




- @m0_61676839
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
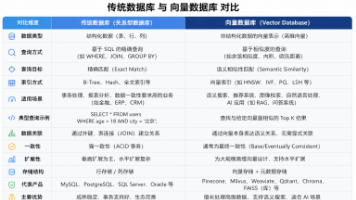
在数据技术不断演进的今天,传统数据库已经无法完全满足人工智能时代的需求。尤其是在大模型(LLM)和语义搜索兴起之后,一类新的数据库——向量数据库,逐渐成为热门选择。那么,经典的 MySQL 与向量数据库到底有什么本质区别?它们是否会相互取代?
CoT 让模型“会解释”,ToT 让模型“会探索”,GoT 让模型“会思考”。

👉 重点:你给模型加了额外上下文(RAG / memory / docs)👉 重点:不只是一次调用,而是一个流程(带搜索 + 校验 + 兜底)👉 重点:你写了什么 prompt。

的作用是在不牺牲模型精度的前提下,让注意力机制(Attention Mechanism)跑得更快、更省内存。核心痛点:传统 Attention 需要生成巨大的N×NN \times NN×N矩阵,导致 GPU 显存频繁在“慢速大内存 (HBM)”与“快速小内存 (SRAM)”间搬运数据。GPU 算力极强,但因为忙着搬数据,大部分时间在“空转”。核心方案将矩阵切成小块,在高速 SRAM 中完成计算,
IEMOCAP:包含演员表演的剧本对话,情感标签包括快乐、愤怒、中性、悲伤、兴奋和沮丧。MELD:源自美剧《老友记》的多方对话数据集,包含中性、惊喜、恐惧、悲伤、快乐、厌恶和愤怒等标签。模态组成:每个对话切片(Utterance)均包含文本(Textual)音频(Acoustic)和视觉(Visual)三种特征。
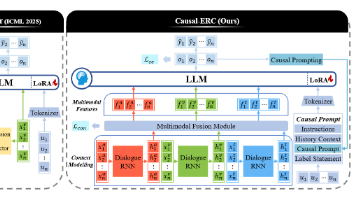
IEMOCAP:包含演员表演的剧本对话,情感标签包括快乐、愤怒、中性、悲伤、兴奋和沮丧。MELD:源自美剧《老友记》的多方对话数据集,包含中性、惊喜、恐惧、悲伤、快乐、厌恶和愤怒等标签。模态组成:每个对话切片(Utterance)均包含文本(Textual)音频(Acoustic)和视觉(Visual)三种特征。
由于 EmojiGrid 的图像是由表情符号(Emoji)组成的,这些符号具有“超越语言”的通用性(例如,全世界的人都能看懂“😢”代表悲伤)。:设计上兼顾了各类任务的比例,防止模型通过过拟合某种任务来刷分。例如感知类占40.43%,关系类占32.12%,抽象类占27.44%。最近的视觉语言模型(如 Gemini 2.5 Pro, GPT-o1/o4-mini, GLM-4V-Thinking)都
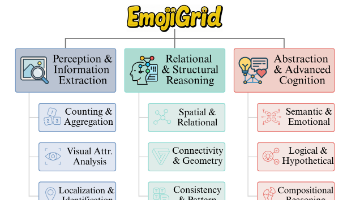
由于 EmojiGrid 的图像是由表情符号(Emoji)组成的,这些符号具有“超越语言”的通用性(例如,全世界的人都能看懂“😢”代表悲伤)。:设计上兼顾了各类任务的比例,防止模型通过过拟合某种任务来刷分。例如感知类占40.43%,关系类占32.12%,抽象类占27.44%。最近的视觉语言模型(如 Gemini 2.5 Pro, GPT-o1/o4-mini, GLM-4V-Thinking)都
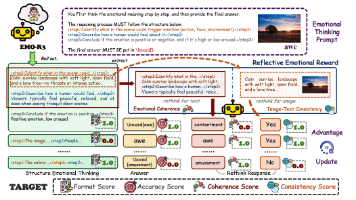
本文提出EMO-R3框架,通过结构化情感思维(SET)和反射情感奖励(RER)增强多模态大语言模型的情感推理能力。SET引导模型分三阶段推理:情感触发点识别、人类情感反射和情感结论;RER则通过图文一致性和情感连贯性奖励实现自我评估。实验表明,该方法在EmoSet等数据集上优于现有技术,消融研究验证了各模块的有效性。主要贡献包括:1)结构化情感推理过程;2)反射式自我评估机制;3)在多个基准测试中
在当今信息爆炸的时代,数据的价值日益凸显。爬虫技术作为一种自动化获取网络信息的手段,已经成为数据科学、市场分析、学术研究等领域不可或缺的工具。本文对于证监会行政处罚内容进行爬取并输出到excel中。
