




- @liwenxiang629
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
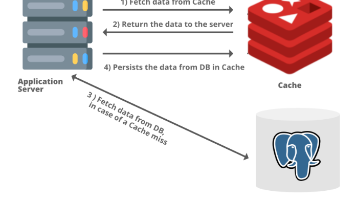
本文通过淘宝购物流程案例,深入解析了工业级系统设计中缓存与数据库的选择策略。核心观点为:缓存(如Redis)适用于高频读取、允许短暂不一致的场景(如商品展示),而关系型数据库(如PolarDB)则用于存储必须强一致的核心业务数据(如订单、支付)。文章详细拆解了从浏览到支付的各个环节数据存储策略,强调库存"预扣-确权"双写、订单事务完整性等关键设计,并对比了强一致与最终一致的适用
摘要:深度求索发布DeepSeek-V3.1,创新采用UE8M0FP8参数精度技术。该技术通过无符号8位指数格式,将浮点乘法简化为整数加法,大幅提升国产AI芯片计算效率(降低75%内存占用),实现"软件定义硬件"的突破。其核心优势包括:1)动态范围覆盖76个数量级;2)适配国产芯片架构特性;3)显著提升分布式训练效率。此举不仅推动国产大模型发展,更促进国产AI芯片生态协同创新,

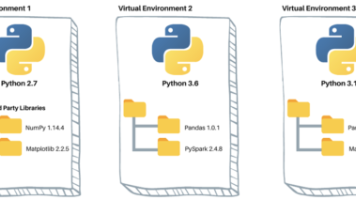
文章摘要: Python开发中管理多版本环境的4种主流方案:1) pyenv-win适合频繁切换Python版本,通过路径劫持实现隔离;2) Anaconda/Miniconda适合复杂依赖管理,支持跨语言环境隔离;3) 原生venv模块适合同一Python版本下的多项目依赖隔离;4) 手动环境变量配置适合高级调试。最佳实践推荐根据项目需求组合使用(如pyenv-win+venv),避免直接修改系
摘要:本文系统介绍了Prompt Engineering的核心技术,重点解析了Few-shot Prompting和Chain-of-Thought(CoT)两大方法。Few-shot通过提供示例样本指导模型输出特定格式或风格,而CoT则通过分步推理解决复杂逻辑问题。文章提出四层级的Prompt设计框架:基础指令、上下文增强、思维工程和外部工具调用,并建议测试人员采用边界值测试、等价类划分等软件测

摘要:本文介绍了在VSCode中使用Python虚拟环境的最佳实践。建议每个项目创建独立虚拟环境(.venv),并通过.vscode/settings.json配置项目专属解释器路径。详细说明了虚拟环境创建、激活、依赖安装的步骤,以及如何在VSCode中选择解释器。文章还提供了多项目管理模板、常见问题解决方案,并强调使用相对路径、版本说明等团队协作技巧。核心推荐包括:项目独立虚拟环境、.venv命

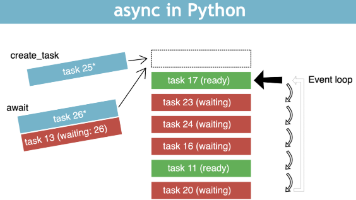
最近研究了一下python 协程(Coroutine)相关的东东,为了搞清本质,又总结了fd、select、poll、epoll这些linux中比较底层的技术,在这里通过一个开快递驿站通俗的例子把这些知识点串联到一起跟大家一起分享!
ChromaDB是一个多语言混合开发的项目,采用分层架构设计。其核心引擎使用Go语言编写,负责高性能的向量索引和相似性搜索;Python客户端则提供友好的API接口。通过pip安装时,不仅会安装Python代码,还会自动捆绑Go核心二进制文件和SQLite数据库,实现开箱即用的嵌入式体验。ChromaDB支持两种使用模式:嵌入式模式适合本地开发,客户端/服务器模式适用于生产环境。这种设计巧妙地将高
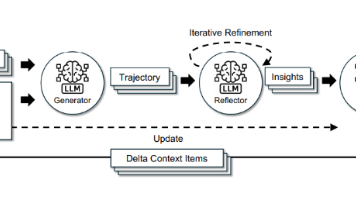
斯坦福大学等机构的研究团队提出Agentic Context Engineering(ACE)框架,通过动态优化上下文而非微调模型参数来提升大语言模型性能。ACE采用"生成器-反思器-整理器"三角色循环机制,以结构化增量方式更新上下文,有效解决传统方法中的信息丢失问题。相比微调,ACE具有成本低、效率高(延迟降低86.9%)、可解释性强等优势。研究者认为ACE与微调是互补关系:
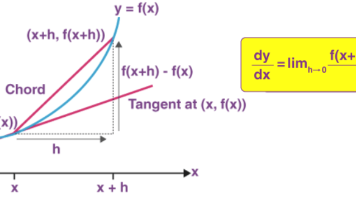
导数和偏导数是微积分的核心概念,分别描述单变量和多变量函数的变化率。导数表示函数在某点的切线斜率,偏导数则反映多变量函数对某一变量的变化率(其他变量固定)。在机器学习中,它们构成了梯度下降和反向传播算法的基础,通过计算损失函数对参数的偏导数来优化模型。导数和偏导数不仅具有几何意义(切线斜率),还能描述物理量的变化率,是深度学习模型训练的关键数学工具。
Midscene是一款开源AI自动化工具,通过自然语言指令实现Web和移动端操作。它采用视觉识别技术定位元素,无需依赖传统代码或固定选择器,大幅降低自动化门槛。核心功能包括自然语言驱动、视觉定位、多平台支持和智能任务规划,适用于测试、RPA和办公自动化等场景。由阿里AIDC团队维护,免费开源但需调用大模型API(推荐Qwen-VL或GPT-4o)。相比传统工具,Midscene在UI频繁变更场景中
