




- @luluxiake_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
阶段模块关键操作结果输入层Embedding + 位置编码文本 → 向量含顺序信息的词向量Encoder多头自注意力 + 前馈网络捕捉输入全局关系输入语义特征DecoderMasked 注意力 + Encoder-Decoder 注意力结合输入与上下文生成输出序列输出层转为词概率分布输出结果Transformer 是一种“全局思考、并行计算”的神经网络,它用注意力机制取代循环,使模型能高效理解和生
从大模型匹配信息表中提取第一阶段已经完成的数据,分批次进行提取特征,包含床型,等级,景观。为了提高准确性,判断的逻辑完全在代码层面进行,大模型只做提取特征工作。大模型在语义理解上确实有优势,但直接把“是否匹配”的判断交给模型,结果往往不可控,也不适合高频、批量的线上业务。保证调用大模型匹配前,使用系统相似度进行预先匹配,过滤出高度相似房型。3. 大模型返回结果后,将匹配本地房型的相关信息(id、匹
本文介绍了通过Docker在本地部署Xinference服务的完整流程。首先确保已安装Docker Desktop和Dify环境,然后通过指定挂载目录、环境变量和端口映射等参数启动容器。启动成功后可通过浏览器访问服务,并详细说明了如何集成ChatTTS语音合成模型和SenseVoice-Small语音理解模型,构建完整的语音交互系统,最后在Dify平台中进行相关配置和应用创建。
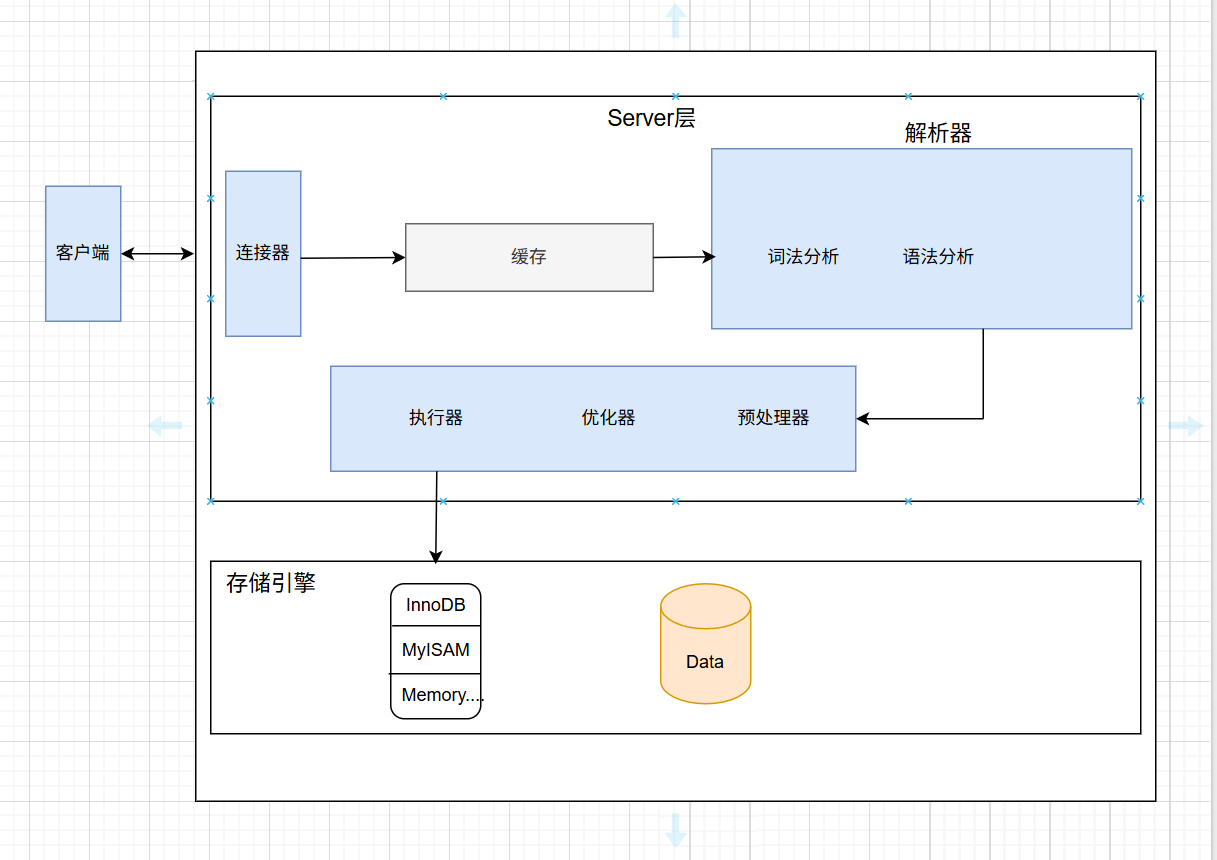
MySQL内部结构分为Server层和存储引擎层。Server层包含连接器(管理连接和权限)、解析器(词法语法分析)、优化器(生成执行计划)和执行器等组件,其中查询缓存在MySQL 8.0被移除。存储引擎层以InnoDB为例,使用聚簇索引存储数据。EXPLAIN执行计划分析显示:id表示查询顺序,select_type标明查询类型(SIMPLE/PRIMARY/DERIVED等),type反映访问
k > 2,那么此时需要思考其中跨越的子数组是否可以推广到第k个arr。然而本题的关键在于数组串联,那么我们就不应该局限与原始数组arr。红线代表两个数组间的子数组,为正,绿线即负数组。若k=1,按照常思路即可。若依次合并后更大,则更新。
