




- @m0_73825013
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何用Python爬取携程酒店评论并存入MySQL数据库的实战教程。主要内容包括:1) 环境准备(安装Python、MySQL及相关库);2) 通过开发者工具分析携程评论接口的请求方式和参数;3) 代码实现部分,详细展示了Spider类的初始化设置、请求头配置和数据库连接;4) 获取多页评论数据的方法,包括构造POST请求参数和JSON数据处理。教程强调需替换cookie等关键参数,并建
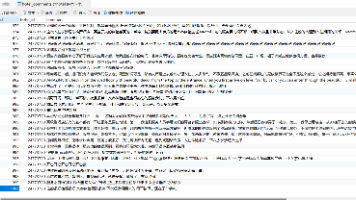
本文介绍使用Python库DrissionPage高效爬取携程酒店数据的方法。DrissionPage结合了Selenium的操作便利性和Requests的数据包捕获能力,无需下载驱动即可自动处理浏览器内核,并能直接拦截API接口返回的JSON数据。文章详细讲解了环境配置、核心思路和代码实现,包括模拟点击、监听网络请求、循环翻页等关键步骤。通过解析JSON数据而非HTML标签,大幅提升了爬取速度和
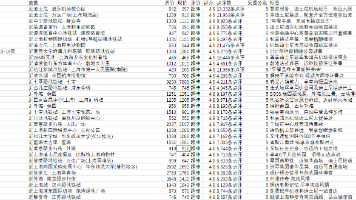
本文介绍如何用Python爬取携程网景点数据,以武汉市为例,获取景点名称、等级、评分等关键信息。通过分析携程JSON接口,设计面向对象的爬虫类,包含请求头生成、数据提取和CSV存储功能。代码使用Requests库发送POST请求,随机UserAgent防反爬,实现自动分页抓取和结构化存储。核心方法包括构建请求参数、解析JSON响应、处理异常情况等,最终输出包含11个字段的中文CSV文件。该方案比H
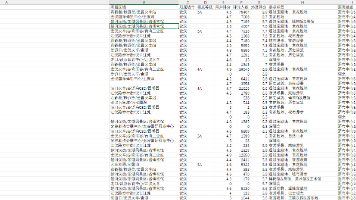
本文介绍了一个使用Python实现的东方财富网股票数据爬虫。该项目通过requests库发送HTTP请求,结合正则表达式解析返回的JSON数据,并将结果保存到Excel文件中。爬虫采用了随机User-Agent、请求延时等反爬措施,使用tqdm显示进度条提升用户体验。核心功能包括:获取分页股票数据、解析股票详细信息(代码、名称、价格、成交量等16个字段)以及数据存储。该项目完整展示了从网页请求到数
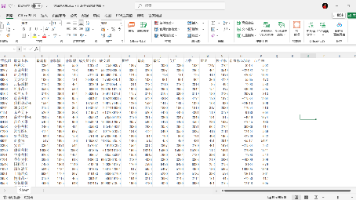
本文介绍了使用Python对骑行FIT文件数据进行解析、清洗与可视化的完整流程。通过fitparse库读取原始数据,转换为DataFrame后保存为CSV文件。利用matplotlib绘制了6个子图组成的综合可视化图表,包括海拔-距离、速度-距离、卡路里-距离等折线图以及速度-海拔散点图,全面展示骑行过程中的运动表现。文章提供了完整的代码实现,从数据读取、预处理到可视化配置,并解释了图表中反映的骑
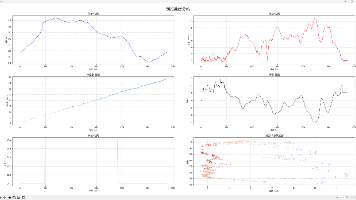
本文介绍了一个使用Python实现的东方财富网股票数据爬虫。该项目通过requests库发送HTTP请求,结合正则表达式解析返回的JSON数据,并将结果保存到Excel文件中。爬虫采用了随机User-Agent、请求延时等反爬措施,使用tqdm显示进度条提升用户体验。核心功能包括:获取分页股票数据、解析股票详细信息(代码、名称、价格、成交量等16个字段)以及数据存储。该项目完整展示了从网页请求到数
本内容详细的呈现了node.js的下载、安装和环境配置的教程
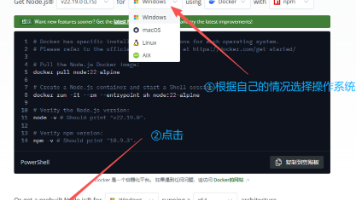
本文介绍了一个使用Python实现的东方财富网股票数据爬虫。该项目通过requests库发送HTTP请求,结合正则表达式解析返回的JSON数据,并将结果保存到Excel文件中。爬虫采用了随机User-Agent、请求延时等反爬措施,使用tqdm显示进度条提升用户体验。核心功能包括:获取分页股票数据、解析股票详细信息(代码、名称、价格、成交量等16个字段)以及数据存储。该项目完整展示了从网页请求到数