




- @daydayup858
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
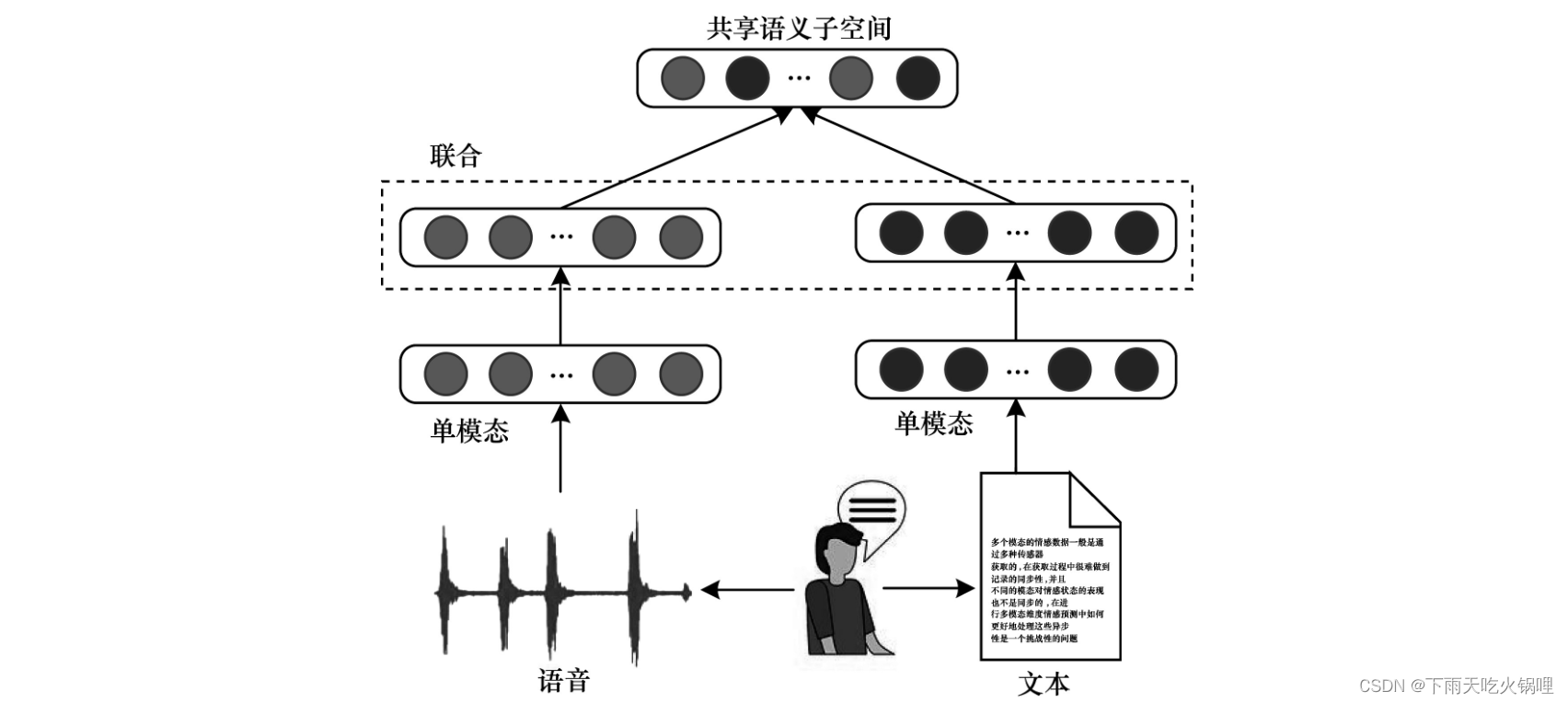
多模态融合的主要目标是缩小模态间的异质性差异,同时保持各模态特定语义的完整性,并在深度学习模型中取得较优的性能。
文本序列训练集、验证集和测试集(如CSV、JSON等)在这个示例中,(1代表正例,0代表负例)。每一行代表一个样本,第一列是输入数据,第二列是对应的标签。需要注意的是,具体的数据集格式可能会因任务类型、数据来源和使用的深度学习框架而有所不同。因此,在进行SFT训练时,建议根据具体任务和框架的要求来定义和处理数据集格式。

(这张图是AI生成的,看着还行~)

1.1 GEMM简介GEMM通用矩阵的矩阵乘法)是BLAS(Basic Linear Algebra Subprograms)库中的一个函数,用于实现矩阵与矩阵之间的乘法运算。BLAS库是一组用于执行基础线性代数运算的子程序库,包括向量加法、数乘、点积、矩阵相乘等。GEMM 的数学原理GEMM 的基本公式:如上图所示,简单来说,GEMM就是将两个矩阵相乘,得到一个输出矩阵的过程。m < M;k++
人脸识别Face Recognition综述
边缘计算设备与部署方案
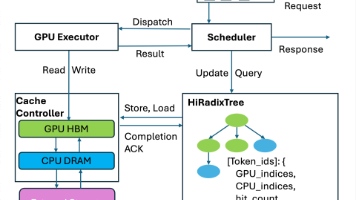
HiCache 是 SGLang 在 RadixAttention 基础上的分层 KV Cache 方案。它把 KV cache 组织成三层层级位置作用是否本地数据结构L1GPU 显存推理计算直接使用的 KV cache单实例/单 rank 私有L2CPU Host 内存,通常 pinned/registered扩大本地 cache 容量,作为 L1 与 L3 的中转层单实例/单 rank 私有L
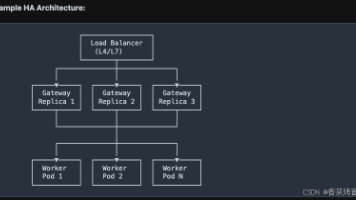
简单来说,SGLang Model Gateway 是一个高性能网关组件,负责统一对外提供 API 接口,在内部完成请求路由、负载均衡和服务调度,将推理请求分发到合适的后端模型实例,支持多模型、多节点部署,同时保证推理服务在高并发场景下的稳定性和可观测性。普通 Router 模式下,把一批同 Worker 交给 Router 管理,它只把请求分发给哪台机器,只有一个模型。系统,专为 SGLang
在大语言模型(LLM)推理中,预填充(Prefill)阶段往往是性能瓶颈:输入序列需先转换为 KV Cache,才能进行后续解码。当多个请求共享相同前缀时,对应的 KV Cache 完全一致,存在大量重复计算。为解决这一问题,SGLang 引入了 RadixAttention,利用空闲 GPU 内存缓存并复用前缀 KV Cache;进一步地,HiCache 将这一思路扩展至宿主机内存(Host M
简单来说,SGLang Model Gateway 是一个高性能网关组件,负责统一对外提供 API 接口,在内部完成请求路由、负载均衡和服务调度,将推理请求分发到合适的后端模型实例,支持多模型、多节点部署,同时保证推理服务在高并发场景下的稳定性和可观测性。普通 Router 模式下,把一批同 Worker 交给 Router 管理,它只把请求分发给哪台机器,只有一个模型。系统,专为 SGLang