
写文章




- @github_39502869
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
深度学习基础篇 第一章:卷积
简要介绍卷积原理和实现。

第四章 模型篇:模型训练与示例
简要介绍了pytorch中模型训练的流程和部分原理知识。
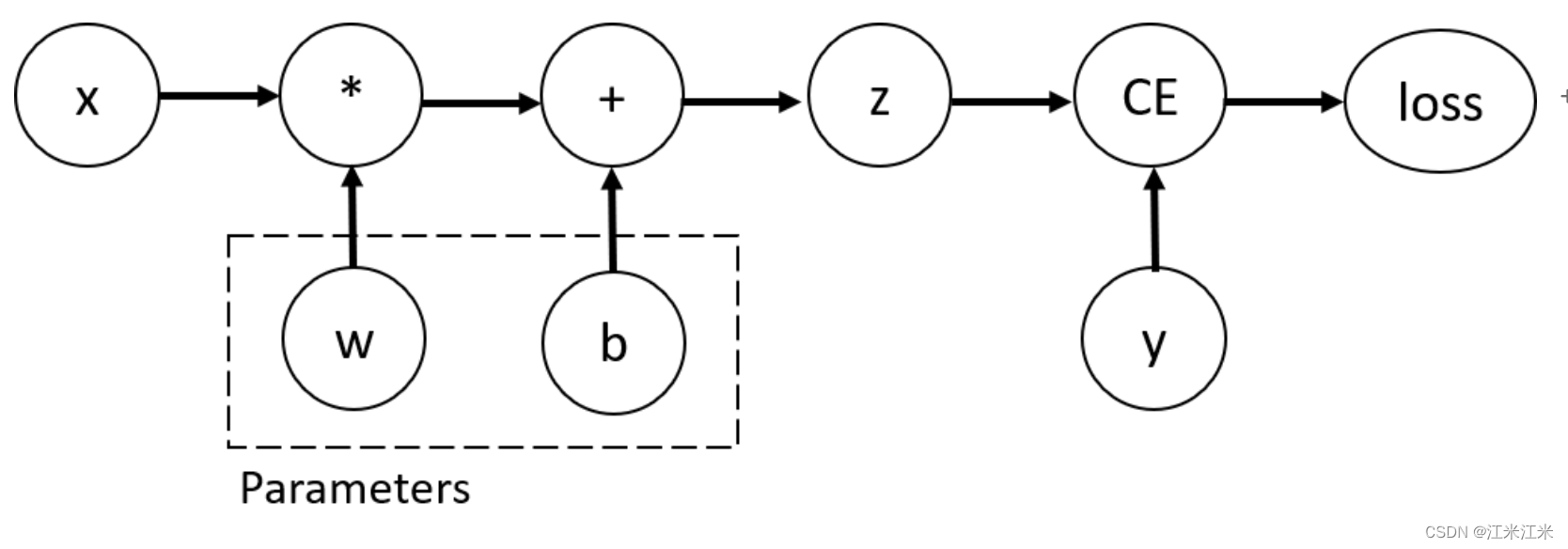
第四章 模型篇:模型训练与示例
简要介绍了pytorch中模型训练的流程和部分原理知识。
第十九章 番外篇:google-research《深度学习调参指南》
翻译 google-research: deep learning tuning playbook.
第二十章 原理篇:CLIP
简要介绍clip的原理和代码实现。

第六章 番外篇:webdataset
简要介绍了webdataset的使用。只介绍了基础用法,因为自己也没学明白。

小闹钟的机器学习笔记(1)
机器学习机器学习的目的是给出能自动识别数据模式的策略,并使用研究出的模式对数据或其他输出进行预测。目前机器学习主要分为以下两种类型:监督学习又称为预测学习,目的是在给定输入输出的情况下,研究从输入x到输入y的演变方法。输入x中包含的内容又称为属性、特征或者变量。x可以为很复杂的一个结构对象,比如说一张图片、一个句子、一段邮件等同样地,它的输出y也可以是任何类型。当y具有类...
到底了