




- @hxx688
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Claude Code 没有长期记忆,每次新会话项目上下文归零。本文记录在本地搭建双重记忆引擎的完整实践:用memory-engine(LanceDB + Weibull 衰减 + 混合检索)做会话级持久记忆,用 OpenViking做项目知识库检索,Ollama 本地提供Embedding。三层架构实现跨会话记忆召回、项目隔离、自动捕获,零云端依赖,附踩坑记录和实测数据。
1. Ceph封装与自动化装配创建ceph-starter自动化工程:创建一个spring boot工程,作为一个公用组件。pom文件依赖:<dependencies><!-- Spring Boot 自定义启动器的依赖 --><dependency><groupId>org.springframework.boot</groupId>&
1.扩容后的部署架构由之前的双主两台节点, 扩充为两对双主, 共四个节点:2. 新增数据库VIP在Server2节点上增加虚拟IP配置:修改/etc/keepalived/keepalived.conf,追加:...vrrp_instance VI_2 {#vrrp实例定义state BACKUP#lvs的状态模式,MASTER代表主, BACKUP代表备份节点interface ens33
1. ShardingJDBC的集成配置POM依赖配置<dependencies><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided<
一、如何优化多字段查询1. 提升字段查询得分:将title字段查询比重提升10倍:GET /movies/_search{"explain": true,"query":{"multi_match":{"query": "good hearts sea","fields": [&
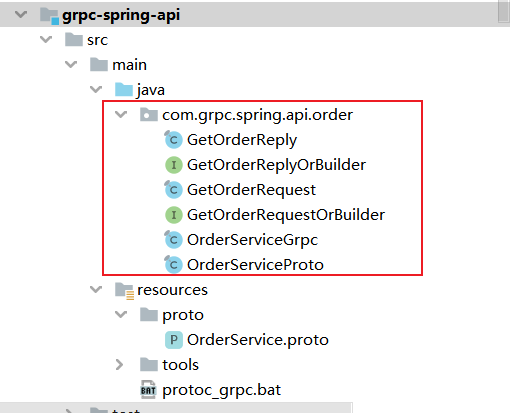
一、首先声明gRPC接口这里引入的是最新的gRpc-core 1.37版本, 采用的grcp-spring-boot-starter封装的版本进行实现,github地址:https://github.com/yidongnan/grpc-spring-boot-starter要实现gRpc通讯, 先定义接口以及入参出参信息syntax = "proto3";option java_multiple
1. 目标掌握Postgresql数据库主从部署搭建配置2. 脉络部署规划PostgreSQL单节点安装PostgreSQL主从部署配置主从同步验证3. 知行3.1简介PostgreSQL是一个比较高性能的数据库, 结合PostGIS插件, 使PostgreSQL成为了一个空间数据库,能够进行空间数据管理、数量测量与几何拓扑分析。PostgreSQL从9.3开始支持J...
这里ununtu系统使用的是11.10版本, 如果是用虚拟机, 建议使用vmware 6.5以后的版本安装, 如果版本过旧, 安装的时候, 会一直出现IRQ错误. 系统安装完成后, 最好再更新下, 更新包会比较大, 不要使用自带的默认数据源, 速度会很慢, 有时也连不上, 打开[系统设置] – [软件源], 弹出界面后, 把[下载自]更换成其他站点, 163和cn99的都比较快. 最后,
随着移动设备终端用户数逐渐增多, 基于云服务的应用也越来越多, 微信, 通讯录同步等. 云计算SAAS模式在未来会有广阔的发展空间, 最近做了个OTA项目, 包含三个子项目, 客户端升级程序, 服务端同步平台和升级包管理平台. 下面结合实际, 讲下OTA服务端同步平台的实现.1. 先说下业务背景需求, OTA可以自动或手动升级, 需要支持FU(系统固件)和AU(应用程序)的升级.并且可以进
1.背景Ceph是一个去中心化的分布式存储系统, 提供较好的性能、可靠性和可扩展性。Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区, 遵循LGPL协议。在经过了数年的发展之后,目前已得到众多云计算厂商(OpenStack、CloudStack、OpenNebula、Hadoop)的支持并被广泛应用。2. 介绍Ceph是一个可靠、自动重均衡、自动