- @king14bhhb
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
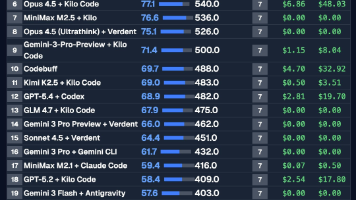
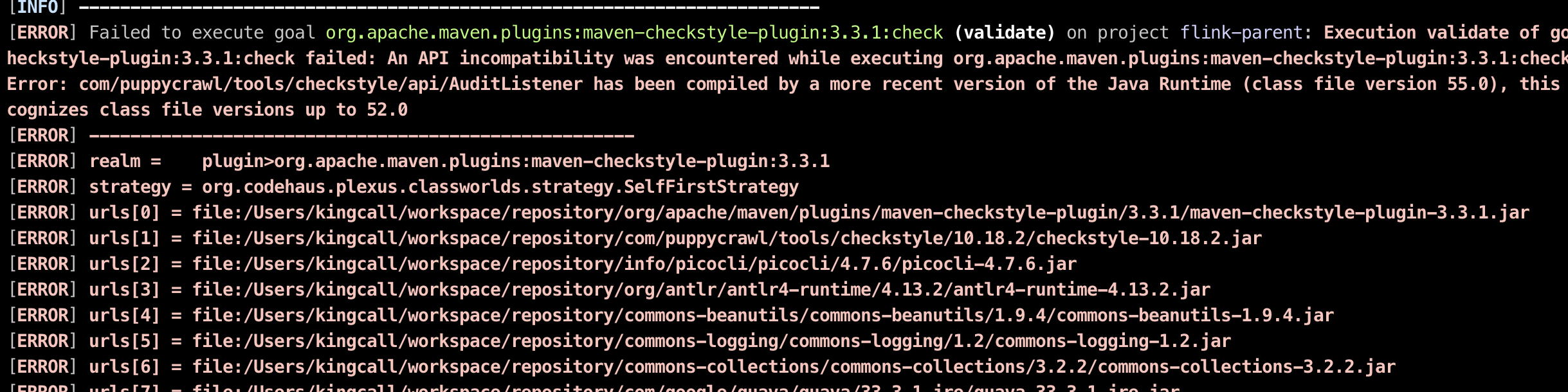
除了新功能外,Flink 2.0 还对已弃用的 API 和配置进行了全面清理,这可能导致某些接口和行为出现向后不兼容的变化。看到Flink2.0 出来了,想去玩玩,看看怎么样,当然第一件事,就是编译代码,但是没想到这么多问题,首先我们还是看一下Flink 2.0 有什么变化。在 2.0 版本中,Flink 引入了若干创新性功能,以应对实时数据处理的关键挑战,并满足现代应用(包括人工智能驱动的工作流
远程开发 极致体验为什么要进行远程开发无论身处何处数秒内连接至远程环境充分利用远程计算机的强大功能充分利用远程计算机的强大功能在任何笔记本电脑上都可以轻松工作,无论其性能如何。借助远程计算机的计算资源,充分利用最大规模的数据集和代码库。在远程服务器上保护敏感代码保持环境一致性简化入门和技术面试在远程服务器上保护敏感代码如果将源代码存储在开发者的笔记本电脑上,那么这些设备被盗或存放不当都将是潜在的安
股票数据分析前面我们介绍了Spark 和 Spark SQL,今天我们就使用 Spark SQL来分析一下我们的数据,今天我们主要分析一下股票数据数据准备交易数据我们拿到了最近几年的交易数据下面是具体的数据格式,csv 文件,ts_code 对于的是一个股票代码股票详情数据日期数据因为股票市场不是天天开的,只有交易日才开门,下面就是我们的交易日数据数据分析当然这里我们的分析并不是教大家去怎么买卖股
摘要 本文系统性地解决了传统RAG在AI答疑系统中的三大核心瓶颈:意图识别模糊、知识碎片化和评测闭环缺失。创新性地提出思维链驱动的并行检索架构,通过分解问题为多步逻辑查询并并行执行,显著提升召回质量。针对传统RAG的结构性局限,探索了从GraphRAG到轻量级LightRAG的检索架构演进,在保留图结构优势的同时实现秒级响应。最后构建了多维度评测体系,强调人工校验以克服模型过度自信问题,形成从问题
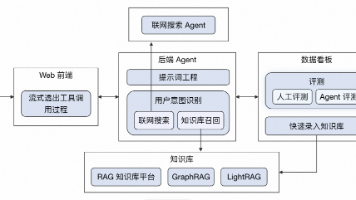
本文主要介绍了当前构建基于大语言模型的应用时最主流的 RAG 的核心思想、基本工作流程,RAG 与 LlamaIndex、GraphRAG、 RAGFlow 之间的关系与区别以及RAG学习建议与技术选型。
本文主要介绍了当前构建基于大语言模型的应用时最主流的 RAG 的核心思想、基本工作流程,RAG 与 LlamaIndex、GraphRAG、 RAGFlow 之间的关系与区别以及RAG学习建议与技术选型。
清华大学NMRC团队开源OpenHarness框架,专为OpenClaw AI代理设计的7*24小时自动化任务执行系统。该框架基于编排工程理念,实现任务全生命周期管理,包含初始化、调度配置、状态跟踪、结果验证等完整闭环。核心亮点包括工程化设计、标准化接口、状态可追溯、熵控制机制和外部验证功能,确保长期稳定运行。支持Markdown表格存储和JSON存档,提供可视化报告,适用于定时数据采集、内容生成

答案是:什么都往里扔。把文章复制粘贴成 .md 或 .txt 文件,截图和图表直接保存,从你现在用的任何应用里导出笔记,会议记录、研究论文、项目文档,还有那些囤了几个月的书签,统统扔进去。这就是 Karpathy 使用的结构:raw/ 文件夹是你的原始素材收纳箱,wiki/ 文件夹是 AI 帮你理出条理的地方,outputs/ 文件夹存放问题的答案。Karpathy 自己也说了,他的 AGENTS

Cursor 3发布,聚焦解决AI编程中的工作流痛点。主要更新包括:1)新增Agents Window实现多任务并行处理,支持跨仓库/环境同时运行多个任务;2)引入Git Worktree物理隔离机制,通过/worktree指令让AI在独立环境操作,保护主干代码安全;3)Design Mode支持前端开发者通过框选UI元素代替语言描述,提升问题定位效率。此外还优化了结构化输出、大文件渲染等细节。此
GLM-5.1展现强大长任务处理能力,成为Agent场景新标杆。实测显示其编程能力提升20%,在多项基准测试中名列前茅,尤其擅长处理多步骤复杂任务,能自主规划、纠错并完成完整项目开发。相比Claude Opus 4.6,GLM-5.1以更低价格提供相近体验,已帮助用户成功开发语音输入工具等实用项目,显著节省成本。社区测试还验证了其在游戏开发、设计绘图等领域的出色表现,其长程任务稳定性在国内模型中处