




- @hh1357102
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用opencv进行读取:from torch.utils.data import Dataset,DataLoader,Subset,random_splitimport refrom functools import reducefrom torch.utils.tensorboard import SummaryWriter as Writerfrom torchvision import
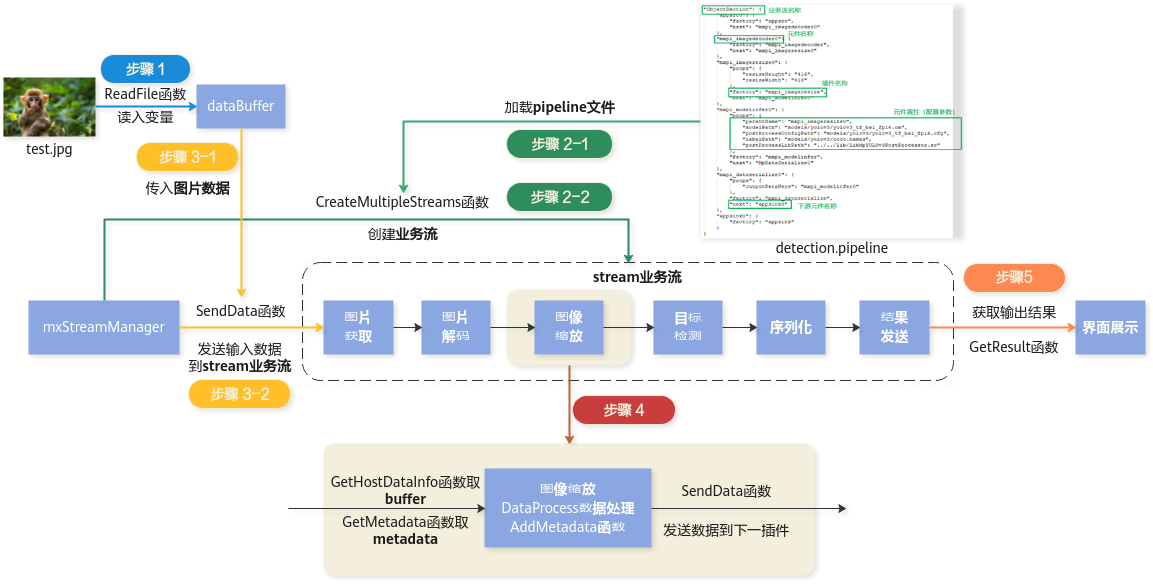
MindX是一款针对昇腾系列AI芯片的软件开发工具包(SDK),它提供了一系列的API和工具,帮助开发者对昇腾系列AI芯片进行开发和优化。提供了一系列的部署工具,可以将优化后的AI模型部署到昇腾AI芯片上,进行实时推理,实现低延迟、高性能的AI应用。其突出特点是使用流程编排进行开发。总的来说,MindX SDK为开发者提供了一套完整的开发环境和工具,帮助开发者轻松地进行昇腾系列AI芯片的开发、优化
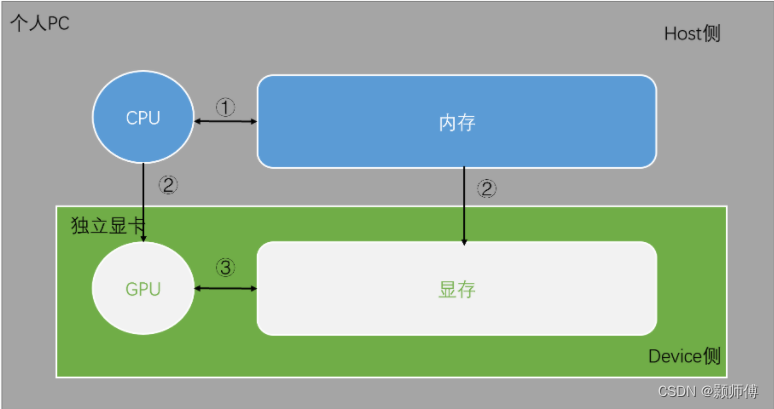
因此,在Atlas200DK上运行推理应用时,进程是在NPU上启动的,数据也是直接加载到Device内存中的,没有Host侧的参与,因此不存在Host->Device的数据传输过程。需要注意的是,使用aclrtMallocHost申请的内存必须由aclrtFreeHost来释放,二者是强对应的,不能用于其他内存。它的实际含义是“申请本端内存”,也就是说,如果进程运行在Host上,它将申请Host内
分为正负样本不均衡、难易样本不均衡及类别间样本不均衡问题。目标检测沿用了分类的思想,故目标检测继承了分类问题的样本不均衡情况。正负样本不均衡:Faster Rcnn,一共生成20000个框,但一张图物体数量可能只有10个,即正样本只在90左右,其余均为负样本。这样,正样本的损失在损失函数之中,无法得到很好的体现。难易不均衡问题:结合样本的正负,可以分为难正(错分为负样本的正样本)、难负、易正及易负
1.对于是否正确预测,只用看T或F:预测值为正例,记为P(Positive)预测值为反例,记为N(Negative)预测值与真实值相同,记为T(True)预测值与真实值相反,记为F(False)2.精确度:所有预测为正例中,正确预测的比例:P=TP/NP+TP3.正确率:所有预测结果中,正确的概率:很少用到A= (TP+TN)/(TP+TN+FP+FN)4.召回率:有多少正例最终被预测出:(真实的
网络能检测多尺度物体,其实体现了网络拟合的尺度不变性当预训练模型在imagenet上进行训练(224x224分类任务),以此为基础参数训练目标检测模型,会导致领域偏移。即是待检测对象,或待分类对象相同,但是对象被表现的方式不同。1.减少池化层,降低网络采样率,可以减少物体的信息损失,池化层可用dilation为2的空洞卷积代替。2.在有锚算法时,针对性设计Anchor。如果采用手工设计,可以使设计
非极大值抑制问题,解决同一个物体有多于一个候选框输出的问题。NMS用于过滤掉重叠的候选框。(1)算法输入:包含各框的位置坐标,以及置信度得分(2)算法步骤:设定IOU阈值,比如0.7。所有边框按照置信度进行排序,取得分最高的边框并保存,使其与其余边框计算IOU,去掉计算结果中大于0.7的结果。对于剩下的结果再度计算,直至所有边框消失。存在问题:(1)强制去掉得分较低的边框,影响召回率。(2)IOU
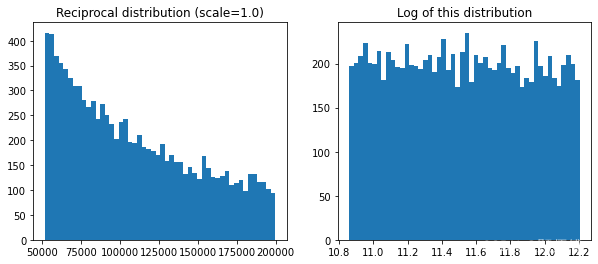
综上,最优参数取值较为确定时,使用geom或expon,不确定时使用reciprocal。2.几何的离散分布及指数分布。
文章目录一、基本概念二、opencv中的人脸识别结构三、LBP分类特征二、使用步骤置信区间概念一、基本概念对于二类分类问题,这些训练数据包括正样本和负样本,其中正样本代表属于该类别的实例,而负样本代表不属于该类型的反例。机器学习的第一步是要找到一种模型,可以用简洁又有差异性的方式准确地反映每幅图像的内容。换言之,机器学习方法,和图像特征是相互独立的。机器学习,是模型的训练方法,而特征,是训练的原始
qt样式不生效,一个是看全部样式代码是否都在最顶端控件,其二看相关UI文件,找到new出的新类的位置,看新类被new出的位置,看是否有被新的setstylesheet覆盖掉。