




- @lipku
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LiveTalking 2.0正式发布,带来重大架构升级:1)采用插件化系统,支持灵活接入各类AI引擎;2)重构代码结构,通过BaseAvatar等基类减少重复代码;3)优化流媒体传输,新增RTMP支持;4)新增阿里云QwenTTS语音引擎。此次升级显著提升了扩展性和开发便利性,使项目向标准化数字人框架迈进。开发者可通过GitHub获取最新代码并参与社区交流。
LiveTalking 近期完成 TTS 引擎升级,引入 vLLM-Omni 作为统一推理框架,在 RTX 3090 上实现 130ms 首包延迟和 13GB 显存占用的流式语音合成。新架构通过 OmniTTS 适配器整合多模型支持,采用开放式 API 设计,并配套开发了零依赖的 Web 管理界面,支持语音克隆与实时测试。该方案解决了离线部署与多后端碎片化问题,统一了 Qwen、Fish Spee
LiveTalking 近期完成 TTS 引擎升级,引入 vLLM-Omni 作为统一推理框架,在 RTX 3090 上实现 130ms 首包延迟和 13GB 显存占用的流式语音合成。新架构通过 OmniTTS 适配器整合多模型支持,采用开放式 API 设计,并配套开发了零依赖的 Web 管理界面,支持语音克隆与实时测试。该方案解决了离线部署与多后端碎片化问题,统一了 Qwen、Fish Spee
LiveTalking 近期完成 TTS 引擎升级,引入 vLLM-Omni 作为统一推理框架,在 RTX 3090 上实现 130ms 首包延迟和 13GB 显存占用的流式语音合成。新架构通过 OmniTTS 适配器整合多模型支持,采用开放式 API 设计,并配套开发了零依赖的 Web 管理界面,支持语音克隆与实时测试。该方案解决了离线部署与多后端碎片化问题,统一了 Qwen、Fish Spee
开源实时数字人项目 LiveTalking 本次更新带来了后台管理系统、Avatar 生成管线 API 和全新前端页面
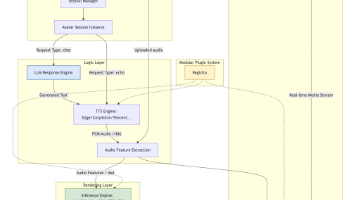
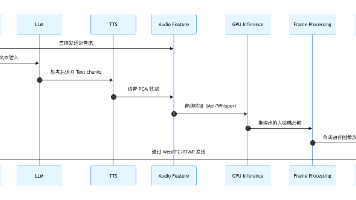
本文深入解析了开源项目LiveTalking的架构设计,重点介绍了其实现低延迟数字人互动的关键技术。项目采用模块化分层设计,包含接入网络层、会话控制层、数字人调度层和AI模型层。核心Class基于Registry插件化体系,支持动态加载组件。数据流转通过LLM-TTS-音频特征提取-推理-合帧处理-推流的完整Pipeline实现。为保障性能,项目设计了"三线程+一协程"的并发架
跨域问题原因是前端代码放在A服务器上,其中的脚本需要访问B服务器的接口,此时在浏览器上因为安全问题限制访问因此需要在B服务器的配置白名单中加上A。服务器需要向发出的 http 响应中添加一些 Access-Control 标头,以指示哪些网页有权从 Web 浏览器读取该信息如果只是调试用,可以在A服务器上配置代理到B服务器,如nginx配置如下:proxy_passB服务器地址;然后将代码中访问B

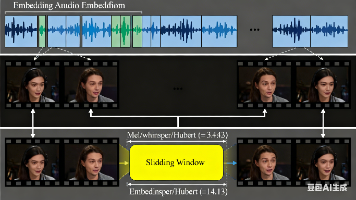
LiveTalking开源项目提供数字人嘴型驱动技术,支持离线与实时音频处理。离线系统处理完整音频文件,而实时系统采用流式数据处理策略,通过前后缓存参数(stride_left_size/right_size)平衡延迟与准确性。系统初始化时会预填充音频队列,采用16帧批次处理,保留部分帧作为上下文缓存。音频特征通过滑动窗口与视频帧匹配,不同模型(mel/whisper/hubert)有特定参数配置
本文介绍了如何使用TURN转发服务解决GPU服务器UDP端口受限的问题。主要内容包括:1)在云服务器安装coturn服务并配置认证信息、UDP端口范围;2)服务端开放TCP 8010端口运行livetalking应用;3)修改客户端配置使用TURN服务地址。通过这种方式,可在不开放UDP端口的服务器上实现视频转发,每路视频需要2个UDP端口。提供了详细的配置步骤和测试方法。
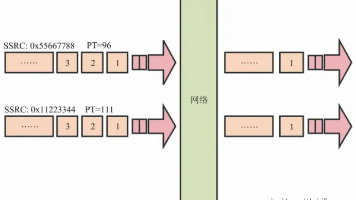
摘要:文章探讨了实时数字人LiveTalking在多并发场景下的模型推理优化方案,比较了多进程与多线程的优劣。多线程可减少显存占用(共享模型),但可能影响实时帧率;多进程则存在显存线性增长问题。测试数据显示:wav2lip(1.3G显存/750fps)支持30路并发,musetalk(12G显存/60fps)支持2路,ernerf(2G显存/45fps)建议用多进程。针对不同模型特性提供了线程/进
