
手把手教你用Python爬取拉勾网招聘数据(附完整代码)
·
前言
大家好!今天给大家分享一个实用的Python爬虫案例——爬取拉勾网的招聘信息。虽然拉勾网有一定的反爬机制,但通过模拟浏览器请求和解析页面JSON数据,我们仍然可以获取到想要的招聘数据。
一、爬虫思路分析
1.1 目标网站
- 目标:拉勾网招聘信息
- 示例URL:
https://www.lagou.com/wn/jobs?kd=AIagent开发
1.2 技术要点
- 使用
requests发送HTTP请求 - 通过正则表达式提取页面中的JSON数据
- 使用
fake-useragent随机生成User-Agent - 利用Cookie模拟登录状态
- 将数据保存为CSV文件
1.3 反爬对策
拉勾网的招聘数据并不是通过Ajax异步加载,而是直接嵌入在HTML页面的 <script id="__NEXT_DATA__"> 标签中,这大大降低了爬取难度。
二、完整代码实现
import re
import csv
import requests
import json
from pprint import pprint
from fake_useragent import UserAgent
class LagouSpider:
def __init__(self, keyword='python'):
self.keyword = keyword
self.url = f'https://www.lagou.com/wn/jobs?cl=false&fromSearch=true&labelWords=sug&suginput={keyword}&kd={keyword}'
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'cookie': '',# 填写自己的cookie
'user-agent': UserAgent().random
}
def run(self):
response = requests.get(self.url, headers=self.headers)
html_data = re.findall(r'<script id="__NEXT_DATA__" type="application/json">(.*?)</script', response.text)[0]
json_data = json.loads(html_data)
with open(f'{self.keyword}_jobs.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=['职位', '公司', '城市', '区域', '薪资', '经验', '学历', '详情页'])
writer.writeheader()
for job in json_data['props']['pageProps']['initData']['content']['positionResult']['result']:
pprint(job)
data = {
'职位': job['positionName'],
'公司': job['companyFullName'],
'城市': job['city'],
'区域': job['district'],
'薪资': job['salary'],
'经验': job['workYear'],
'学历': job['education'],
'详情页': f"https://www.lagou.com/wn/jobs/{job['positionId']}.html"
}
print(data)
writer.writerow(data)
print(f'完成!共保存 {len(json_data["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"])} 条数据')
if __name__ == '__main__':
spider = LagouSpider(keyword='AIagent开发')
spider.run()
三、代码详解
3.1 类的初始化 __init__
keyword:搜索关键词,默认为’python’url:动态构建请求URLheaders:请求头,包含Cookie和随机User-Agent
注意:Cookie是有时效性的,如果运行时报错,需要登录拉勾网后从浏览器开发者工具中复制最新的Cookie。
3.2 核心方法 run
- 发送请求:使用requests.get()模拟浏览器访问
- 提取JSON:通过正则表达式提取
__NEXT_DATA__标签中的内容 - 解析数据:将JSON字符串转换为Python字典
- 保存CSV:遍历职位列表,提取需要的字段写入CSV文件
3.3 数据字段说明
| 字段 | 说明 | 示例 |
|---|---|---|
| 职位 | 岗位名称 | AIagent开发工程师 |
| 公司 | 公司全称 | 某某科技有限公司 |
| 城市 | 工作城市 | 北京 |
| 区域 | 工作区域 | 朝阳区 |
| 薪资 | 薪资范围 | 20k-40k |
| 经验 | 工作经验 | 3-5年 |
| 学历 | 学历要求 | 本科 |
| 详情页 | 职位详情链接 | https://www.lagou.com/wn/jobs/xxx.html |
四、运行结果
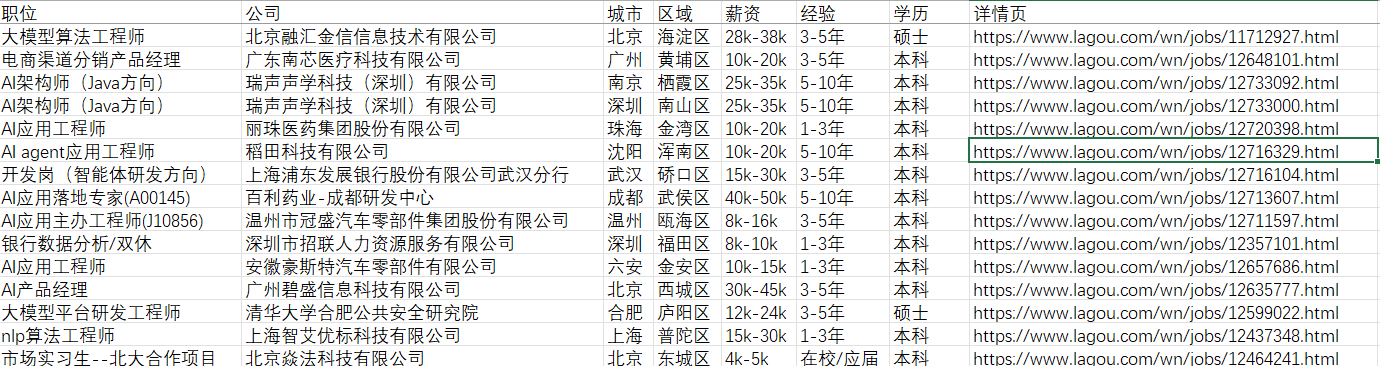
运行脚本后,会在当前目录生成一个AIagent开发_jobs.csv文件,内容如下:
五、注意事项
- Cookie时效性:文中的Cookie是示例数据,实际使用需要替换为你自己的Cookie
- 请求频率:不要频繁请求,建议加入time.sleep()避免IP被封
- 法律合规:请遵守robots.txt协议,仅用于个人学习研究
- 反爬升级:拉勾网可能会更新反爬策略,届时需要相应调整代码
六、扩展改进建议
- 多页爬取:目前只爬取了第一页,可以通过分析URL参数实现翻页
- 异常处理:增加try-except处理网络异常和解析异常
- 代理IP:爬取大量数据时建议使用代理IP池
- 数据存储:可以改为存储到MySQL或MongoDB
结语
以上就是爬取拉勾网招聘数据的完整教程。这个爬虫代码结构清晰,易于理解和修改,希望能帮助到正在学习爬虫的朋友们。
如果你觉得本文对你有帮助,欢迎点赞收藏!有问题也可以在评论区留言交流~
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)