




- @jjk_02027
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
nacos登陆表单明文密码加密指登陆密码在Java客户端配置加密后的密码。 在使用 Nacos 作为服务注册与配置中心时,为了提高安全性,通常不建议在客户端或配置文件中以明文形式存储密码。Nacos 支持密码的加密存储,主要通过以下几种方式实现:1. 使用 Nacos 提供的内置加密/解密工具;2. 在配置文件中使用加密后的密码;3. 解密和验证

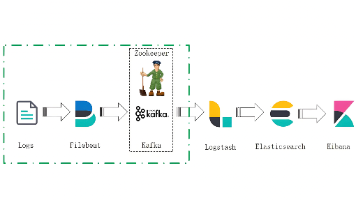
本文对比了传统ELK架构与集成Filebeat和Kafka的ELFKK架构。传统ELK由Elasticsearch、Logstash和Kibana组成,存在资源占用高、扩展性有限等问题;而ELFKK引入Filebeat采集日志并通过Kafka缓冲,具有资源占用低、高吞吐、数据持久化等优势,适用于大规模分布式系统。附件详细说明了Filebeat配置步骤(安装、配置、启动验证)以及Kafka的Kraf
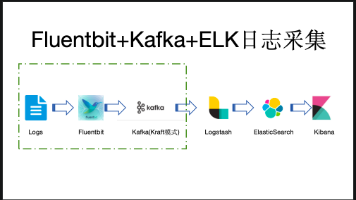
本文介绍了基于FluentBit+Kafka+ELK的日志采集系统实现方案。系统采用四层架构:FluentBit负责日志采集,Kafka作为消息队列缓冲,Logstash进行数据处理,Elasticsearch存储日志数据,Kibana提供可视化展示。方案详细配置了各组件参数,包括日志解析、Kafka连接、异常检测等功能,并提供了Docker Compose部署方式。文中还列举了常见问题及解决方案
DMXAPI注册即享无限制的每分钟请求数(RPM)和每分钟调用次数(TPM),企业客户支持无限并发,适合高流量场景

不同的机器学习库在机器学习和深度学习的不同场景中各有优势,选择合适的库可以提高开发效率和模型性能。本文作者整理了一些常见的机器学习库Scikit-Learn机器学习库 Scikit-Learn官方网站 简介 优化 缺点 社区TensorFlowKeras,PyTorch,XGBoost,LightGBMPandas,NumPySciPy,Dask机器学习库简介、优点缺点、官方网站、社区网址Ama

机器学习分类整理【表格版】,机器学习按学习方式分类,机器学习按学习策略分类,机器学习按任务类型分类,机器学习按应用领域分类,机器学习按学习方法分类,机器学习按数据形式分类,机器学习按学习目标分类

支持分片(Shard)与副本(Replica),数据可分布于多个节点,查询自动并行执行,具备线性扩展能力。以“块”为单位处理数据,充分利用 CPU 的 SIMD 指令并行计算,显著加速查询。适合批量写入(>1000 行/次),不支持高频单行更新或事务,数据通常“只增不改”。设计的高性能列式数据库管理系统,由俄罗斯 Yandex 公司开发并开源,以。数据按列而非按行存储,查询时仅读取所需列,大幅

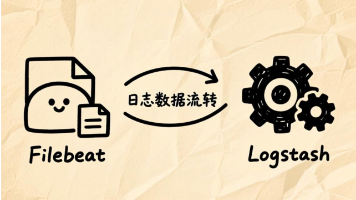
Logstash和Filebeat是Elastic Stack中的核心组件,各有明确分工。Logstash作为企业级数据处理管道,具备强大的ETL能力,支持复杂的数据转换与过滤,但资源消耗较高;Filebeat则是轻量级日志采集代理,专注于高效日志收集与转发,资源占用极低。二者通常协同工作,形成"采集+处理"的完整日志流水线。对于结构化日志或资源受限场景,可考虑仅使用Fileb
文章摘要:本文介绍了在Kibana中分析HTTP客户端类型的解决方案。由于header信息以字符串形式存储且KQL不支持复杂字符串处理,无法直接分组统计客户端类型。作者采用排除法,通过多次查询逐步识别出各种user-agent(包括Postman、Mozilla、okhttp等),并提供了具体查询示例。最后汇总了包含工具的客户端类型列表,展示了如何查询header中不含agent属性的数据。该方法

主流APP多端框架可分为三类:1)跨平台UI框架(Flutter/React Native),适合电商社交类应用;2)全栈跨平台框架(uni-app/Taro),适合覆盖多端生态的项目;3)原生框架(Android/iOS),适合追求极致性能的场景。选择建议:统一UI选Flutter/RN,多端兼容选uni-app/Taro,高性能需求用原生开发。
