




- @lemon_TT
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一般生产环境NN和RM吃资源少的会单独配置,而工作节点会单独配置资源较多,例如Master节点配置为16核CPU、64G内存;Workder节点配置为32核CPU、128G内存,五台服务器如下所示hadoop100hadoop101hadoop102hadoop103hadoop104mastermasterworkerworkerworkerNameNodeNameNodeDataNodeDat
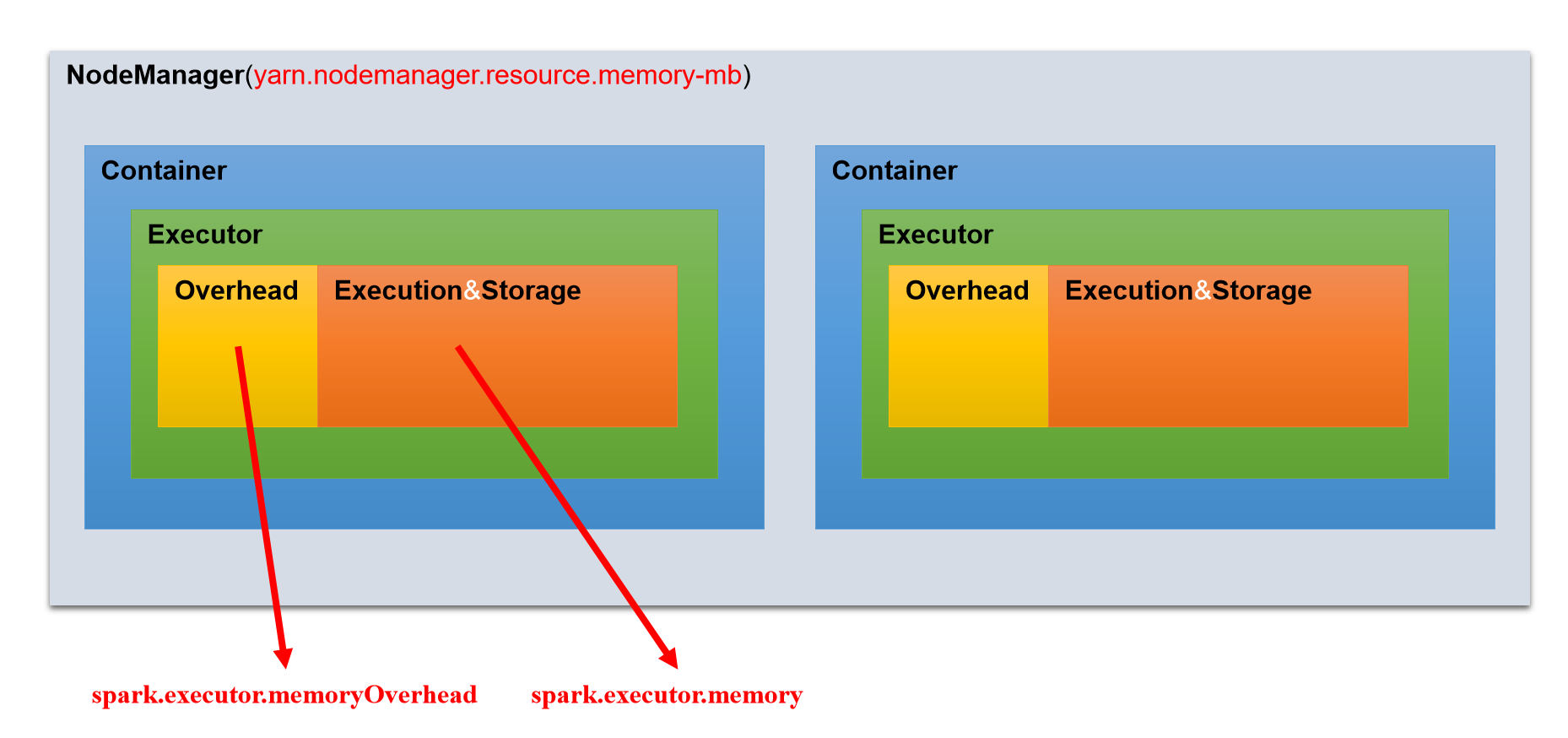
Hive引擎包括:默认MR、Tez、SparkHive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。

文章目录一、框架说明二、GPU相关三、前置知识学习四、搭建第一个神经网络(回归)五、CNN卷积神经网络实现MNIST数据集六、RNN循环神经网络实现MNIST数据集七、AutoEncoder自编码八、GAN生成对抗网络九、DQN强化学习一、框架说明Pytorch具体的APi操作详见Pytorch官方Api文档,torchvision具体Api操作详见torchvision官方Api,下面介绍一下常
1、Octotree - GitHub code tree????它会在github左边会生成一个 Octotree 按钮,登录后鼠标滑动代码文件树,这样就可以快速定位文件和查看文件了。类似的还有Sourcegraph插件2、Enhanced GitHub????之前从github上下载文件都需要整个工程clone,下载了该插件后可以进行单个文件的下载3、GitZip????多个文件一起下载,或者
一、正常方式搭建OwnCloudcentos 7搭建owncloud个人私有网盘基于宝塔面板和nextcloud搭建自己的网盘二、基于Docker容器快速搭建这里默认已经下载安装好并成功启动了docker,并成功进行了配置#拉取docker镜像docker pull ownclouddocker pull mysql#创建文件存储路径,自定义但要记住该路径,下面是我个人路径mkdir /lxt/d
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(Pseudo-Cluster)、集群模式(Cluster)等Airflow是一个以编程方式编写,安排和监视工作流的平台。使

在应用开发中,特别是web工程开发,通常都是并发编程,不是多进程就是多线程。这种场景下极易出现线程并发性安全问题,此时不得不使用锁来解决问题。在多线程高并发场景下,为了保证资源的线程安全问题,jdk为我们提供了关键字和可重入锁,但是它们只能保证一个工程内的线程安全。在分布式集群、微服务、云原生横行的当下,如何保证不同进程、不同服务、不同机器的线程安全问题,jdk并没有给我们提供既有的解决方案。目前
Redis6.0学习笔记分布式锁、限流、处理请求接口幂等性,本篇文章重点讲述SpringBoot通过注解和AOP的方式实现Redis的接口限流,Redis使用了Lua脚本实现原子操作;通过redis实现的分布式锁以及处理接口幂等等方案限流就是限制API访问频率,当访问频率超过某个阈值时进行拒绝访问等操作当然这是在代码层面进行的接口限流,现在分布式微服务接口限流基本是在网关处做接口限流/黑白名单等,
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用DolphinScheduler支持多种部署模式,包括单机模式(Standalone)、伪集群模式(Pseudo-Cluster)、集群模式(Cluster)等Airflow是一个以编程方式编写,安排和监视工作流的平台。使
