- @microGP
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
报错信息:Caused by: java.lang.IllegalStateException: availableProcessors is already set to [8], rejecting [8]问题排查:原因是因为SpringBoot的netty和elasticsearch的netty相关jar冲突,导致程序抛出异常问题解决:在SpringBoot的入口类Application的m
环境信息:Hadoop 2.7.2+HBase 1.2.2现象:下午前端的同事使用scan查询HBase数据,代码执行到Table.getScanner(scan)方法时卡住了,无法返回结果直到超时,查看控制台,出现如下报错:java.lang.NoClassDefFoundError:org.apache.hadoop.hbase.util.ByteStringer问题分析:...
说到HBase数据压缩,在HBase中有两种方式可以达到该目的,一个就是column family的compress,HBase支持none/snappy/lzo/lz4/gz等几种压缩方式来压缩数据,最后降低数据总量的大小;另一个是data block 的encoding,通过对data block中的KeyValue中key的相同部分进行处理来减少存储的占用,目前支持prefix/diff/f
前言随着大数据和人工智能行业的发展与成熟,各个行业各种业务场景下OLAP(联机分析处理)的需求越来越强;人工智能中的NLP(自然语言识别)的发展为文本分析以及全文检索带上了一个新的台阶,在这种背景下,作为上述两种需求的集大成者的elasticsearch的应用越来越广泛,elasticsearch中存储的数据也越来越多,在elasticsearch给我们带来很多便利的同时也带来了很多问题:查询数据
环境信息:CentOS 6.5现象:同事启动程序发现端口被占用,netstat查看之后发现如下现象:发现端口处于FIN_WAIT1状态以及CLOSE_WAIT状态,无法释放问题分析:FIN_WAIT1以及CLOSE_WAIT状态的原理以及产生的原因大家自行baidu,下面就说下怎么解决上述问题,释放端口FIN_WAIT1:1、sysctl -a |grep tc...
原文链接:https://blog.csdn.net/AaronLau_love/article/details/72864963 左侧栏,我的计算机,选择需要克隆的虚拟机,右键,管理->克隆点击下一步,选择虚拟机中的当前状态(如果有快照也可选择快照,方法是右键虚拟机,快照->拍摄快照),下一步,选择创建完整克隆(克隆一份独立的系统出来,需要较大的系统空间),填写虚拟机
Search的面临的问题:elasticsearch从出现的那天起就为分布式而生,分布式是把双刃剑,分布式强大的可扩展性和高效的性能再给elasticsearch带来强大高效的处理能力的同时,也带来了分布式常规需要解决的问题,即数据都需要在各个节点或者实例分散计算(分布式典型的移动计算而非移动数据的思想),这种特点在某些场景下可能会带来一些相对麻烦的处理。elasticsearch的search分
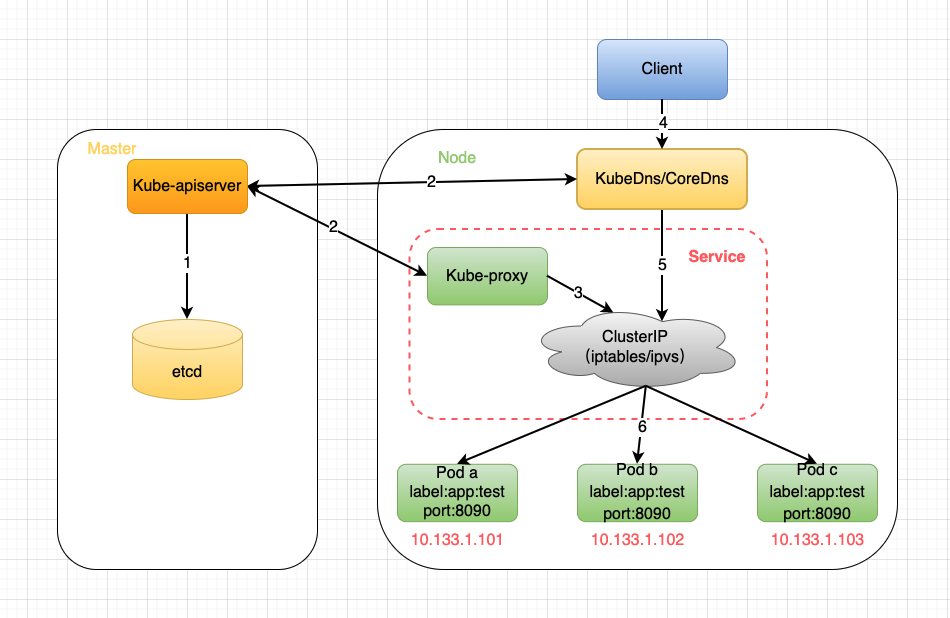
前言前面两个章节讲解了K8S的总体入门准备以及全局配置管理的相关内容,正常来说接下来应该将将存储或者组件,但是由于那两部分内容过多且相对偏重细节,所以这一篇先把K8S中的Service先讲解下,帮助大家先理清K8S的整体架构,后续再讲解细节内容的时候可以快速上手,便于理解。正文Service是什么?在说明Service是什么之前先了解下Service的使用场景:当客户端想要访问K8S集群中的pod