




- @hawk2014bj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
RunPod 可以支持大显存需求的模型,将 Runpod 镜像下载到本地先调试好,例如需要的类库等等,这样可以省时间,有很多平台的都 提供 GPU 租赁,原理都是相似的,就看哪家更便宜些,国内的算力平台更便宜,就是英伟达的卡不好租。

Ollama 使用时要特别注意分词器和 ChatTemplate, 否则对于语言模型输出结果会产生异常,对于 Embedding 模型会出现转换错误。

TailwindCSS 是一个套 CSS 的工具类,把常用的功能都进行了定义,下面是一个官网的例子,可以看到Tailwind对一元页面素写了很多类,日常开发中只要定义一两个类就可以搞定类似的功能了。我觉得这个库用起来门槛不高,就是需要知道那些工具类名是什么意思,例如上面这段代码,p-6 是什么意思,我把主要的一些工具类型列出来了,可以参考一下。Tailwind 可以自定义主题,例如,padding
Debug 这里主要的问题还是端口,端口配置正确之后,一切问题迎刃而解。

向量数据库是 RAG 中的重要组件之一,文档索引会存储在向量数据库中,随着大模型的流行,感觉向量数据库也会持续发展,进一步提高性能。

RAG 在 Langchain 上的定义是,作为大语言模型最常用的场景就是问答系统,可以针对特别来源数据做问题回答,就是私有数据,这就是 RAG,英文全称是Retrieval Augmented Generation。就是对现有模型数据的增广,大语言模型都是在公众数据上训练,而且只是拿到了某一个时间点之前的数据。RAG 是数据增广,也可以说是数据过滤,按照今天大模型的发展,上下文的长度已经卷到20
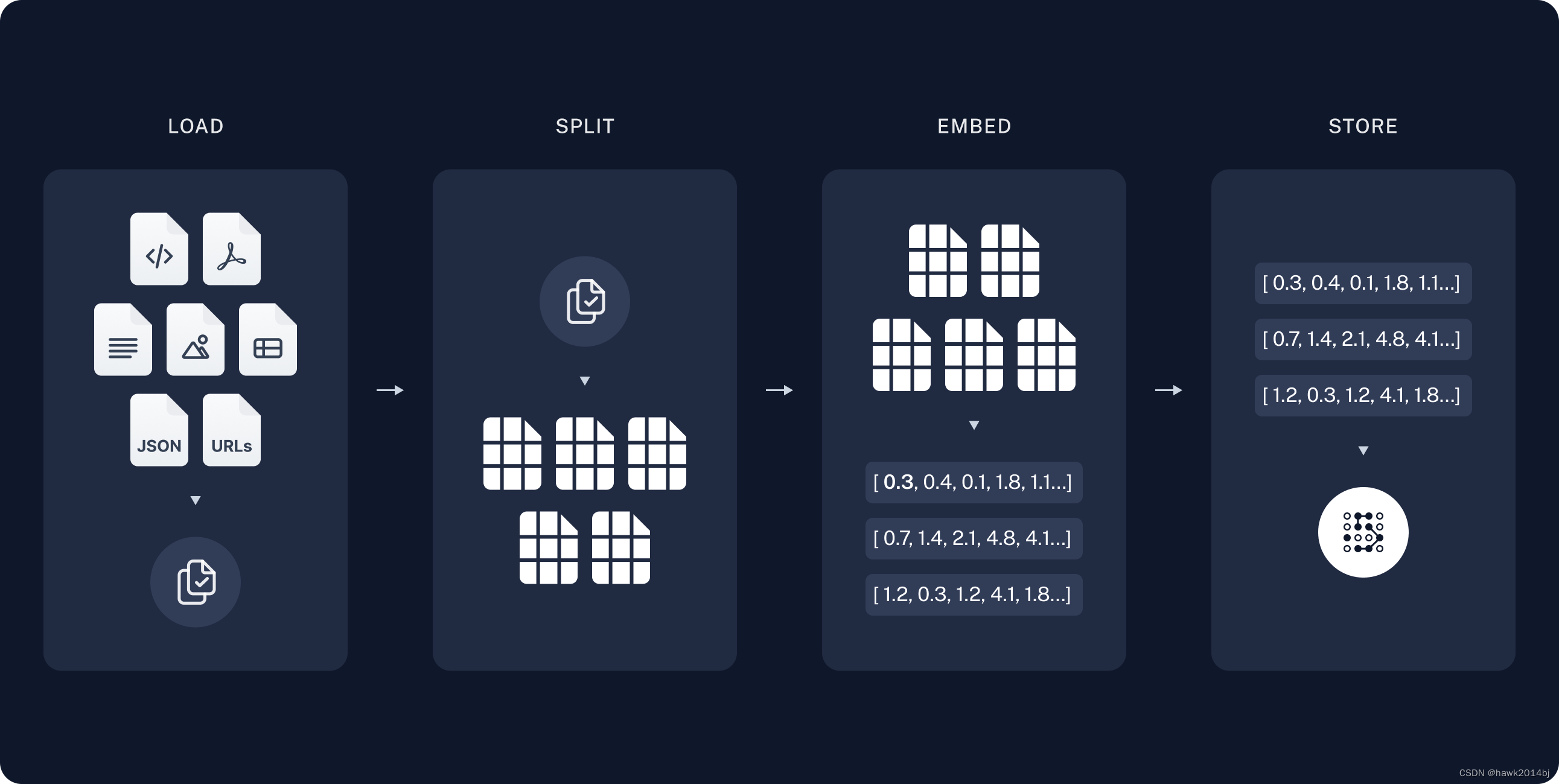
向量数据库是 RAG 中的重要组件之一,文档索引会存储在向量数据库中,随着大模型的流行,感觉向量数据库也会持续发展,进一步提高性能。
uv 是一个由 Rust 开发的 pip 工具,比 pip 快 100 倍,难以置信,不过真的是快太多了。

RAG 在 Langchain 上的定义是,作为大语言模型最常用的场景就是问答系统,可以针对特别来源数据做问题回答,就是私有数据,这就是 RAG,英文全称是Retrieval Augmented Generation。就是对现有模型数据的增广,大语言模型都是在公众数据上训练,而且只是拿到了某一个时间点之前的数据。RAG 是数据增广,也可以说是数据过滤,按照今天大模型的发展,上下文的长度已经卷到20