- @laot007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
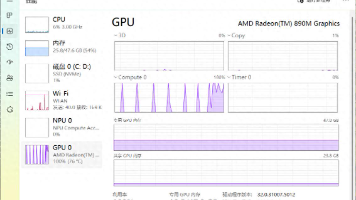
《慢虾哲学:低配硬件上的高效AI实践》摘要 作者通过迷你主机(AMDAI9HX370)运行27B参数大模型(Qwen3.6)的实践,提出"慢虾"理念:8.5token/s的生成速度恰与人类思考节奏同步,创造了理想的交互体验。关键技术突破在于采用多token预测算法(MTP),使推理速度提升近一倍(4.57→8.5t/s)。文章对比了稠密模型与混合专家模型的特点,指出稳定性比速度

本文介绍了一种基于1升体积小主机的本地AI部署方案,搭载AMDAI9HX370处理器和Radeon890M集成显卡,通过优化配置在96GB内存中流畅运行27B参数的稠密大模型Qwen3.6-27B-MTP(Q4量化)。关键创新在于:1)利用推测解码技术(76.7%接受率)将生成速度提升至8.5t/s;2)采用KV缓存量化等内存优化手段;3)实现65W超低功耗与静音运行。作者通过实际日志分析证明,该
《矿卡重生记:8GB显存P104在Ubuntu上跑35B MoE模型的实战指南》 本文记录了作者将一张被淘汰的NVIDIA P104-100矿卡(8GB显存)改造成AI推理卡的完整过程。通过破解驱动、优化PCIe通道、精细调整卸载层数等技术手段,最终在Ubuntu系统上实现了Qwen3.6-28B MoE模型51t/s的prefill速度和20t/s的生成速度。文章详细分享了驱动安装、编译调优、P

摘要: 本文记录了在老旧Quadro P2000显卡(5GB显存)上成功运行35B参数MoE模型的全过程。通过对比测试发现,35B MoE模型在优化参数(ngl=8)下生成速度达11.88 t/s,反超9B稠密模型45%,且回答质量显著提升。关键优化包括精准控制GPU加载层数、采用KV Cache量化(q4_0)缓解显存压力。测试涵盖Qwen3.5和Gemma-4系列模型,证明老卡搭配MoE架构仍
自动布线在电路设计中的价值主要体现在其高效性和准确性,尤其在处理复杂和密集的布线任务时。与手工布线相比,自动布线能够快速完成大量的查找、对比、分析和决策工作,极大地减轻了设计师的脑力负担。通过自动布线,设计师可以轻松判断元器件布局的合理性,并进行必要的调整,如改变边缘接口位置或芯片的旋转方向,从而优化布线结果。此外,自动布线还能帮助设计师完善布线规则,通过多次循环调整,确保布线结果符合预期。局部的
阿里狗16.6的自动布线功能虽然强大,但用户在使用时可能会遇到一些问题。本文提供了几条优化自动布线的建议:首先,设计合理的布线规则,包括线宽、间距和过孔规格,特别是针对不同类型的信号线进行区分设置。其次,确保覆铜shape指定了正确的网络名,以便于连接同名引线。此外,在antiEtch逻辑层和viakeepout层放置拒布区域或禁止过孔区域,可以帮助自动布线更符合实际需求。最后,如果自动布线出现无
本文记录了将AI助手nanobot部署到阿里云虚拟主机,并接入飞书机器人的全过程。通过科大讯飞MaaS平台的免费大模型token,实现了让AI自主开发Web服务的创新实践。文章详细介绍了云端环境配置、飞书接入方法,以及AI自主编程的完整案例,包括解决端口放行等实际问题。特别强调了免费token资源对AI实验的重要价值,使开发者能够无顾虑地进行大量调试迭代。整个过程展现了AI从本地工具升级为云端服务
《nanobot进阶指南:打造自我进化的智能体》深入解析了如何定制和扩展nanobot智能代理的核心功能。文章揭示了nanobot作为LLM调度中枢的设计哲学,展示了通过修改Markdown文件即可定义智能体"人格"的工作空间架构。重点介绍了技能开发方法、自主代码维护能力(通过TODO.md驱动自我优化)、创新的对话压缩技术(实现无限长对话),以及Cron定时任务与Heartb
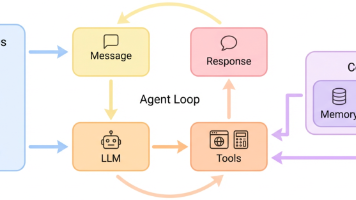
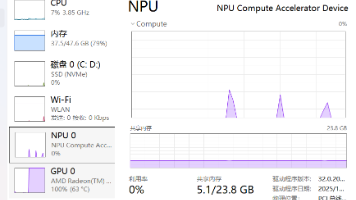
《在HX 370上使用NPU加速LLM实践》介绍了如何利用AMD Ryzen AI 300系列处理器(如HX 370)集成的XDNA 2架构NPU来运行大语言模型。文章详细说明了安装Lemonade Server工具、配置NPU的Turbo模式、选择适配的ONNX格式模型以及通过镜像站加速下载模型的方法。作者还分享了如何让Lemonade自动识别模型,并验证NPU是否正常工作。相比GPU推理,NP