




- @kittyzc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. 问题介绍通过深度学习的方法,可以识别出区域人流的密度,如下图:再通过摄像头坐标投影转换到地图上,就可以绘制人群热力图了。资料集合见:https://github.com/gjy3035/Awesome-Crowd-Counting技术路线大致有3个方向:1)行人检测,包括传统cv方法和深度学习模型方法,但是这个方法对遮挡非常敏感。2)机器学习回归法,直接回归行人数。3)密度图法,当前主流。密
含义:CLIP(Contrastive Language-Image Pre-training)git地址:https://github.com/openai/CLIPpaper:https://arxiv.org/abs/2103.00020安装:pip install git+https://github.com/openai/CLIP.git
Kokoro TTS 以其轻量级设计和高效性能脱颖而出。作为一个仅有82M参数的文本转语音(TTS)模型,Kokoro 在 TTS Spaces Arena 中击败了许多参数规模更大的竞争对手,成为语音合成领域的一颗新星。
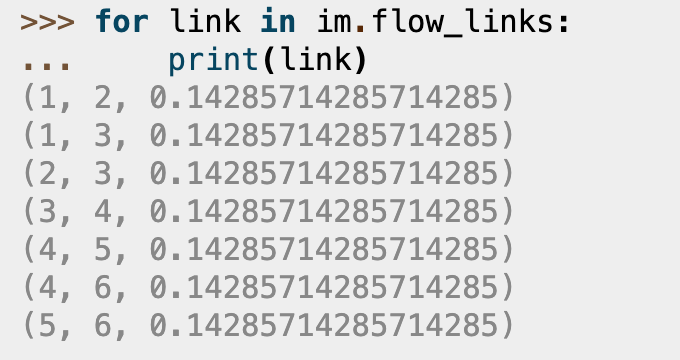
1. 原理与安装安装:最新版本安装有点问题,pip install infomap==1.0.1原理:图中随机游走时,若节点间转换的概率一样,则随机游走在群内停留时间更长。infoMap 的想法是将每个节点的编码分为两个部分模块码和节点码,模块码用于区分图中不同的群,节点码用于区分相同模块内不同节点。不同模块节点的模块码不同,但节点码可能相同。实现:1. 计算节点访问概率:对于每个节点 ,有两种方
agent的核心是其代理协同工作的能力。每个代理都有其特定的能力和角色,你需要定义代理之间的互动行为,即当一个代理从另一个代理收到消息时该如何回复。agent目前大多使用openai标准接口调用LLM服务,说明如下。标准接口示例如下,其中role包括:system(设定了 AI 的行为和角色,和背景),user(我们输入的问题或请求),assistant(自动生成)

")k: int。

前面介绍过VAVQE模型,它本质上是一个encoder-decoder模型,只是中间加了一个codebook。这样我们就可以把尺寸大大缩小。得到codebook后,图片可以用其进行编码,然后使用自回归模型(比如transformer)来进行序列生成。Taming Transformer就是这样的一个模型。与之相对应的,是早起的PixelCNN、PixelRNN等直接在像素级别进行序列预测的模型,只
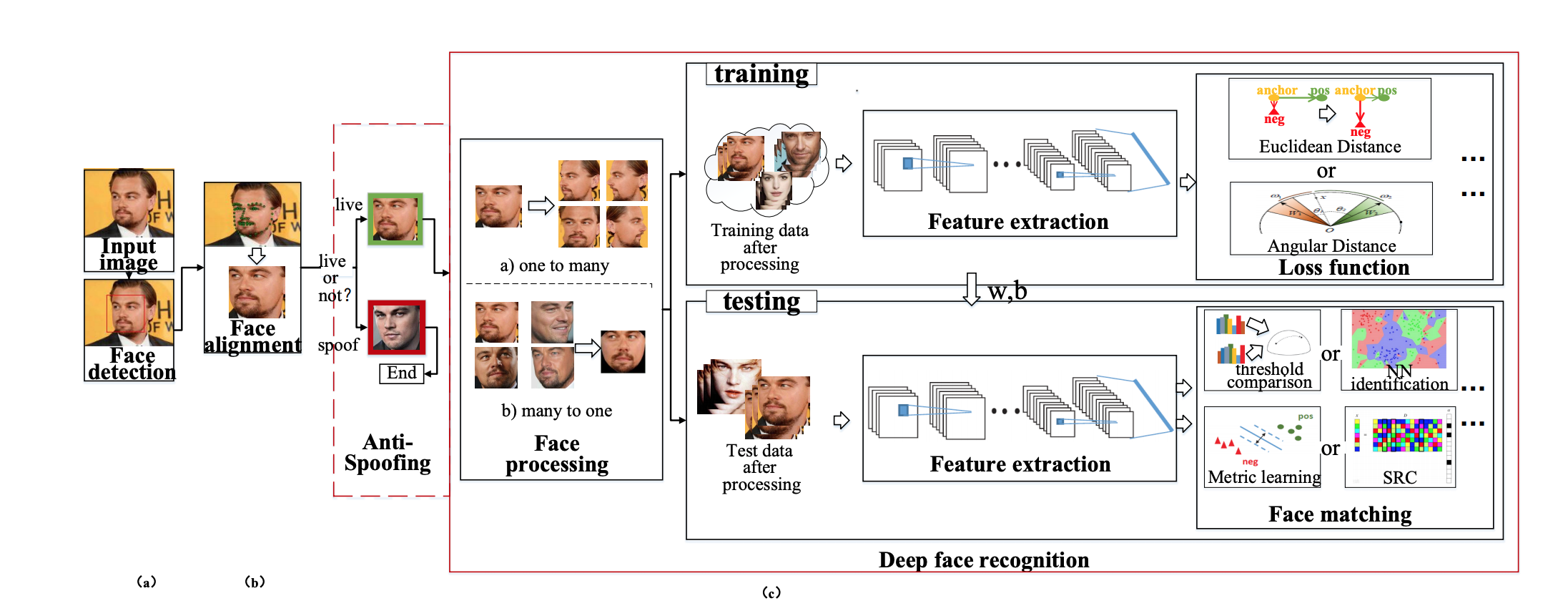
本文参考https://zhuanlan.zhihu.com/p/765132171. 基础这是一篇review的文章。下图是基本流程:1.1 数据集公开数据集的变迁如下:1.2 前处理人脸处理的变迁如下:1.3 网络架构主架构的变迁如下图:1.4 目标函数通常,人脸识别可分为人脸识别和人脸验证。前者将一个人脸分类为一个特定的标识(identification),而后者确定一对图片是否属于同一人(
1. AEAE(Autoencoder),自动编码器。我们常用的encoder-decoder即为最简单的一种AE。训练过程中加上一些扰动,就可以变成去噪自编码器(DAE):或者用遮盖(MIM,mask image modeling)的方法来加扰动:2. VAE损失为重构误差+KL散度,对应GAN中的判别器。对于每一个样本,需要用神经网络拟合均值uuu和方差δ2\delta^2δ2,然后用标准正态
1. 快速上手首先安装: pip install transformers这里有不同种类语言的离线模型清单:https://huggingface.co/languages最简单的使用方式,是使用现成的pipeline,见第2节2. pipeline预训练的模型如下:"audio-classification": 语音分类"automatic-speech-recognition" 语音识别"co