- @lovebyz
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
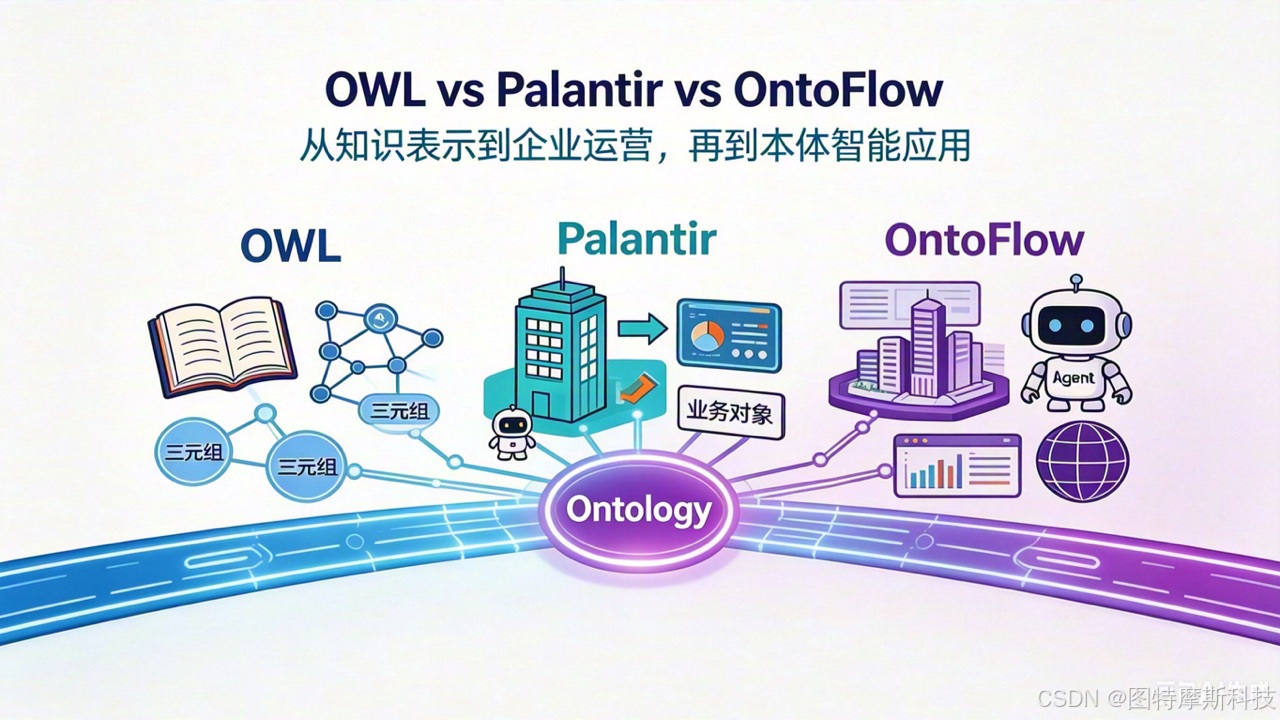
本文探讨了企业知识工程中本体论的三种落地路径:1)中台+Neo4j模式,将本体作为知识资产存储,适合查询分析但执行需额外适配层;2)Agent+Action模式,通过大模型动态调用知识能力,灵活性高但本体约束易弱化;3)本体原生路线(如OntoFlow平台),创新性地将本体作为系统运行时主体,使认知结构直接驱动业务执行。作者认为第三种方案虽实现难度大,但通过整合数据模型、工作流和AI交互,可能代表
除了本体建模能力外,还天然集成数据接入、计算引擎、权限治理、工作流调度、AI 集成、可视化应用开发等全链路工程能力,是可以直接落地商业业务的完整系统。专为本体建模、语义计算、时序状态演化设计的底层数据库,统一存储实体、关系、属性、规则、时序数据,为所有上层应用提供稳定、统一的数据支撑。基于统一本体模型,快速生成可交互的数字孪生大屏、态势监控、业务看板、设备可视化系统,解决传统大屏「只能看、不能用、
除了本体建模能力外,还天然集成数据接入、计算引擎、权限治理、工作流调度、AI 集成、可视化应用开发等全链路工程能力,是可以直接落地商业业务的完整系统。专为本体建模、语义计算、时序状态演化设计的底层数据库,统一存储实体、关系、属性、规则、时序数据,为所有上层应用提供稳定、统一的数据支撑。基于统一本体模型,快速生成可交互的数字孪生大屏、态势监控、业务看板、设备可视化系统,解决传统大屏「只能看、不能用、
除了本体建模能力外,还天然集成数据接入、计算引擎、权限治理、工作流调度、AI 集成、可视化应用开发等全链路工程能力,是可以直接落地商业业务的完整系统。专为本体建模、语义计算、时序状态演化设计的底层数据库,统一存储实体、关系、属性、规则、时序数据,为所有上层应用提供稳定、统一的数据支撑。基于统一本体模型,快速生成可交互的数字孪生大屏、态势监控、业务看板、设备可视化系统,解决传统大屏「只能看、不能用、
OntoFlow是基于自研本体数据库AbutionGraph打造的国产本体智能平台。解决了大模型落地中“有数据无语义”的痛点。平台支持结构化与非结构化双源数据融合,通过可视化、标准化工作流实现从数据集成到知识服务化的全链路闭环,具备轻量化、国产化及工程化优势,是企业级AI落地的核心语义底座。
## 局部特征检测方法斑点 Blob检测,LoG检测 , DoG,DoH检测,SIFT算法,SUFT算法边缘检测 梯度边缘检测算子,拉普拉斯算子,LoG检测 ,Canny边缘检测算子,Roberts,Sobel,Prewitt,角点检测 Kitchen-Rosenfeld,Harris角点,多尺度Harris角点,KLT,SUSAN检测算子,Shi-Tomasi将基于主分量分析和Fisher线性鉴
面向大规模实时数据分析的HOLAP知识图谱数据仓库AbutionGraph与传统的OLTP图库有什么不同?我们将对OLAP图库的应用场景、面向的客户、实现原理、未来发展做出对比分析。
标签: 关键点检测、提取局部特征描述符1、图像描述符、特征描述符和特征向量的定义特征向量:用于表示和量化图像的数字列表,简单理解成将图片转化为一个数字列表表示。特征向量中用来描述图片的各种属性的向量称为特征矢量。图像描述符:理解成一种算法和方法,控制整个图像如何转变为特征向量。量化是的图像形状,颜色,纹理,或三者的任何组合。输入1个图像时,图像描述符将返回1个特征向量。主要用于图像分类...
探讨企业数字化转型中"本体模型"的核心挑战已从数据存储转向如何让数据持续服务业务,而本体模型通过构建稳定的语义框架,能够识别业务核心对象及其关系,实现数据可追踪、可推理。作者分析了Palantir Ontology:必须与数据实体关联、包含动态执行元素、直接支撑业务决策。并介绍了OntoFlow平台如何实现本体从建模到执行的完整链路,通过多智能体协作将哲学层面的本体论转化为可落地的让"数据+模型"
还在为找数据、写 SQL 头疼?OntoFlow 本体建模平台的元数据探查功能来了!本文拆解其核心能力:兼容全品类数据源、可视化盘点数据资产,更能用自然语言直接 “问数”,同时结合元数据管理引擎与 Palantir 前沿实践,看它如何打通数据到知识的链路,让企业数据真正 “活” 起来。