




- @import__
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
N维数组(张量,tensor)是机器学习和神经网络的主要数据结构创建数组形状(3✕4矩阵)每个元素的数据类型(32位浮点数)每个元素的值(全是0或随机数)访问元素。
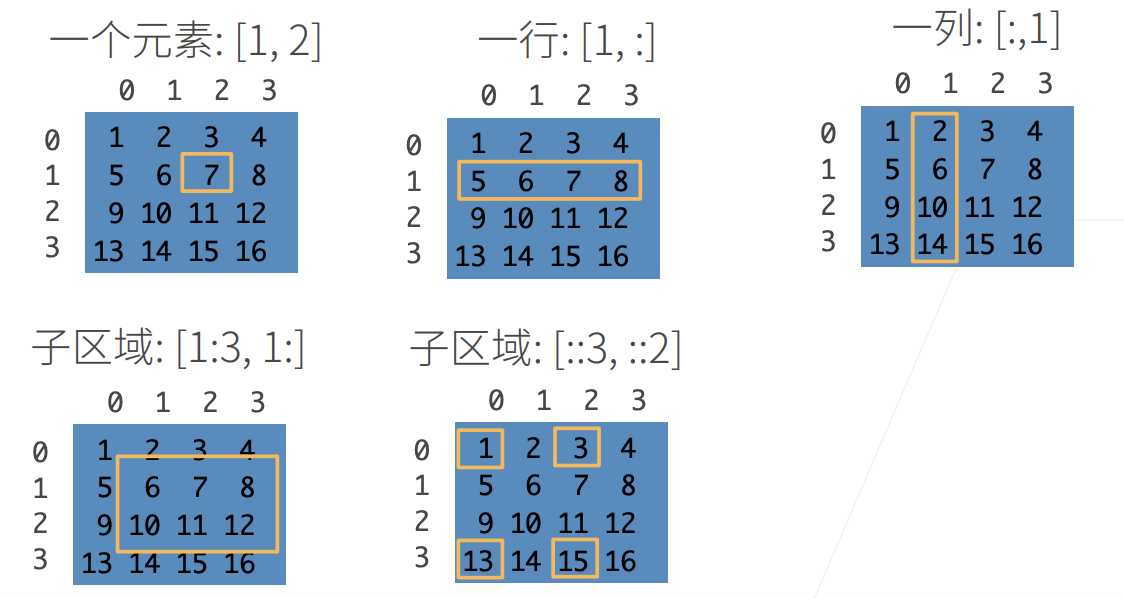
尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见,这种约定将支持常见的深度学习实践,如沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。向量的范数表示一个向量有多大,此处的大小(size)不涉及维度,而是分量的大小;然而,张量的维度用来表示张量具有的轴数,张量的某个轴的维数就是这个轴的长度,如果直接使用。分母转置了,就是分子布局。一般的标量

N维数组(张量,tensor)是机器学习和神经网络的主要数据结构创建数组形状(3✕4矩阵)每个元素的数据类型(32位浮点数)每个元素的值(全是0或随机数)访问元素。
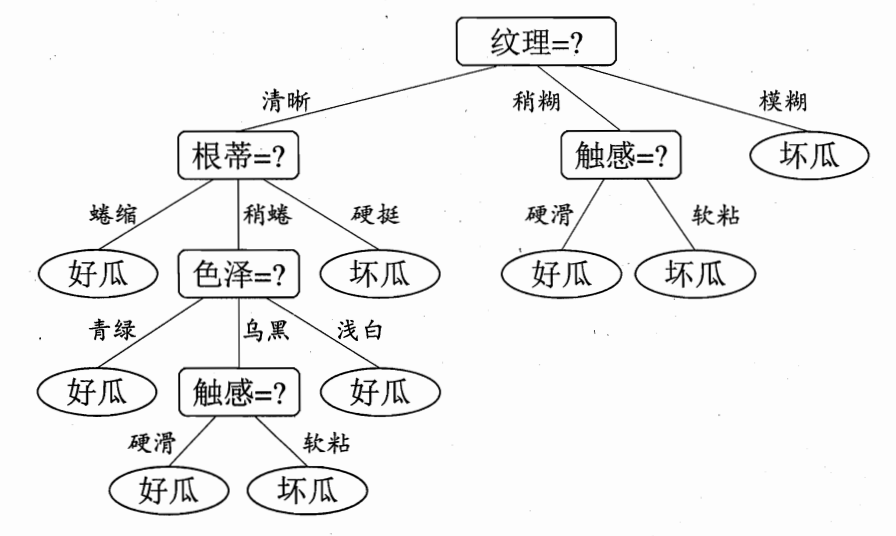
决策树(Decision Tree)是一种非参数的有监督学习方法,非参数指不限制数据的结构和类型,有监督学习则指必须具有标签。决策树能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现,可用于解决分类和回归问题,其算法本质是一种图结构。其他以树模型为核心的集成算法还有随机森林、AdaBoost。以上为基于西瓜好坏问题构建的决策树,其中最初问题所在地方为根结点(没有进边,有出边,包
尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见,这种约定将支持常见的深度学习实践,如沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。向量的范数表示一个向量有多大,此处的大小(size)不涉及维度,而是分量的大小;然而,张量的维度用来表示张量具有的轴数,张量的某个轴的维数就是这个轴的长度,如果直接使用。分母转置了,就是分子布局。一般的标量
N维数组(张量,tensor)是机器学习和神经网络的主要数据结构创建数组形状(3✕4矩阵)每个元素的数据类型(32位浮点数)每个元素的值(全是0或随机数)访问元素。
尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见,这种约定将支持常见的深度学习实践,如沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。向量的范数表示一个向量有多大,此处的大小(size)不涉及维度,而是分量的大小;然而,张量的维度用来表示张量具有的轴数,张量的某个轴的维数就是这个轴的长度,如果直接使用。分母转置了,就是分子布局。一般的标量
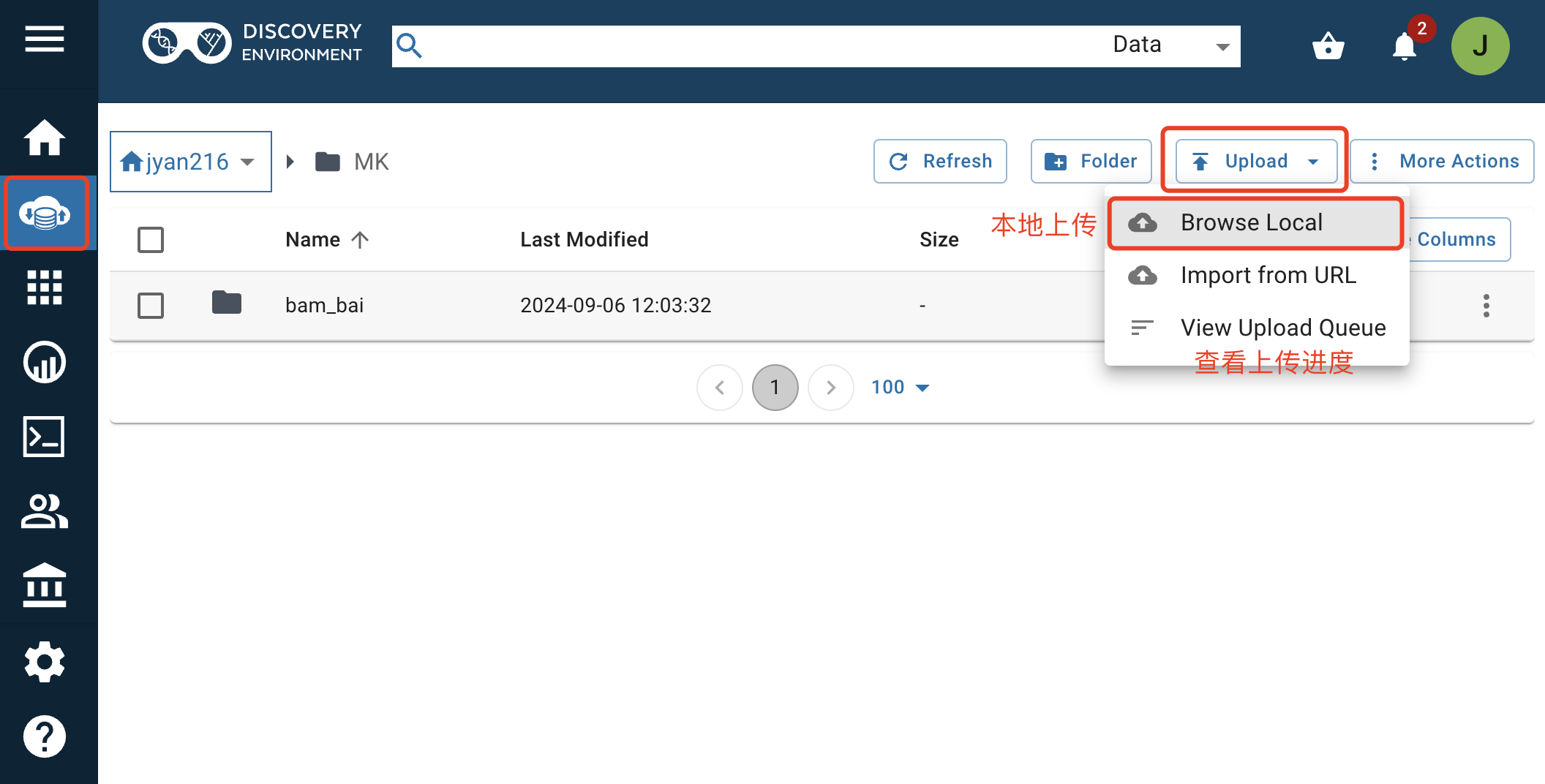
在使用 IGV 或者 UCSC track hub 可视化时,往往需要将数据放置在本地,但考虑到生信数据往往直接放置在服务器上,且文件大小可能高达几GB,此时可以将数据存放到可以接受外部访问的服务器上,然后通过 url 上传数据完成可视化,此处推荐的工具为 CyVerse(https://de.cyverse.org/dashboard)。CyVerse 网站注册登录后可直接通过如下网页操作完成本
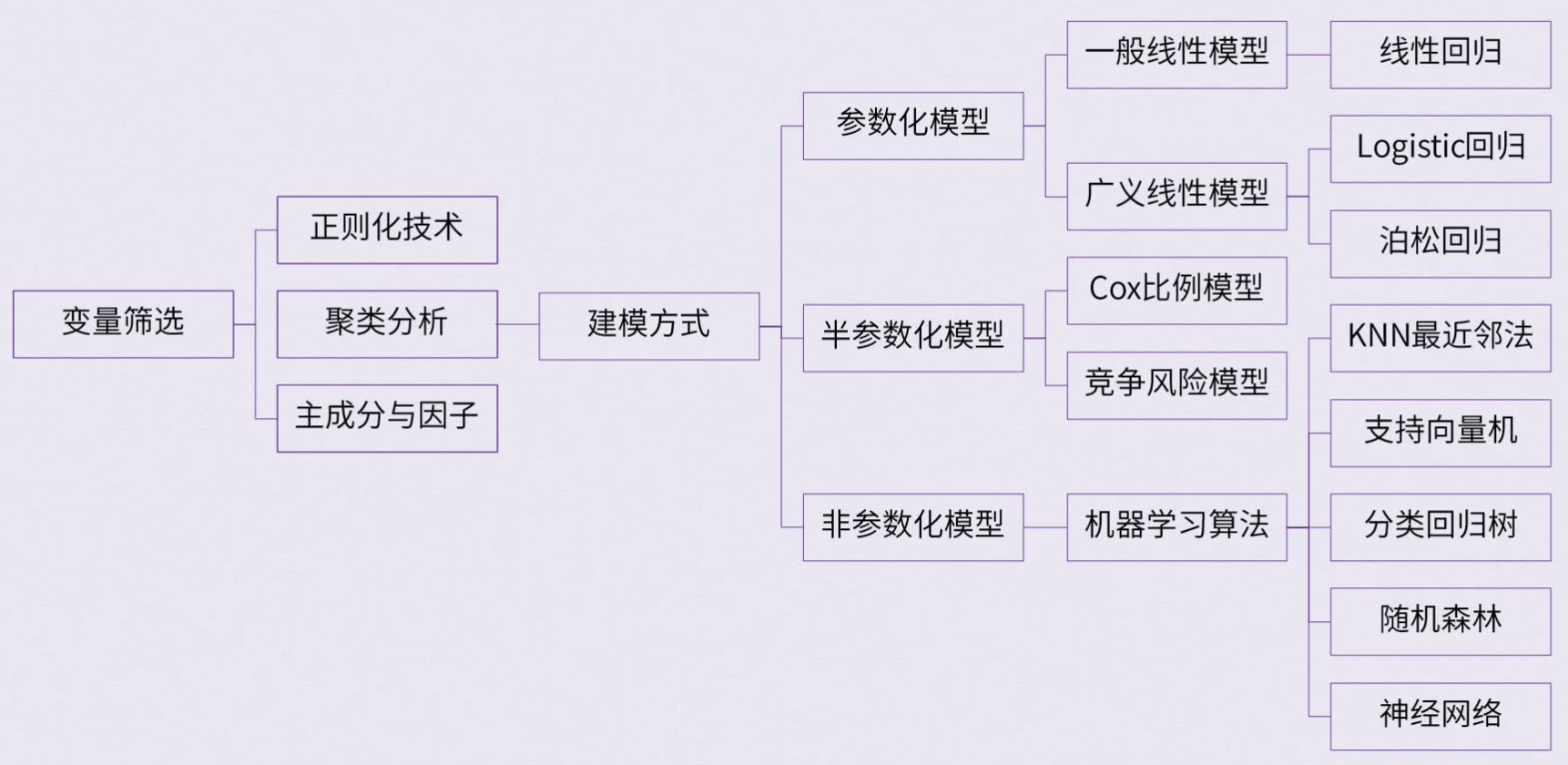
参数化方法:线性模型、广义线性模型、logistic 回归半参数化方法:竞争风险模型、cox 回归非参数化方法(没有回归系统,没有参数但可预测):机器学习(神经网络、随机森林、决策树…)
决策树(Decision Tree)是一种非参数的有监督学习方法,非参数指不限制数据的结构和类型,有监督学习则指必须具有标签。决策树能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现,可用于解决分类和回归问题,其算法本质是一种图结构。其他以树模型为核心的集成算法还有随机森林、AdaBoost。以上为基于西瓜好坏问题构建的决策树,其中最初问题所在地方为根结点(没有进边,有出边,包