




- @magic_ll
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
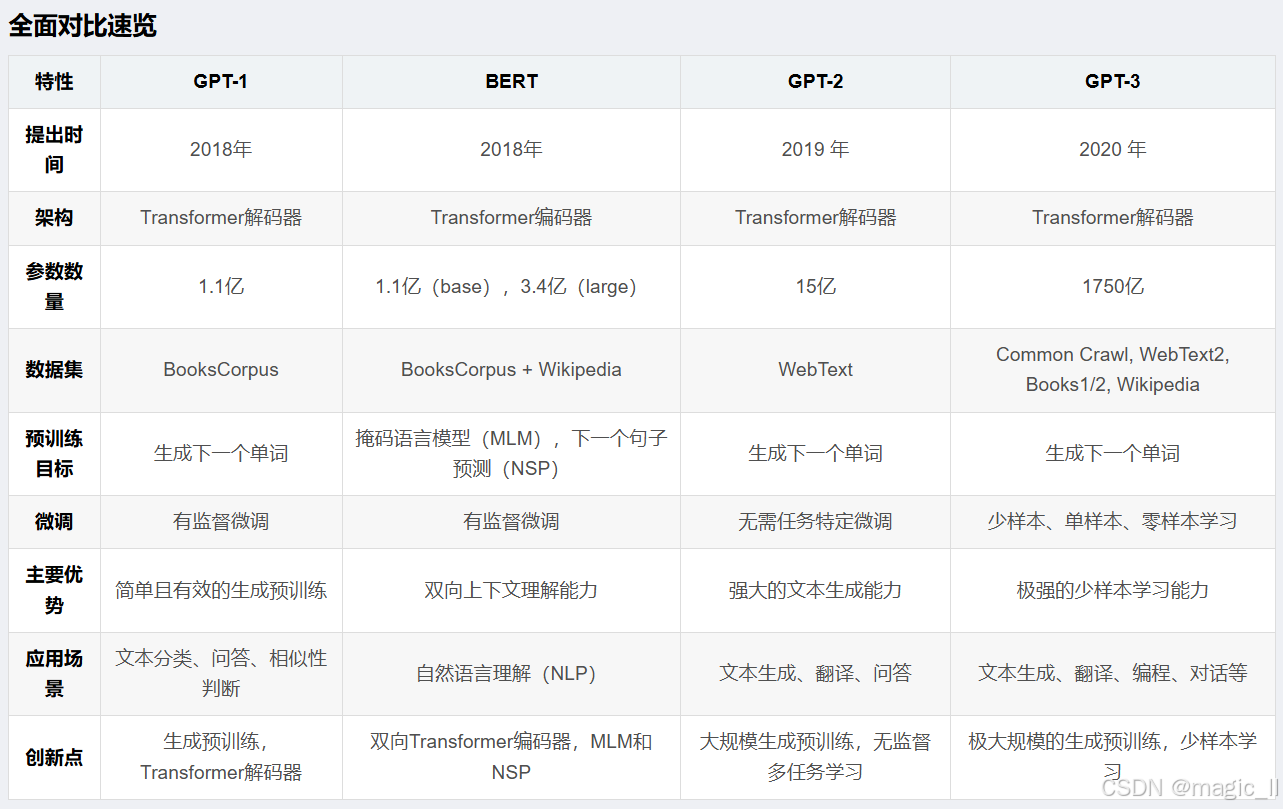
GPT-3尤其引人注目,展现了强大的语言理解和生成能力。GPT-3 论文展示了大规模语言模型在预训练和少样本学习方面的强大能力,通过增加模型规模和训练数据,显著提升了模型在各种 NLP 任务上的性能。GPT-2 的成功为后续的 GPT-3 和其他大型生成模型奠定了坚实的基础,并对未来的研究方向提供了宝贵的参考。在GPT-2中要做zero-shot,所以在做下游任务时模型不能够被调整,若此时引入模型
如果不进行有效管理,随着时间的推移,磁盘空间将被占满,最终导致服务器瘫痪。如果有更多的需求和疑问,直接deepseek一下,会得到更为详细的答案。该方案通过定时任务实现,既能保证数据的阶段性存储,又能避免因磁盘写满引发的服务中断。在设置定时任务时候,无论脚本还是Crontab 中的执行脚本,都需要是绝对路径。天的数据文件夹,自动删除更早的历史数据,确保磁盘空间合理利用。路径下的归档数据,保留最近
LoRA(低秩自适应)是一种高效的模型微调方法,其核心思想是利用低秩矩阵近似权重更新。它通过冻结预训练模型的主权重矩阵W,并引入两个低秩矩阵A(降维)和B(升维)作为旁路分支,学习任务特定的增量更新(ΔW=BA)。训练时仅优化A和B,大幅减少参数量(如仅需原参数的2%)。B初始化为零确保训练平稳开始,最终增量可合并回W实现无损推理。LoRA的设计借鉴残差思想,主路保留通用知识,旁路学习精细调整,实
本文分析了深度学习模型训练过程中的显存占用情况,重点介绍了ZeRO-3优化技术。在训练过程中,显存主要存储模型参数、梯度和优化器状态,其中优化器状态(如Adam优化器的动量、方差等)占用最大。采用混合精度训练时,还需额外存储FP32主参数副本,使得优化器状态总量可达模型参数量的3倍。动态部分包括与batch大小线性相关的激活值和临时梯度缓存。ZeRO-3技术通过将优化器状态、梯度和参数分区存储在多
若是填入的方式,一定注意名称的正确填写,可使用命令【ollama list】查看ollama下载的模型。:支持多种文档格式(如 Word、PDF、Excel、Markdown 等)的导入,自动完成文本预处理、向量化和问答分割,节省手动训练时间。OneAPI 是一个统一的接口管理与分发系统,旨在通过提供一个单一、统一的接口,简化对多个后端服务或数据源的访问。在下图中【语义检索】中,可以进一步勾选,这

本项目的最新版本中可使用 Xinference、Ollama 等框架接入 GLM-4-Chat、 Qwen2-Instruct、 Llama3 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。如果你只需要一个专注于 Python 项目的依赖管理和打包工具,希望获得更好的依赖解析能力和更简洁的工

截止到目前,目标检测的功能还是yolo模型落地性更强。但大模型也已经全面开花,所以也尝试下使用大模型来完成目标检测的训练,看看其效果如何,看看它在目标检测上有怎样的优势。本次选用qwen2.5-VL,(qwen2.5-VL的简单介绍)一开始使用github上阅读性强的工程训练,总觉得差些意思。于是决定自己手搓个大模型训练推理工程,emm…,预测效果也是差强人意。兜兜转转还是使用个高star的工程,
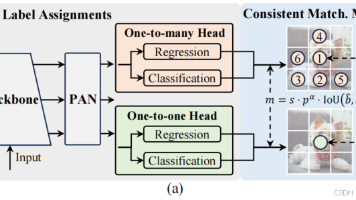
【与其他方法的对比讨论】先前的研究通过探索 不同标签分配方式 来加速训练收敛并提升网络性能。除了后处理环节,YOLO模型架构本身也给效率与精度的平衡带来了巨大挑战。模型架构存在不可忽视的计算冗余和能力局限,制约了其在实现高效性能方面的潜力。本文旨在从效率与精度双重视角,对YOLO模型架构进行整体性优化设计。 【效率驱动模型设计】YOLO的组件包括主干、下采样层、具有基本构建块的阶段以及头部。主干的
在vscode下面终端界面中,点击【PORTS】,保证里面的 【PORT】和【Forwarded Address】的端口号是相同的。本篇博客记录下自己在配置joyagent的过程,以【手动初始化环境,启动服务】为例,后端调用的deepseek-chat大模型。当确保上面的异常都排除完后,出现【“任务执行失败,请联系管理员”】,这个时候就要排查 MCP客户端是否能正常被调用。若端口被占用,清除对应的
1 深度学习的工作环境,一般流程安装好conda创建虚拟环境并且激活conda create -n pytorch python=3.6source activate pytorch.需要知道,使用conda命令安装库时,会安装其他的依赖库(或相关库),而且这些库也有默认的版本。所以在多个库相互兼容的情况下,想要安装指定版本的库,可以使用pip进行单独安装2 安装pytorch进入pytorch官