




- @jlmxu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI编程革命深度解析:2025年开发者效率提升300%的关键 核心要点: 市场爆发:AI编程工具市场年收入达5亿美元,北美开发者采用率85%,中国30%但增速超200% 技术突破:从单行补全(Copilot)→多文件编辑(Cursor 1.x)→多智能体协作(Cursor 2.0)的演进 效率提升:电商案例显示开发周期从3周缩短至5天,bug率降低60%,产出翻倍 三大流派: GitHub Cop

OpenClaw 想解决的是:怎么让 AI 真正变成一个常驻的个人助手。Hermes 想解决的是:怎么让 Agent 在更低成本下持续学习、越用越顺手。Superagent 想解决的则是:当 Agent 真要进生产环境时,怎么别把公司数据和合规底线一起送走。
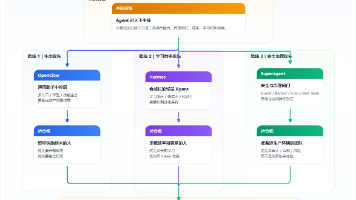
真正危险的不是大模型“说错”,而是 Agent 在接入文档、邮箱、工具和业务系统后,被外部内容带偏、被工具链放大、被过量权限推向错误执行。企业现在最该补的,不是模型效果课,而是 Agent 的输入隔离、工具白名单、最小权限、人工确认和审计链路。

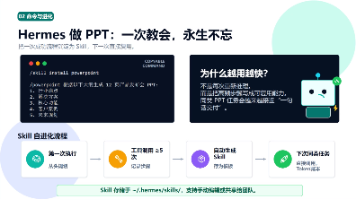
文章摘要:作者分享使用Hermes的PowerPointSkill自动生成PPT的实战经验。从确认技能可用、创建独立Agent,到解决飞书/微信接入问题,详细记录了操作流程和避坑要点。重点展示了如何用自然语言撰写设计稿,审批危险命令,以及最终获取可编辑PPT文件。作者指出该方法虽不能替代专业设计,但能大幅提升初稿制作效率,特别适合内部汇报等场景,并提供了5步上手指南。核心价值在于将"从零
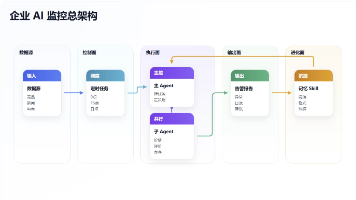
《企业数据监控的AI革命:从被动响应到主动决策》 核心摘要: 企业数据监控正经历从人工脚本到AI系统的范式转变。传统监控方式存在三大痛点:响应滞后(如案例中周五的价格变动周一才发现)、经验无法沉淀(每次变更都需重新编码)、多任务处理能力薄弱。HermesAgent系统通过四大创新解决这些问题:1)定时智能调度,实现无人值守监控;2)持久记忆功能,使业务规则越用越精准;3)Skill自进化机制,将处
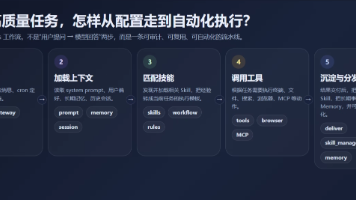
本文提供了Hermes Agent的深度配置指南,从基础安装到高效使用的四个关键步骤: 模型配置:根据任务类型选择合适模型,通过config.yaml和.env文件管理模型行为和密钥。 技能优化:将常用工作流程沉淀为Skill,建立可复用的方法库,存放在~/.hermes/skills/目录。 记忆强化:安装长期记忆插件,建立分层记忆系统,实现跨会话的持续协作体验。 工具扩展:合理启用内置工具,区
很多团队做 AI Agent(智能体)的第一步,是写几行代码去调模型 API。这没错。但如果你要把它放进企业生产环境,这一步最多只完成了 20%。真正麻烦的东西在后面:谁能调用?调多少次?超时怎么办?工具能不能越权?上下文丢了怎么办?成本怎么归集?返回 200 但答案错了,谁来发现?很多企业第一次接入大模型时,以为自己在做“智能应用”。上线以后才发现,自己只是把业务系统和模型 API 用一根细线绑
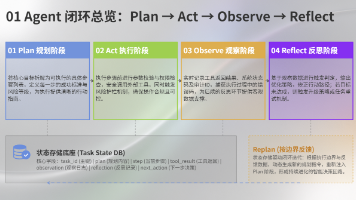
本文指出构建有效Agent系统的关键在于实现真正的任务闭环,而非形式化的反思流程。作者从工程角度提出七点核心原则:1) 计划必须包含可验证要素而非空泛步骤;2) 执行需系统验证而非模型自主操作;3) 观察应基于结构化外部状态而非主观判断;4) 反思需触发机制和实质行动改进;5) 重规划需严格限制变更范围;6) 建议用任务状态表实现最小闭环;7) 明确Agent适用场景(不确定/高风险任务)。强调成
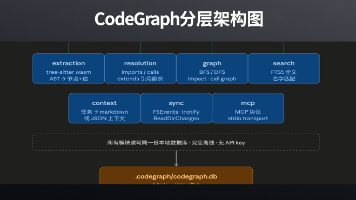
如果你已经把 Claude Code、Cursor、Codex 这类 AI 编程助手用进日常开发,大概率会遇到一个很现实的问题:仓库一大,Token 就开始失控。不是模型不聪明。而是它太容易把时间花在“找路”上。一个中大型项目里,你问一句:“登录链路是怎么走到数据库的?”Agent 往往会先 grep,再 glob,再 Read,再打开一堆文件,接着发现读错了,再换关键词搜一轮。如果它还开了子 A
很多团队做 AI Agent(智能体)的第一步,是写几行代码去调模型 API。这没错。但如果你要把它放进企业生产环境,这一步最多只完成了 20%。真正麻烦的东西在后面:谁能调用?调多少次?超时怎么办?工具能不能越权?上下文丢了怎么办?成本怎么归集?返回 200 但答案错了,谁来发现?很多企业第一次接入大模型时,以为自己在做“智能应用”。上线以后才发现,自己只是把业务系统和模型 API 用一根细线绑