
写文章




- @m0_69715013
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Kmeans聚类算法——Matlab
matlab实现Kmeans聚类算法+过程、结果可视化

四种常用的数据标准化方法
数据标准化的四种常用方法——“最小-最大标准化”、“Z分数标准化”、“小数定标标准化”和“总和归一标准化”。

主成分分析PCA——附MATLAB代码
主成分分析法(PCA)通过线性变换将原始的数据转化为一组各维度上线性不相关的表示,这些线性不相关的表示就称为"主成分"。

MATLAB——将RGB图像转换为灰度图、黑白图(imread、imshow、imwrite)
MATLAB——将RGB图像转换为灰度图、黑白图(imread、imshow、imwrite)示例

模型评估指标详解(分类、回归)
建模常用的分类、回归模型评估指标。

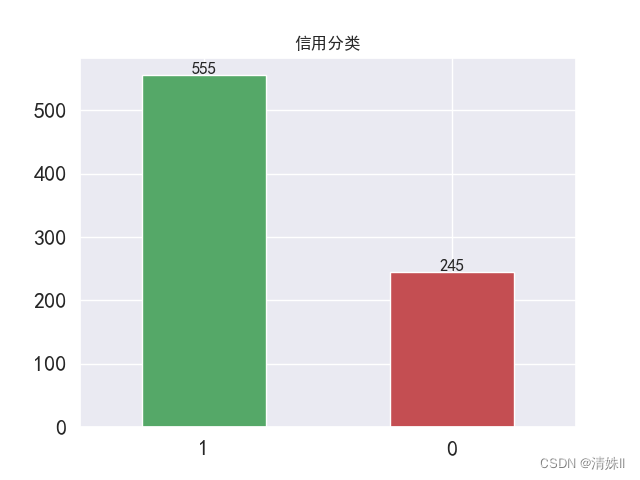
Python——样本类别不均衡问题+代码(基于imblearn包)
利用Python的imblearn库解决类别不均衡问题过采样:SMOTE,ADASYN欠采样:RandomUnderSampler,ClusterCentroids,NearMiss
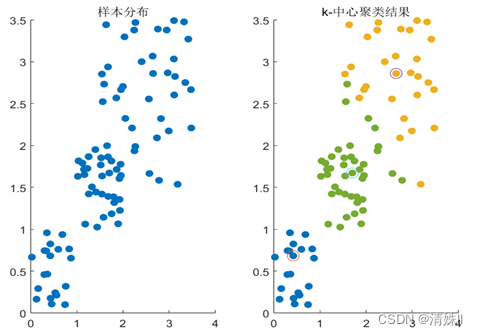
k-中心聚类(k-medoids)算法——附MATLAB代码
k-medoids聚类是一种无监督的聚类算法,它对未标记数据中的对象进行聚类
到底了