- @friday1203
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本案例是基于LSTM架构,搭建一个文本情感分析模型,对评论内容进行二分类判断(正面或负面)。

六、模型效果评估前面讲过,最初我们建模的目的就是预测,最早人们使用的是传统的数理统计分析建模,这是一套完整的理论,是建立在基本假设、总体、样本、抽样、估计、检验等概念框架之上,有一系列完整的数学方法和和数理统计工具去计算统计量,进而得到总体规律而形成的统计模型,然后用模型来进行预测。但是,机器学习和深度学习是没有这一套系统的理论框架的,机器学习和深度学习更像是一个实证类方法,评估一个模型的好坏看预

因为每个点都不是孤立的,它都是和一些别的点有联系的,所以一个点的特征的变化是要受到和它有边相连的点的影响的。比如有的任务是求点的(比如对点进行分类、回归等任务),有的是求边的(比如对边进行分类、回归等任务),有的还是求全局的就是Graph级别的任务(比如设计分子结构等任务)。图是一个全局的概念。vi节点k跳远的邻接节点(neighbors with k-hop),指的是到节点vi走k步的节点(一个

本篇只讲如何使用gymnasium库中内置的游戏环境,并用Sarsa和Q-learning两种算法,展示出租车调度游戏案例。至于如何自定义强化学习环境,下一个篇章讲解。
基于AC框架的强化学习方法是当前强化学习中最流行、最普遍的方法。基于AC框架的算法也层出不穷,比如:A2C、PPO、TRPO等算法。

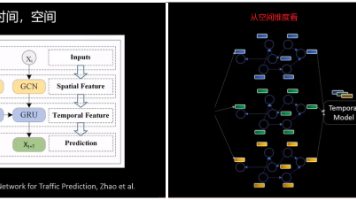
所以交通道路的图的节点和边一般不会变,变的只是随时间节点的特征在变化,比如节点的车流随时间在变化。比如行为识别-手势识别,从手部区域提取20个点,这20个基本就是手部的每个骨关节,把这20个点看作是节点,节点和节点之间的连接不会发生变化,但节点和节点之间的距离会随着手的姿势的变动而变动,就可以看作是节点的特征是时序变化的。另外一种是随着时间的推移,图中的节点的个数都已经发生了变化,也就是data.
从老虎机问题->强化学习算法

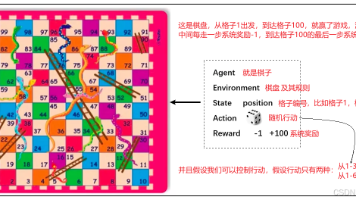
上一个篇章讲了如何使用gymnasium库中内置的游戏环境,本篇讲如何自定义环境,并用一个蛇棋的小游戏展示说明。
本篇的在轨MC控制、在轨算法:Sarsa、离轨算法Q-learning,这些算法的最终目标都是求最优策略的。本篇是DeepMind流派,或者说是强化学习鼻祖Rich Sutton和Andew Barto出版的强化学习那本书里的理论部分的最后一讲。所以本篇学完以后,你就可以把这些理论框架应用到实践过程中了。本篇之后我们开讲OpenAI流派,也就是深度强化学习。

本文系统介绍了图神经网络(GNN)中的核心层结构及其应用。重点解析了三种典型图卷积层:GCN(基于度矩阵加权)、GAT(引入注意力机制)和GraphSAGE(支持大规模图的采样聚合方法),详细阐述了它们的计算原理、特性差异及适用场景。同时深入讲解了TopKPooling剪枝池化层的工作原理,以及GAP/GMP全局池化层在图分类任务中的应用。