
写文章




- @jason_bone_
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
[ 数据结构 ] 最小生成树(MST)--------普里姆算法、克鲁斯卡尔算法
【代码】[ 数据结构 ] 最小生成树(MST)--------普里姆算法、克鲁斯卡尔算法。
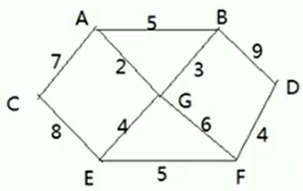
[ 数据结构 ] 排序算法--------冒泡、选择、插入、希尔、快排、归并、基数、堆
1.1 排序分类内部排序和外部排序,前者数据加载到内存,后者数据量大需借助外部文件.内部排序包含:插入排序:直接插入排序,希尔排序选择排序:简单选择排序,堆排序交换排序:冒泡排序,快速排序归并排序基数排序1.2 复杂度1)度量一个程序时间有两种方法,事后统计或事前估算,事前估算就需要分析时间复杂度2)时间复杂度:算法中的基本操作语句的重复执行次数是问题规模 n 的某个函数,计算方法:去常数阶–>
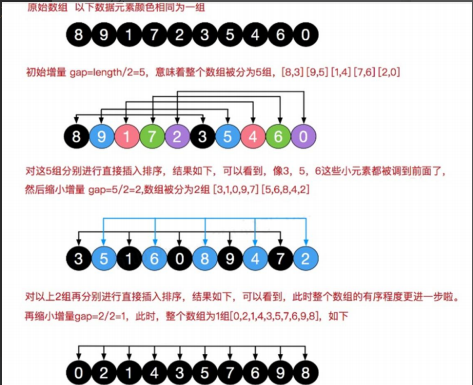
[ 数据结构 ] 平衡二叉树(AVL)--------左旋、右旋、双旋
数列{1,2,3,4,5,6},要求创建一颗二叉排序树(BST), 并分析问题所在。
HBase、Phoenix
一.前言(整体聊聊hbase,hdfs,Phoenix)一.从HDFS角度理解HBase写:1.HBase的数据存储在HDFS之上,HDFS不支持随机写.因此HBase做一系列优化.2.因为HDFS不支持随机写,所以HBase只需要将数据写入内存即可.内存不稳定需要经WAL.3.内存不稳定且有限,因此HBase在合适时机将数据写入到HDFS.那什么时候存呢?由此衍生了HBase的刷写机制.4.刷写
到底了