Prometheus通过时间序列数据库存储指标,支持动态发现K8s服务,并可与Grafana集成实现可视化。文章重点讲解了使用kube-prometheus-stack Helm Chart一键部署完整监控栈(包括Prometheus、Node-Exporter、Grafana等组件),详细演示了安装步
Honeycomb 在 3 月的一篇文章里说得很直接:AI agent 并不看 dashboard,它会连续发起查询、形成假设、验证假设,因此它真正依赖的是数据模型、查询速度、完整性和成本。如果 AI Monitoring 跟 APM、Infra、RUM、Database、Security、Business Observability 还是割裂的,那它最多只是一个好看的专区。AI 事故很多时候根因
AI 排障新体验:自然语言一键诊断 本文介绍 catpaw chat 工具如何用自然语言交互简化系统排障。通过 12 个典型场景对比传统命令行与 AI 辅助方式,展示只需简单描述问题(如"CPU 高了"或"磁盘满了"),AI 就能自动调用 90+ 诊断工具分析,并给出结构化结论。关键优势包括: 无需记忆复杂命令组合 自动解析原始数据输出 支持多轮推理式排查
TargetsExportersPromQL让我们详细看看每个组件。这解释了 Prometheus 架构的主要组件,并将给出 Prometheus 配置的基本概述,您还可以使用配置做很多事情。每个组织的需求会有所不同,并且 Prometheus 在不同环境(例如 VM 和 Kubernetes)中的实现也有所不同。如果您了解基础知识和关键配置,您就可以轻松地在任何平台上落地它。本文翻译自这里。运维

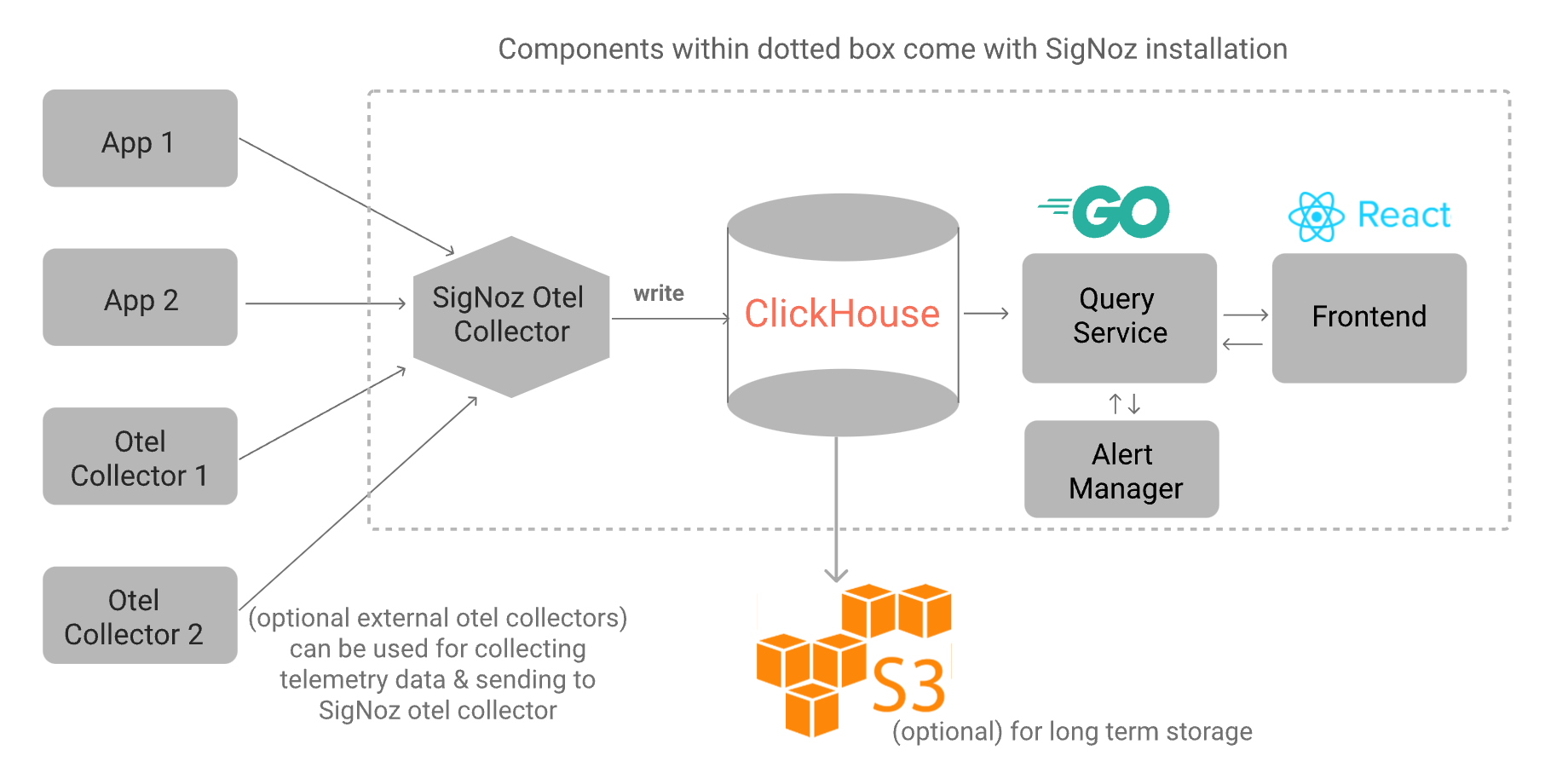
SigNoz是一个开源的应用性能监控工具,帮助您监控应用程序并解决问题。SigNoz使用分布式跟踪来获得对软件堆栈的可见性。点评:上面这个英文介绍是从其官网摘录的,从这个介绍中,我第一感受是SigNoz更侧重分布式链路追踪。监控应用程序指标,如延迟、每秒请求、错误率监控基础设施指标,比如CPU利用率或内存使用率在多个服务之间追踪用户请求在指标上设置警报通过转到出问题的trace来找到问题的根本原因
夜莺监控系统发布MCP Server,支持AI助手通过自然语言交互实现告警管理、监控等任务。该服务兼容Nightingale v8.0.0+,提供告警查询、主机监控、事件响应和团队协作等功能。用户需配置API Token并通过环境变量或配置文件集成MCP客户端,支持自定义工具集选择以优化性能。开源协议采用Apache 2.0,可与Nightingale等监控系统配合使用,实现智能化的运维管理。
Elastic Stack 在日志领域具备无与伦比的地位,各类新兴的开源项目都声称比 Elastic 更节省资源,同时检索速度也不慢,比如 ClickHouse、Loki、OpenObserve、VMLogs,今天我们来看看另一个项目:SigLens。
夜莺监控发布v8.beta14生产可用版本,建议升级,正式版将于7月4日夜莺大会推出。主要更新包括:新增Postgres告警支持,可对业务数据(如订单、商品)进行异常检测;告警事件Pipeline接入AI Summary功能,使用DeepSeek等模型自动生成告警总结;改进告警事件匿名访问机制,支持生成带过期时间的分享链接。升级注意事项:v6/v7版本可平滑升级,需备份关键文件,DB账号需有改表权
本文介绍了夜莺监控的设计思路,重点阐述其与时序库和采集器的对接逻辑。夜莺从V5版本开始专注告警引擎功能,放弃自研时序库,转而对接多种数据源。文章分析了PUSH/PULL两种数据采集模式的特点,并解释了开发Categraf采集器的原因:统一各类采集器的体验,满足企业用户需求。最后指出夜莺的核心是告警引擎,Categraf是可选项,但建议用于采集基础指标以获得更好体验。该设计体现了产品定位的精准性和架