




- @moxibingdao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
小红书 hi lab 推出的 dots.vlm1 多模态大模型以全链条自研和开源姿态,综合性能首次对标并逼近 Gemini 2.5 Pro、Seed-VL1.5 等闭源最强大模型,不仅在视觉-文本复杂场景中展现卓越,文本编码推理能力也保持主流水平。在文本任务(AIME、GPQA、LiveCodeBench 等)上,dots.vlm1 达到了与主流 LLM 相当的水准,具备通用数学推理和代码能力,但
在现实世界中,我们的视野范围是有限的,我们的眼睛在某一时刻只能聚焦于一个局部的场景。与此同时,基于当前以及历史的观测,我们也能感知自身的位置变化以及与之前见过的物体的位置关系(“我离那把椅子越来越远”,”棕色的枕头现在在我的右后方”)。OST-Bench 提出了一个在线的时空场景理解基准,通过对于多个多模态大模型的评估,揭示了当前模型在面对“在线时空理解”任务时的深层短板,也为未来模型的发展指明了

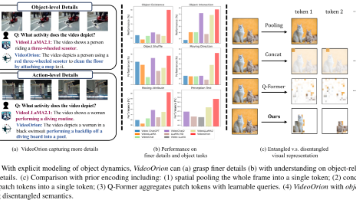
我们知道,现在的大模型看懂图片已经不是什么难事了,但要真正理解视频,尤其是视频里各种物体是怎么动的、互相之间有什么交互,其实还挺难的。与随机初始化的物体分支相比,经过预训练的分支能带来显著的性能改善,证明了预训练对于学习有效的物体表示是必不可少的。:这个分支负责“看全局”,它会处理视频的整体信息,比如背景、场景氛围等,生成“上下文Token”,给大模型一个关于视频的整体印象。一个令人振奋的发现是,
DeepSeek-R1 系列工作的成功表明基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)是—种行之有效的大模型后训练方法,能使预训练模型在不依赖大规模、高质量监督数据的情况下,快速习得高级能力或适配到特定场景。无论是Corvid的自我验证,还是CoRL的协同优化,都赋予了模型一种宝贵的“元认知”:与其盲目追求单—的
关注公众号,发现CV技术之美ICPR 2024是国际模式识别会议,由国际模式识别协会(The International Association for Pattern Recognition, IAPR)主办,ALPCORD NETWORK活动和会议管理公司(ALPCORD NETWORK event &conference management company, ALPCORD NET
关注公众号,发现CV技术之美近日,CVPR 2024 (IEEE Conference on Computer Vision and Pattern Recognition) IEEE国际计算机视觉与模式识别会议公布了论文录用结果。作为全球计算机视觉与模式识别领域的顶级会议,CVPR每年都吸引着全球众多研究者和企业的关注。入选CVPR的论文需要经过严格的评审流程,确保其创新性和实用性达到国际领先水
在计算机视觉领域,目标检测发展迅速,出现了基于机器视觉技术的表面缺陷检测技术。这种技术的出现,越来越多的制造企业正在尝试将机器视觉检测技术引入产品缺陷检测。目前基于机器视觉的缺陷检测技术已经大量应用于纺织品、汽车零部件、半导体、光伏组件等产品的缺陷检测中,大大提升了制造业的质检效率。机器视觉在工业缺陷检测中的前景毋庸置疑,而工业制造领域的多样性、生产环境的复杂性、产品缺陷...
关注公众号,发现CV技术之美2024年10月,华中科技大学白翔团队与华为研究人员合作,推出了基于国产芯片的多模态文档大模型PDF-WuKong。这一创新成果针对复杂多页PDF文档问答场景,提出了两项关键技术:端到端稀疏采样机制和多页PDF问答高质量数据生成方法。这些技术突破使得输入长度有限的多模态大模型能够有效处理理论上无限长的PDF文档,实现深度理解和精准问答。PDF-WuKong不仅解决了现有
关注公众号,发现CV技术之美ICPR 2024:The 2st Challenge on Moving Object Detection and Tracking in Satellite Videos第二届卫星视频运动目标检测与跟踪挑战赛(The 2st Challenge on Moving Object Detection and Tracking in Satellite Videos)将
点击我爱计算机视觉标星,更快获取CVML新技术无人机已经越来越走入人们的生产和生活,使用无人机进行新闻报道、城市管理、治理监控也成为社会发展重要新趋势。我在南京的报纸上就看到过南京市对拟...