




- @liangyihuai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文章将讲解如何借用机器学习框架Tensorflow和Keras,构建LSTM神经网络模型,通过学习音乐数据,来自动合成一段音乐。训练的原始音乐数据为:下载试听合成的音乐例子:下载试听完整代码(包含训练数据集):源码下载。其中主方法在MusicGenerator.py文件中。1. 神经网络结构模型1.2. 模型的输入数据每一次输入的是一个“音符”,这里为了便于理解,把一个音符抽象出...
本博文所说的代码冲突是指:项目托管在git服务器上面,两个人同时修改了同一个文件导致的冲突问题。问题解决:工具:intelij IDEA 2016.21、本地文件修改如下图:2、远程服务git中的文件如下图:3、先commit本地修改的文件到本地repository4、pull源码,因为存在代码冲突,所以接下来会自动弹出merge融合窗口
这篇文章将讲解如何使用python建立多层神经网络。在阅读这篇文章之前,建议先阅读上一篇文章:理解神经网络,从简单的例子开始。讲解的是单层的神经网络。如果你已经阅读了上一篇文章,你会发现这篇文章的代码和上一篇基本相同,理解起来也相对容易。上一篇文章使用了9行代码编写一个单层的神经网络。而现在,问题变得更加复杂了。下面是训练输入数据和训练输出数据,如果输入数据是[1,1,0],最后的结果是什么呢?从
训练一个好的卷积神经网络模型进行图像分类不仅需要计算资源还需要很长的时间。特别是模型比较复杂和数据量比较大的时候。普通的电脑动不动就需要训练几天的时间。为了能够快速地训练好自己的花朵图片分类器,我们可以使用别人已经训练好的模型参数,在此基础之上训练我们的模型。这个便属于迁移学习。本文提供训练数据集和代码下载。原理:卷积神经网络模型总体上可以分为两部分,前面的卷积层和后面的全连接层。卷积
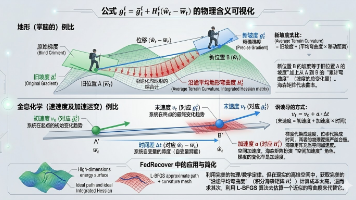
假设我们有一个完整的训练数据集Dz1z2znDz1z2zn,其中zixiyizixiyi是单个样本。LθD∑i1nℓziθλ2∥θ∥22LθDi1∑nℓziθ2λ∥θ∥22我们假设模型在完整数据集DDD上已经训练到了严格的全局最优(这是凸优化背景下的标准假设,我们稍后会讨论它在深度学习中的局限)。
∫01dz∫01dz∫01进度为z时的曲率dz\int_{0}^{1} (\text{进度为 } z \text{ 时的曲率}) dz∫01进度为z时的曲率dz如果你在走这段路时,每隔极短的距离(dzdzdz)就测一次曲率,然后把所有的测量结果累加起来,这就是积分的物理意义。因为你的进度条zzz的总跨度正好是1−011−01,所以对zzz从 0 到 1 求定积分,在数学上刚好等于求这无穷多个测
本文分为两部分,第一部分说明零知识能干什么,为什么它这么强大,在区块链中这么火;第二部分比较零知识证明的算法zkSNARK, zkSTARKs, zkBoo, Sonic和BulletProofs的特性。本文首发在本人知乎专栏中,更多区块链论文阅读,请关注本人知乎哦第一部分使用零知识算法能干什么?设定一个场景,现有一个公共的函数f和一个函数的输出值y,Alice对Bob说她知道x值,但是Bob不信
修改python plot折线图的坐标轴刻度,这里修改为整数:代码如下:from matplotlib import pyplot as pltimport matplotlib.ticker as tickerimport numpy as npdef std_plot():overall_std = [34.369, 21.366, 16.516, 11.151...
这篇文章将讲解如何使用python建立多层神经网络。在阅读这篇文章之前,建议先阅读上一篇文章:理解神经网络,从简单的例子开始。讲解的是单层的神经网络。如果你已经阅读了上一篇文章,你会发现这篇文章的代码和上一篇基本相同,理解起来也相对容易。上一篇文章使用了9行代码编写一个单层的神经网络。而现在,问题变得更加复杂了。下面是训练输入数据和训练输出数据,如果输入数据是[1,1,0],最后的结果是什么呢?从