- @dege857
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2019 年底到 2020 年初,新冠疫情在中国爆发,为及时记录新冠疫情对中国中老年人生活和健康的影响,在 2020 年的第 5 轮调查中增加采集了疫情相关的信息。CHARLS 是一项具备中国大陆 45 岁及以上人群代表性的追踪调查,旨在建设一个高质量的公共微观数据库,采集的信息涵盖社会经济状况和健康状况等多维度的信息,以满足老龄科学研究的需要。原创不易,需要全套代码的粉丝,把公众号的本篇文章转发

这是一篇去年的比较新的文章,我查了下大概8.5分,文章大概就是介绍一种指数,叫做:甘油三酯葡萄糖-腰身高比指数(cumulative_TyG_WHtR),研究甘油三酯葡萄糖-腰身高比指数和新发心血管疾病的关系,作者搞了个K值聚类分析来把cumulative_TyG_WHtR指数分类,研究分类后指标和心血管疾病关系,这样类似的指数还有很多,比如TYG,WHtR,TyG_WHtR,目前这是一个发文的方

这是一个转移性胃癌患者(Power、Capanu、Kelsen 和 Shah 2011)的数据(公众号回复:胃癌数据,可以获得数据),数据很多我们选取一部分建模,age_dx:年龄,group:分组变量,分为存活率小于2年的和大于两年的,inv_weight:概率权重,ssize:每个分组患者的人数,survival生存时间,surv_cens生存结局。我们打开看一下,生成3个内容,newdat是

在nhanes数据库挖掘教程3中我们已经介绍了对nhanes数据的缺失值进行插补,本期主要介绍如何绘制如何对插补后的5个数据进行效应值合并,然后绘制多元性线性回归的限制立方样条图(RCS),并比较使用插补后的数据和直接删除数据对于绘图的影响和差别。地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx。因为我们需要合并5个数据的效应值,所以5个数据都需要
可以看出来,在验证集中Logistic 回归模型的AUC没有XGBoost 模型的高,到此我们已经完全复现了论文:何玉花, 周梦林, 徐建云,等. 应用机器学习方法建立大于胎龄儿预测模型[J]. 现代妇产科进展, 2019.的核心结果,感兴趣的可以自己取研究一下论文。在论文:何玉花, 周梦林, 徐建云,等. 应用机器学习方法建立大于胎龄儿预测模型[J]. 现代妇产科进展, 2019.中,还使用Lo
为利用国际上最佳的数据采集方式,并确保研究结果的国际可比性CHARLS 参照包括美国的健康与退休研究(HRS)在内的系列国际老龄调查研究开展调查设计。2019 年底到 2020 年初,新冠疫情在中国爆发,为及时记录新冠疫情对中国中老年人生活和健康的影响,在 2020 年的第 5 轮调查中增加采集了疫情相关的信息。CHARLS 是一项具备中国大陆 45 岁及以上人群代表性的追踪调查,旨在建设一个高质

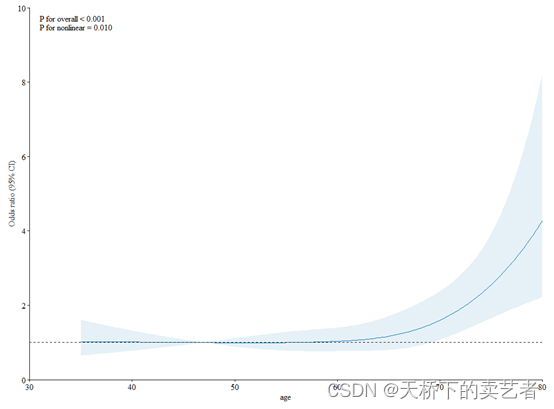
但是怎么做出来这个P for overall我是清楚的,有个R包叫plotRCS,这个包是可以生成出P for overall这个结果的,我就以这个包的方法来演示一下怎么做P for overall。文章到此结束啦,内容有点短,主要是最近有点头绪了,正在编写Nhanes数据,也就是复查加权数据的亚组交互效应函数(P for interaction),用于一键生成交互效应表,占用了部分时间,这个工程
北京大学主持的"中国老年健康调查(CLHLS)"是一项覆盖全国23个省市的长期追踪研究,1998-2018年间完成8次调查,累计入户访问11.3万人次,其中80岁以上高龄老人占67.4%。研究收集了老人健康、认知、社会参与及照料需求等丰富数据,并包含2.89万死亡老人临终前状况。调查数据已通过开放平台免费共享,被1万多位学者使用,产出大量学术成果。该数据集以sav格式存储,包含

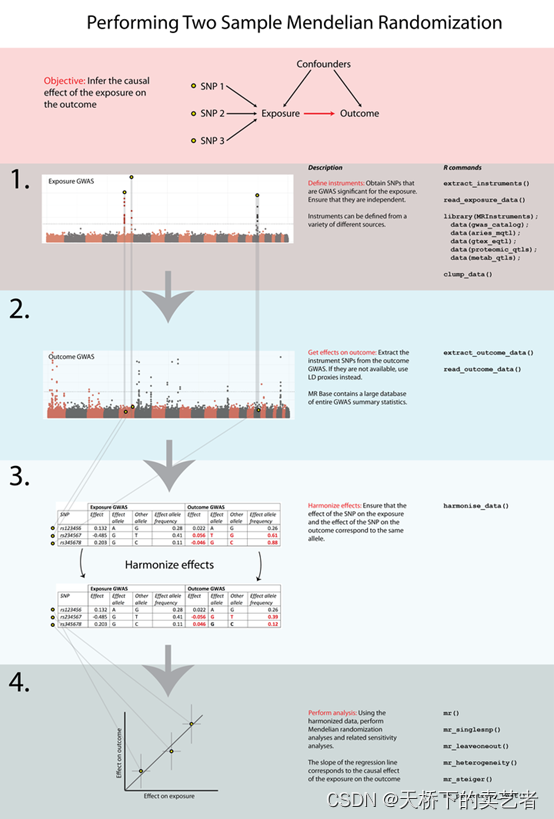
假设我们研究的想研究的原因变量有两个"ieu-a-22",“prot-b-66”,想研究的结局变量有3个"finn-b-O15_MEMBR_PREMAT_RUPT",“ukb-b-12621”,“finn-b-O15_PLAC_PREMAT_SEPAR”,如果我们一个一个的做也是要花费一定时间的,如果变量更多就需要更多时间了。然而这个函数也是有部分缺点的,第一就是它是通过在线下载数据,如果你的网络
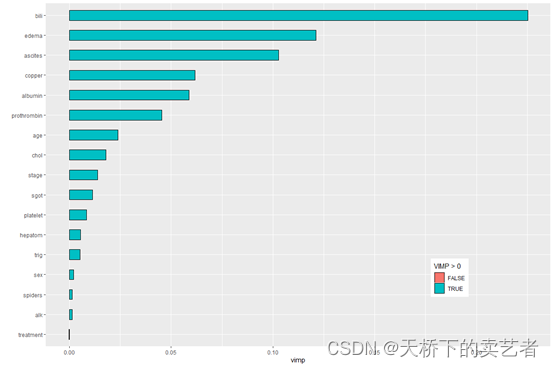
这是一个胆管炎数据(公众号回复:胆管炎数据2,可以获得数据),years:生存时间,status:结局指标,是否死亡,treatment是否DPCA治疗,age年龄,sex性别,ascites是否有腹水,hepatom是否有肝肿大,spiders是否有蜘蛛痣,edema水肿的级别,bili胆红素,chol胆固醇,albumin白蛋白,copper尿酮,alk碱性磷酸酶,sgot:SGOT评分,tr