- @l8947943
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
The Basics of ConvNets
可以理解为配置下载对应文件时候要使用的源。如果要避免这个情况,请将上面这一行写入Linux中的。表示下载指定数据目录,以safetensors结尾的,不下载.bin结尾的文件。注意:使用wget命令并不会得到下载好的大文件内容,这点需要注意。为什么会要这么做,tmd下载一半电脑挂了,头大。上述配置环境变量代码,每次下载前均需要配置。Windows环境没测试过。wikitext文件夹中。

1. 200相应代码Status Code:200表示响应成功,很常见的一个状态2.300响应代码Status Code:301 表示客户端跳转,永久性跳转,一般在servlet中使用如下代码response.setStatus(301);response.setHeader("Location","fail.html");3.302响应
i = 0 # 控制循环轮次bot = Agent(prompt) # 初始化i += 1result = bot(next_prompt) # 每次将执行的结果,作为下一次提示词返回给模型] # Action函数用于得到过滤后的结果,用于获取后续函数执行时的输入和参数observation = known_actions[action](action_input) # 调用函数得到结果。

项目中常常会涉及到缓存的使用,但是引入缓存会带来一致性问题,需要考虑数据一致性处理。首先看一下操作逻辑,查询逻辑:更新或者删除逻辑在项目中,如果是cache-aside pattern模式,则会考虑使用先更新DB,再去删除cache的操作,原因分析如下:同时写数据库以及缓存数据,任何一个更新失败都会造成数据不一致。另外事务都成功,无论是先更新缓存还是再更新数据库,还是先更新数据库再更新缓存,这两种
最早的分类问题是线性分类,因此仅靠一条线可以进行划分。如图:但是对求解非线性问题,则是通过某种非线性变换φ(x),将输入空间映射到高维特征空间,从而找到一个超平面进行分类。其实在svm中,就用到了核函数的思想,为了更清晰的呈现,特意去找了个视频:核函数思想摘自好了,看完视频,我们也知道了其实对于不可分的平面,在支持向量过程中,采用的是通过映射到高维空间后,从而可以形成一个超平面,最终实现了超平面分
解决方法: 简单粗暴,使用官方的图形化界面操作即可!!!哪来那么多命令操作,真烦!先fork,弄个叉子,如图然后你忘了这个项目,很久没更新,发现原来的已经更新的不像样子了,于是,你赶紧想同步一下,于是,如图:点击发起合并请求然后操作如图点击让合并的次序更改过来然后点击merge就ok了...
1. 在服务器上安装redis(利用wget方法)# 源码安装位置$ cd ./usr local/src# 下载文件到该文件夹中$ wget http://download.redis.io/releases/redis-3.0.7.tar.gz# 解压下载的文件$ tar xzf redis-3.0.7.tar.gz# 编译安装redis$make$ make al...
1. 基于APT源安装sudo apt-get install nginx最终结构/usr/sbin/nginx:放置nginx的主程序,一般进行运行./nginx/etc/nginx:存放配置文件,一般修改配置在这儿/usr/share/nginx:存放静态文件/var/log/nginx:存放日志2. 在安装过程中出了一点问题,卸载# 卸载nginxs...
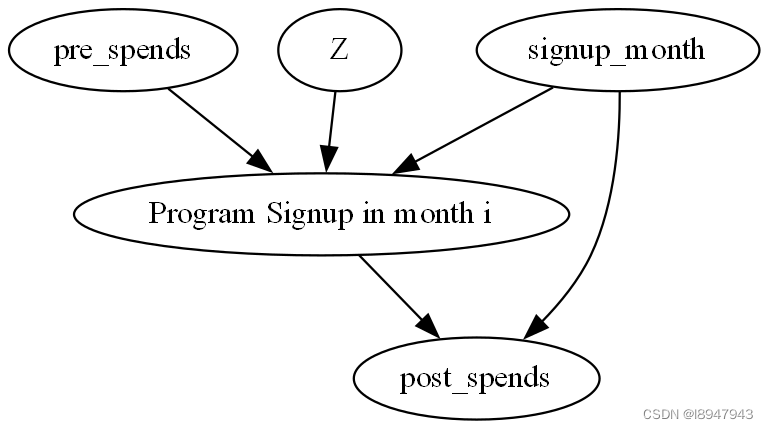
评估的例子。假设一个网站有会员奖励计划,如果客户注册,他们会得到额外的好处。我们如何知道该会员奖励计划是有用的?该问题的反事实问题是,该问题在因果推理中,我们感兴趣的是。