




- @feffsdsfdsfd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SFT(监督式微调)是大语言模型对齐流程的关键步骤,通过人工标注的"指令-回答"数据对预训练模型进行微调,使其从无目的文本续写升级为有意图的指令响应。本文基于Qwen2-0.5B-Instruct模型实现SFT微调,核心流程包括:1)格式化处理问答数据,使用模型专属分隔符拼接;2)复用预训练模型权重;3)仅计算回答部分的损失进行优化;4)适配训练参数以降低资源消耗。整个流程完整

BPE(Byte Pair Encoding)是一种从字符级别出发的子词分词算法,通过反复合并高频相邻二元组构建词表。本文介绍了简化版BPE的实现过程:1)训练阶段统计语料中字节对频次,按频次从高到低合并并记录规则;2)编码时将字符串转为字节后按训练顺序合并;3)解码时将token id序列还原为字节并拼接。代码包含get_stats统计频次、merge执行合并、build_vocab构建词表等核
本文介绍基于 RAG 的 PDF 问答 Demo,支持用户上传 PDF 后检索相关段落并结合大模型生成答案,核心技术栈含 Chroma 向量库、ChatZhipuAI 大模型、FastEmbedEmbeddings 文本嵌入。核心类 ChatPDF 封装文档入库、检索、问答全流程,通过 ingest () 建索引、ask () 实现问答,RAG 流程保障回答源自指定文档。使用前需配置并通过环境变量

本文介绍了一个基于多Agent协作思想的文章优化系统,通过将复杂任务分解为多个专业化Agent(主题分析、语言优化、内容丰富、可读性评价)分工处理,最后整合生成优化文章。系统采用"分而治之"的设计理念,各Agent聚焦专业领域,协同完成文章质量提升。详细阐述了系统架构、Agent分工和数据流,并提供了Python代码实现,展示了如何调用大语言模型接口完成各环节任务。该系统解决了
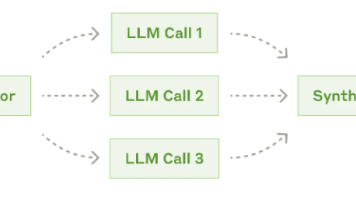
本文介绍了一个基于大语言模型Function Call能力的图书查询助手Agent实现。该Agent具备搜索图书、获取详情、查询借阅状态和预约借阅四大功能,通过工具函数与JSON Schema的配合实现智能响应。代码详解了四个核心工具函数(search_books、get_book_detail、check_availability、reserve_book)的实现逻辑,重点包括:参数验证、错误处
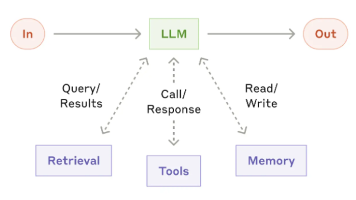
本文介绍了一个基于大语言模型的AI面试模拟系统实现方案。该系统使用阿里云DashScope平台的QWen-Turbo模型,通过Chat Completion接口实现自动化面试交互。系统特点包括:通过环境变量管理API密钥确保安全性;采用消息列表维护多轮对话上下文;实现健壮的异常处理机制;支持用户通过命令行与AI面试官进行连续问答。该系统为AI学习者提供了结构化的知识测试环境,解决了传统面试模拟的人

摘要:本文介绍了一个基于FastAPI框架和Hugging Face预训练模型distilgpt2的文本生成API开发方案。该服务通过HTTP POST接口接收用户prompt,调用轻量级GPT-2模型生成连贯文本,并返回结果。系统采用AutoTokenizer和AutoModelForCausalLM加载模型,支持GPU加速,通过beam search参数优化输出质量。API设计包含Pydant

本文演示了BERT模型中token、segment和position三种embedding的构造与相加流程。通过定义词表、初始化三个Embedding层,对输入序列的token、句子片段和位置信息分别进行编码,最终将三种embedding逐元素相加得到Transformer的输入表示。示例展示了一个包含[CLS]和[SEP]标记的典型BERT输入格式,输出为11×768维的矩阵,符合BERT Ba

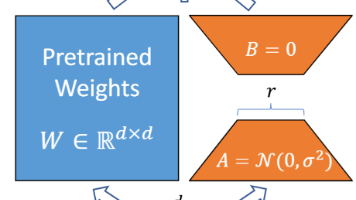
LoRA是一种参数高效微调方法,通过低秩分解大幅减少训练参数量,解决大模型全参数微调面临的显存占用高、训练效率低和过拟合风险等问题。其核心原理是在预训练权重矩阵W0上引入两个低秩矩阵A和B,通过W_new = W0 + (α/r)·AB实现参数更新,其中r≪n/m,显著降低训练成本。训练阶段采用未合并模式仅更新A/B矩阵,推理时可合并权重提升效率。代码实现需注意训练与推理的模式切换,并通过数值验证
本文介绍了一个基于LangChain框架的本地RAG问答系统,通过整合智谱GLM大模型、Embedding模型和LanceDB向量数据库,解决了大语言模型知识时效性不足的问题。系统从本地文本文件中提取信息,经过文本分割、向量化存储后,通过向量检索匹配用户问题,最终由GLM模型基于检索结果生成回答。核心流程包括数据预处理、向量存储、检索匹配和生成回答四个步骤,实现了私有数据的高效利用和精准问答。系统
