




- @gkoyu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
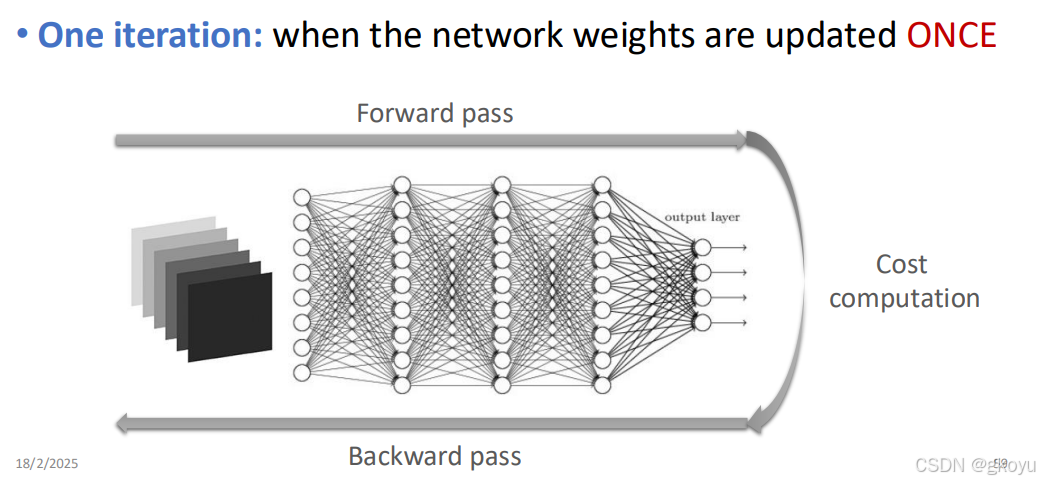
区分iteration&Batch size&Epoch
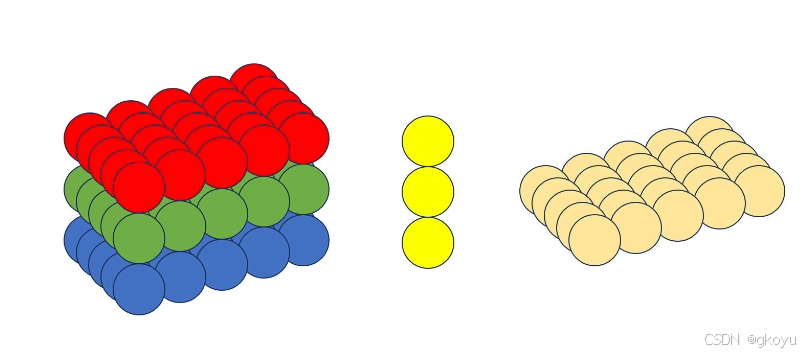
1×1卷积核在卷积神经网络(CNN)中扮演着关键角色,主要用于调整通道数、融合通道信息以及优化计算效率。
简洁来说:微调(Fine-tuning)是一种迁移学习(Transfer Learning)方法,它基于已经训练好的模型进行优化,使其在新任务或新数据集上表现更佳。通常,我们会从一个在大规模数据集上预训练的模型(如ImageNet上的ResNet、BERT等)出发,对其进行小规模的更新,使其适应特定应用。预训练模型(Pre-trained Model):利用已有的深度学习模型,该模型已经在大规模数
本博客将介绍深度学习工作中最常用的 Linux 指令,包括 环境管理、文件操作、数据处理、GPU 监控 等方面,并附带示例。

目录一、CLIP模型核心思想回顾二、分割任务中的CLIP1.LSeg 模型结构 意义 局限性2.GroupViT 核心思想 模型结构(1) 基础架构(2) Grouping Block编辑Zero-shot 推理实验编辑局限性与改进方向研究意义Vision LanguagedownstreamCLIP V1/V2CLIP(Contrastive Language–Image Pretraini
1×1卷积核在卷积神经网络(CNN)中扮演着关键角色,主要用于调整通道数、融合通道信息以及优化计算效率。
简洁来说:微调(Fine-tuning)是一种迁移学习(Transfer Learning)方法,它基于已经训练好的模型进行优化,使其在新任务或新数据集上表现更佳。通常,我们会从一个在大规模数据集上预训练的模型(如ImageNet上的ResNet、BERT等)出发,对其进行小规模的更新,使其适应特定应用。预训练模型(Pre-trained Model):利用已有的深度学习模型,该模型已经在大规模数
本博客将介绍深度学习工作中最常用的 Linux 指令,包括 环境管理、文件操作、数据处理、GPU 监控 等方面,并附带示例。
简洁来说:微调(Fine-tuning)是一种迁移学习(Transfer Learning)方法,它基于已经训练好的模型进行优化,使其在新任务或新数据集上表现更佳。通常,我们会从一个在大规模数据集上预训练的模型(如ImageNet上的ResNet、BERT等)出发,对其进行小规模的更新,使其适应特定应用。预训练模型(Pre-trained Model):利用已有的深度学习模型,该模型已经在大规模数