- @littlely_ll
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LogisticRegressionclass pyspark.ml.classification.LogisticRegression(self, featuresCol="features", labelCol="label", predictionCol="prediction", maxIter=100, regParam=0.0, elasticNetParam=0.0, tol=1e-

依存句法分析是自然语言处理中一个关键的问题,一是判断给定的句子是否合乎语法,再是为合乎语法的句子给出句法结构。为了准确做出句子的依存关系,不少学者提出了一些方法,如基于图的方法,基于转换的方法等。基于转换的依存句法分析Yamada和Matsumoto提出了使用SVM来训练基于转换的依存分析算法。他们根据三种分析行为(shift, right, left)对输入的句子进行从左到右顺序构建

5. 模型训练和调参内容:Model Training and Parameter TuningAn ExampleBasic Parameter TuningNotes on ReproducibilityCustomizing the Tuning ProcessPre-Processing OptionsAlternate Tuning Grid

LogisticRegressionclass pyspark.ml.classification.LogisticRegression(self, featuresCol="features", labelCol="label", predictionCol="prediction", maxIter=100, regParam=0.0, elasticNetParam=0.0, tol=1e-
神经网络机器翻译(Neural Machine Translation, NMT)是最近几年提出来的一种机器翻译方法。相比于传统的统计机器翻译(SMT)而言,NMT能够训练一张能够从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。NMT其实是一个encoder-decoder系统,encoder把源语言序列进行编码,并提取源语言中信
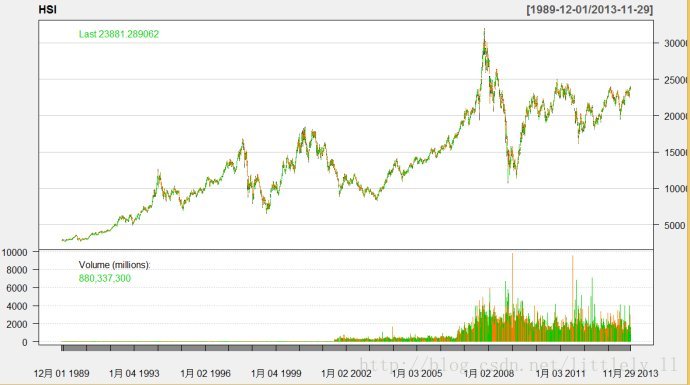
read datalibrary(quantmod)# 加载包getSymbols('^HSI', from='1989-12-01',to='2013-11-30')# 从Yahoo网站下载恒生指数日价格数据dim(HSI)# 数据规模names(HSI)# 数据变量名称chartSeries(HSI,theme='white')# 画出价格与交易的时...
LogisticRegressionclass pyspark.ml.classification.LogisticRegression(self, featuresCol="features", labelCol="label", predictionCol="prediction", maxIter=100, regParam=0.0, elasticNetParam=0.0, tol=1e-
词向量词向量,顾名思义,就是把一个单词或词语表示成一个向量的形式,这是因为在计算机中无法直接处理自然语言,需要把它转化为机器能够理解的语言,比如数值等。最简单的方式是把一个个单词表示成one-hot的形式。例如有三个句子:我/喜欢/小狗/喜欢/喝咖啡我/不喜欢/喝咖啡你/喜欢/什么/东西词汇表为:我、你、喜欢、不喜欢、小狗、喝咖啡、什么、东西然后对每一个词做one-hot编码:“我”就是[1

k-prototypes聚类前一篇讲述了K-Prototypes聚类的原理以及它的伪代码,本篇根据上一篇内容编写了实现K-Prototypes的Python代码。# -*- coding: utf-8 -*-import numpy as npimport randomfrom collections import Counterdef dist(x, y):retu...
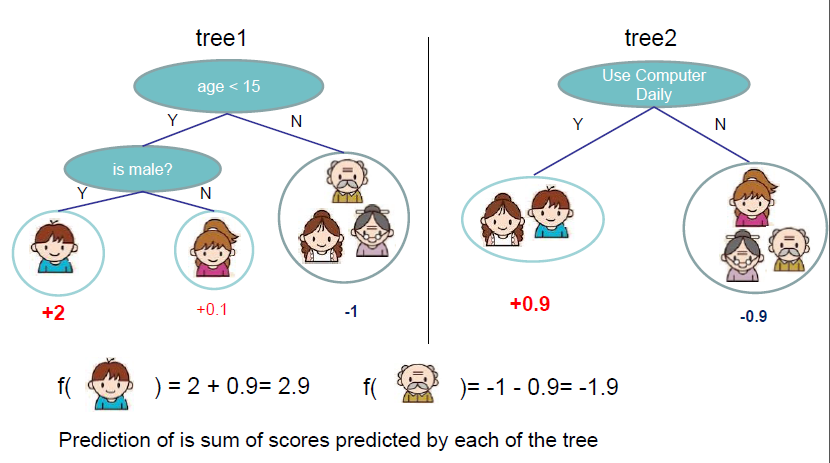
目标函数Obj(θ)=L(θ)+Ω(θ)Obj(\theta)=L(\theta)+\Omega(\theta)其中,L(θ)L(\theta)表示模型拟合训练数据的程度,Ω(θ)\Omega(\theta)是正则化项,用来表示模型的复杂程度。一般,训练集的损失函数记为:L=Σni=1l(yi,yi^)L=\Sigma_{i=1}^nl(y_i,\hat{y_i})- 平方损失函数:l(