
【收藏必学】图约束推理(GCR):消除大模型幻觉,实现知识图谱零样本迁移的新范式
Graph-constrained Reasoning (GCR)是一种新型框架,通过构建KG-Trie索引将知识图谱结构融入LLM解码过程,约束生成忠实于KG的推理路径,结合轻量级KG专用LLM生成推理路径与假设答案,再利用通用LLM进行归纳推理。该方法实现零幻觉、高精度的KG推理,在WebQSP、CWQ等数据集上表现优异,且能在未见KG上实现零样本迁移,准确率较纯LLM提升5%-8%,推理效率
文献速读
一、基本信息
- 标题:Graph-constrained Reasoning: Faithful Reasoning on Knowledge Graphs with Large Language Models
- 作者:Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Yuan-Fang Li, Chen Gong, Shirui Pan
- 关键词:Large language models (LLMs), Knowledge graphs (KGs), Faithful reasoning, Graph-constrained decoding, KG-Trie
二、文章概述
本文提出一种名为图约束推理(GCR)的新框架,旨在解决大型语言模型(LLMs)在知识图谱(KGs)推理中存在的知识缺口和幻觉问题。GCR通过构建KG-Trie索引将KG结构融入LLM解码过程,约束生成忠实于KG的推理路径,并结合轻量级KG专用LLM生成推理路径与假设答案,再利用通用LLM进行归纳推理,最终实现零幻觉、高精度的KG推理,且在未见KG上具有零样本迁移能力。
三、研究背景
LLMs虽具备强大推理能力,但因知识缺口和幻觉问题导致推理不可靠。知识图谱(KGs)作为结构化知识源被用于增强LLM推理,现有方法分为检索式和智能体式两类:检索式依赖外部检索器,泛化性差;智能体式需多轮交互,计算成本高。两类方法均存在幻觉问题,例如RoG模型推理中仍有33%的幻觉错误。因此,亟需一种能将KG结构与LLM推理深度融合、消除幻觉且高效的推理范式。
四、研究思路
- 提出研究问题:如何通过融合KG结构与LLM解码过程,消除推理幻觉并提升KG推理效率与准确性?
- 构建研究框架:设计GCR框架,包含KG-Trie构建(编码KG推理路径)、图约束解码(生成忠实路径)、归纳推理(整合多路径得出答案)三模块。
- 选择研究方法:采用KG-Trie索引约束LLM解码,结合轻量级KG专用LLM与通用LLM分工协作,通过beam search生成多路径,基于FiD框架归纳推理。
- 分析数据:在WebQSP、CWQ等KGQA数据集上评估性能,对比现有方法,分析效率、幻觉消除率及零样本迁移能力。
- 得出结论:GCR实现SOTA性能,零推理幻觉,高效且可零样本迁移至新KG。
五、研究结果
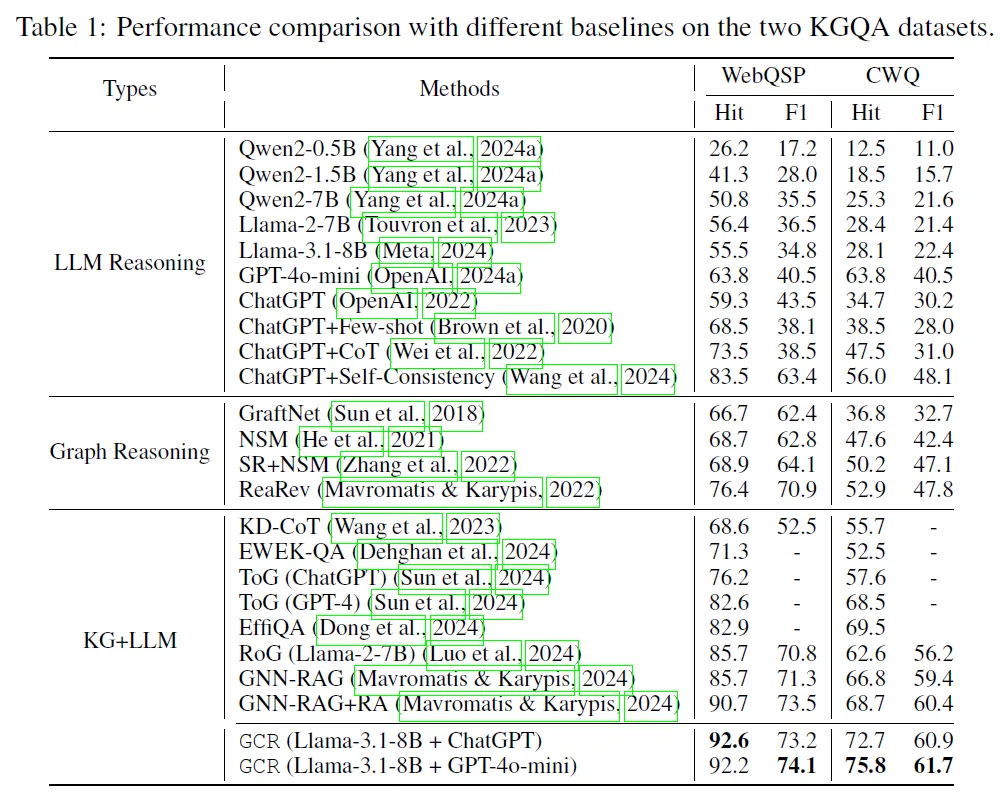
- 在WebQSP和CWQ数据集上,GCR(Llama-3.1-8B + GPT-4o-mini)的Hit指标分别达92.2%和75.8%,F1达74.1%和61.7%,超越现有KG增强LLM推理方法。
- 图约束解码确保100%推理路径忠实于KG,完全消除幻觉;移除约束后,WebQSP忠实推理率降至62.4%,CWQ降至48.1%。
- GCR在FreebaseQA、CSQA、MedQA等未见KG数据集上实现零样本迁移,准确率较纯LLM提升5%-8%。
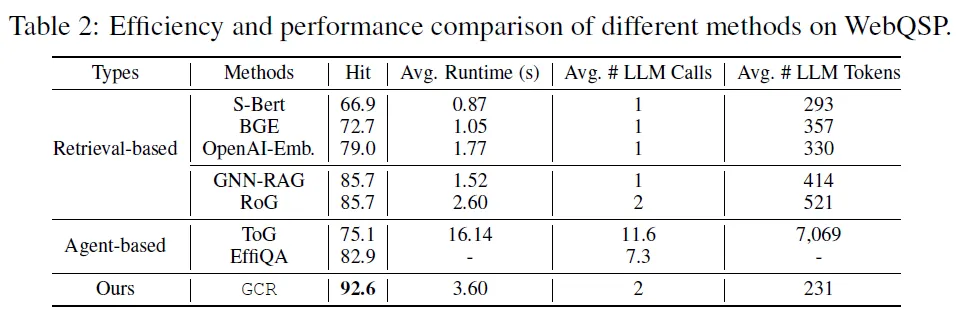
- 效率优于智能体式方法(如ToG平均耗时16.14秒/问),单LLM调用即可生成多路径,平均推理时间3.6秒/问,输入 tokens 数量显著减少。
六、研究结论、不足与展望
- 研究结论:GCR通过KG-Trie约束LLM解码过程,结合KG专用LLM与通用LLM的互补优势,实现了零幻觉、高精度的KG推理,在标准KGQA数据集上性能超越现有方法,并能零样本迁移至新KG,验证了其有效性与泛化性。
- 研究的创新性:1. 提出KG-Trie索引,将KG推理路径编码为前缀树,首次实现LLM解码过程的KG结构约束;2. 设计轻量级KG专用LLM与通用LLM协作范式,兼顾推理忠实性与归纳能力。
- 研究的不足之处:1. 零幻觉定义依赖KG自身正确性,若KG存在错误或缺失,会导致推理偏差;2. 复杂问题需长路径推理时,KG-Trie构建时间与空间成本增加;3. KG专用LLM可能生成无关路径,影响最终答案准确性。
- 研究展望:1. 融合多知识源(如Web数据、文档)交叉验证KG事实,提升推理鲁棒性;2. 结合规划方法分解复杂问题,降低长路径KG-Trie构建成本;3. 优化KG专用LLM路径生成相关性,引入路径质量评估机制;4. 扩展至动态KG与多模态知识融合场景。
- 研究意义:提出了一种结构化知识与LLM推理深度融合的新范式,为解决LLM幻觉问题提供有效途径,推动KG增强LLM推理在高精度、高可靠场景(如医疗、法律)的应用,同时为零样本知识迁移研究提供参考。

现有的大语言模型存在什么问题?
they still struggle with faithful reasoning due to knowl- edge gaps and hallucinations
现有的模型推理还是存在知识缺口和幻觉问题
大模型(LLMs)主要存在以下核心问题:
- 知识缺口与幻觉: 模型训练数据存在时效性和覆盖范围限制,导致对新兴知识或长尾领域的理解不足;推理过程中易生成看似合理但不符合事实的内容(“幻觉”),尤其在知识密集型任务中表现突出。
- 推理忠实性不足: 尽管具备链式推理能力,但推理过程常偏离事实依据,如生成未经验证的关联或虚构证据链,影响决策可靠性。
- 结构化知识利用困难: 难以直接整合知识图谱(KG)等结构化数据,现有检索增强或智能体交互方法存在检索准确性低、图谱遍历效率差等问题。
- 计算成本与效率瓶颈: 复杂推理任务需多轮交互或大规模检索,导致高延迟和资源消耗,难以满足实时应用需求。
这些问题在医疗、法律等对可靠性要求极高的领域尤为关键,推动了GCR等结合结构化知识约束的推理框架研究。
什么是KG-Trie?图约束推理(GCR)?
KG-Trie(字典树)
KG-Trie, a trie-based index that encodes KG reasoning paths
KG-Trie是一种基于前缀树(Trie)的数据结构,一种基于字典树的索引,用于将知识图谱(KG)中的推理路径编码为结构化索引。极大程度上压缩了字符串的存储效率,通过编码成Token字典树来压缩Token的消耗,并允许大型语言模型直接在图上进行推理,并生成基于知识图谱的忠实推理路径。
它通过以下步骤构建:
- 首先使用广度优先搜索(BFS) 从问题实体出发检索L跳内的推理路径
- 将这些路径格式化为字符串并通过LLM的分词器转换为token序列
- 最终构建为前缀树结构。
KG-Trie的核心作用是在LLM解码过程中施加约束,仅允许生成符合KG中有效路径前缀的token序列,从而确保推理路径忠实于知识图谱结构,消除幻觉推理。
该结构支持LLM在常数时间内高效遍历图路径,并可通过预构建或动态生成平衡预处理开销与推理效率,是GCR框架实现零幻觉推理的关键组件。
GCR(Graph-Constrained Reasoning,图约束推理)
graph- constrained reasoning (GCR), a novel framework that bridges structured knowledge in KGs with un- structured reasoning in LLMs.
GCR(Graph-Constrained Reasoning,图约束推理)是一种将知识图谱(KG)的结构化知识与大语言模型(LLM)的非结构化推理能力相结合的新型框架,从而实现准确推理,且无推理幻觉。
其核心创新在于通过 **KG-Trie(一种基于前缀树的索引结构)**将KG的推理路径编码为约束条件,直接集成到LLM的解码过程中,使LLM能够在生成推理路径时严格遵循KG的结构,从而生成忠实于KG的推理路径。

GCR的主要组件包括:
- KG-Trie构建:将KG中的推理路径转换为前缀树结构,作为LLM解码的约束索引,实现高效的图遍历。
- 图约束解码: 使用轻量级KG专用LLM,在KG-Trie约束下生成多条KG接地的推理路径和假设答案,确保推理路径的有效性。
- 图归纳推理: 将生成的多条推理路径输入到强大的通用LLM中,利用其归纳推理能力综合多条路径的证据,输出最终答案。 该框架通过结合KG专用LLM的图推理能力与通用LLM的归纳能力,实现了零推理幻觉、高精度推理,且在未见过的KG上具有零样本泛化能力。
GCR的实现原理
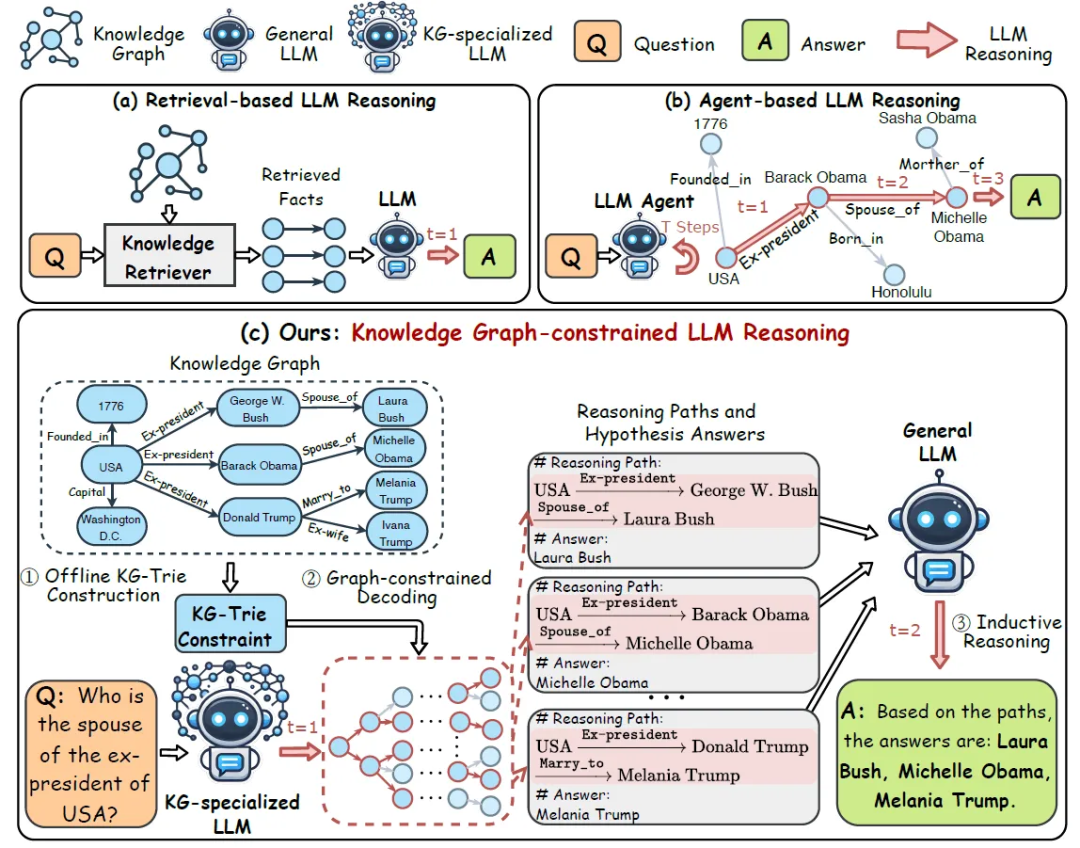
如上图c部分所示,GCR通过将知识图谱(KG)结构融入大语言模型(LLM)的解码过程,实现忠实推理。其核心步骤分为三部分:
- 知识图谱Trie(KG-Trie)构建
- 路径检索:针对输入问题中的实体,通过广度优先搜索(BFS)从KG中提取最多L跳的推理路径(如e0 →r1 →e1 →r2 →e2)。【其中:e代表实体,r代表关系】
- 路径格式化与编码: 将检索到的路径转换为结构化字符串(如 Justin Bieber →people.person.parents →Jeremy Bieber ),并通过LLM的分词器转换为 tokens。
- Trie索引构建: 使用Trie(前缀树)数据结构存储这些tokens,形成KG-Trie索引,用于约束LLM的解码过程。
- 图约束解码(Graph-Constrained Decoding)
- 轻量级KG专用LLM微调:训练一个轻量级LLM(如Llama-3.1-8B),使其能在KG-Trie约束下生成忠实于KG的推理路径。
- 解码约束: 在LLM生成推理路径时,通过KG-Trie检查每一步生成的token是否为有效路径前缀,仅允许生成KG中存在的路径。
- 假设答案生成: 路径生成完成后,切换至常规解码模式,基于路径生成假设答案。
- 图归纳推理(Graph Inductive Reasoning)
- 多路径生成: 通过束搜索(beam search)并行生成K条推理路径及假设答案(如K=10)。
- 通用LLM归纳推理: 将多路径和假设答案输入强通用LLM(如GPT-4o-mini),利用其归纳能力综合多条路径,输出最终答案。
Incorporating diverse reasoning paths would be beneficial for deliberate thinking and reasoning.
整合不同的推理路径将有助于审慎思考和推理
to take advantage of the GPU parallel computation. Thus, given a question, we adopt graph- constrained decoding to simultaneously generate K reason- ing paths and hypothesis answers with beam search in a single LLM call.
为了利用GPU并行计算, 因此,给定一个问题,我们采用图约束解码,在单次LLM调用中通过束搜索同时生成K条推理路径和假设答案。
GCR的优势
- 消除推理幻觉,确保忠实性通过KG-Trie直接约束LLM解码过程,确保生成的推理路径完全基于KG事实,实现“零推理幻觉”(实验中忠实推理率达100%)。
- 高效推理与低延迟 KG-Trie索引: 将KG路径压缩为Trie结构,支持常数时间复杂度(O(|Wz|))的路径检索,避免传统方法的多次KG遍历或检索开销。并行路径生成: 通过GPU并行计算,一次LLM调用即可生成多条路径,无需多轮交互(如Agent-based方法),平均推理时间仅3.6秒(WebQSP数据集)。
- 强泛化能力 零样本迁移至新KG: KG-Trie可动态适配新KG(如ConceptNet、医疗KG),无需额外训练即可在 unseen KGs 上推理(如MedQA数据集准确率提升4%)。
- 结合专用与通用LLM优势 轻量级KG专用LLM: 专注于KG路径搜索,减少噪声路径;通用LLM:通过归纳多路径提升答案准确性(如GPT-4o-mini综合10条路径后F1值达74.1%)。
- 性能超越现有方法在WebQSP和CWQ等KGQA基准上,GCR的Hit@1指标分别达92.6%和75.8%,超越GNN-RAG、RoG等SOTA方法。
总结: GCR通过KG-Trie约束解码与双LLM协作,实现了忠实性、高效性与泛化性的统一,为LLM结合结构化知识推理提供了新范式。
为什么具有推理能力的LLM还是必要的?
通用LLM在GCR框架中承担关键的归纳推理角色。具体表现为:
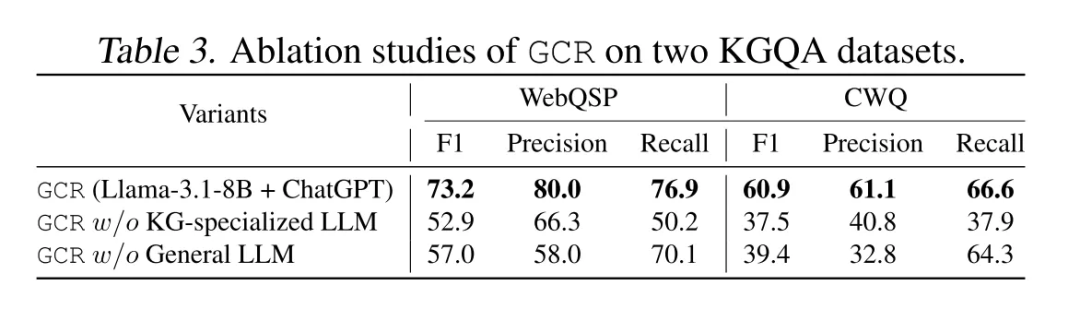
- 多路径整合能力: KG-specialized LLM生成的多条推理路径可能包含噪声或冗余信息,通用LLM通过归纳推理整合这些路径,提升答案准确性。例如在WebQSP数据集上,移除通用LLM会导致F1分数从73.2降至57.0, precision显著下降(表3)。
- 复杂语义理解: 通用LLM凭借强大的自然语言理解能力,能处理KG-Trie索引未覆盖的复杂问题。如在CWQ数据集上,仅使用KG-specialized LLM的假设答案会因路径语义歧义导致precision仅32.8(表3)。
- 零样本泛化支持: 在跨KG迁移实验中(如从Freebase到ConceptNet),通用LLM无需额外训练即可适配新领域知识,使GCR在CSQA数据集上准确率 提升7.6% (表6)。

需要强调的是,GCR通过 “轻量级KG-specialized LLM路径生成+通用LLM归纳推理” 的双模型架构。既解决了LLM的事实幻觉问题,又保留了其复杂推理优势,实现零推理幻觉与高精度的平衡。
实验结论
表4的结果表明,轻量级大型语言模型**(0.5B)在微调后性能可以超过大型语言模型(70B)**,这说明微调在增强大型语言模型能力并使其专门用于知识图谱推理方面是有效的。
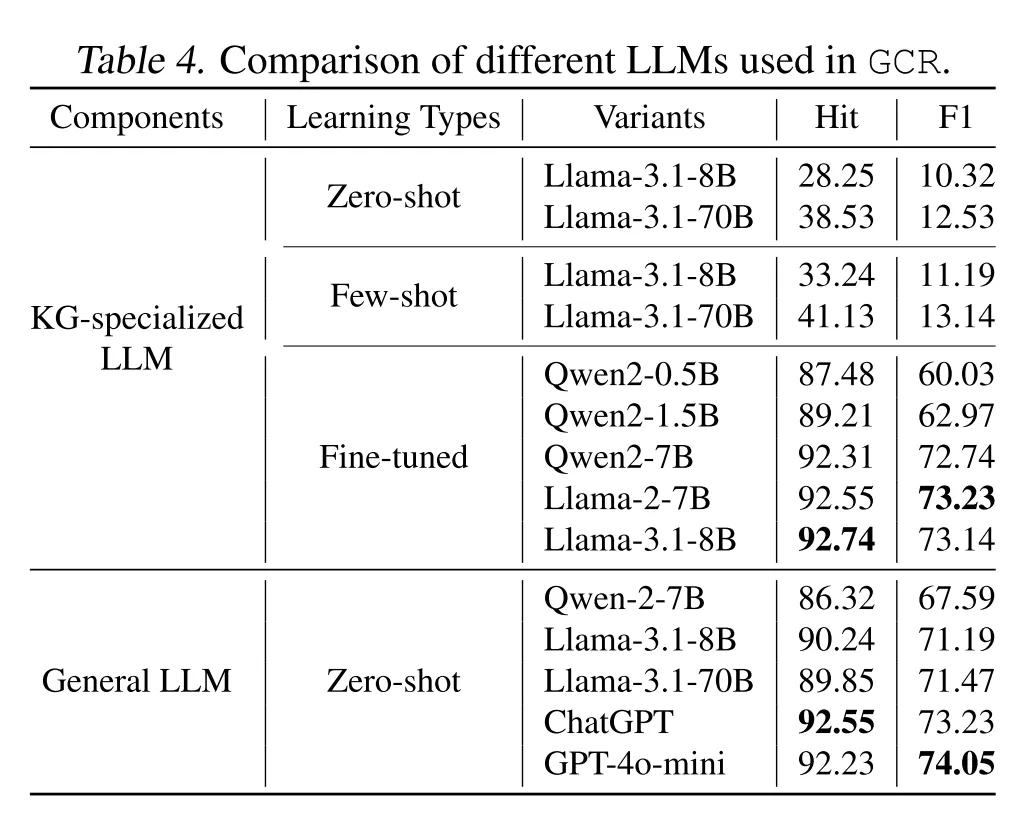
因此将强大的通用大型语言模型(LLMs)与轻量级知识图谱专用大型语言模型相结合,就可以实现由两者共同驱动的更好推理模型。并且GCR能够很好平衡推理能力和效率问题,通过施加约束,不仅可以消除推理中的幻觉,还能降低推理复杂度,从而实现更高效、更准确的推理。
具体的对比主流推理模型的得分情况如下图所示:

如何安装使用GCR
https://github.com/RManLuo/graph-constrained-reasoning
简要步骤如下:
- 拉仓库
git clone https://github.com/RManLuo/graph-constrained-reasoning.git
- 安装依赖
安装Flash-attention进行快速解码
pip install flash-attn --no-build-isolation
- 构建图索引
建立用于训练的图形索引:scripts/build_graph_index.sh
图形索引将保存在:data/graph_index。
DATA_PATH="RoG-webqsp RoG-cwq"SPLIT=testN_PROCESS=8HOP=2 # 3for DATA_PATH in ${DATA_PATH}; do python workflow/build_graph_index.py --d ${DATA_PATH} --split ${SPLIT} --n ${N_PROCESS} --K ${HOP}done
- 训练轻量级KG专业LLM
在脚本中,我们提供了以下模型配置:Qwen2-0.5B/1.5B/7B、Llama-2-7B和Llama-3.1-8B。但它可以轻松扩展到其他LLM。
取消注释相应的“模型配置块”(默认为Llama-3.1-8B)并运行脚本:scripts/train_kg_specialized_llm.sh。
模型将保存在:save_models/${SAVE_NAME}。
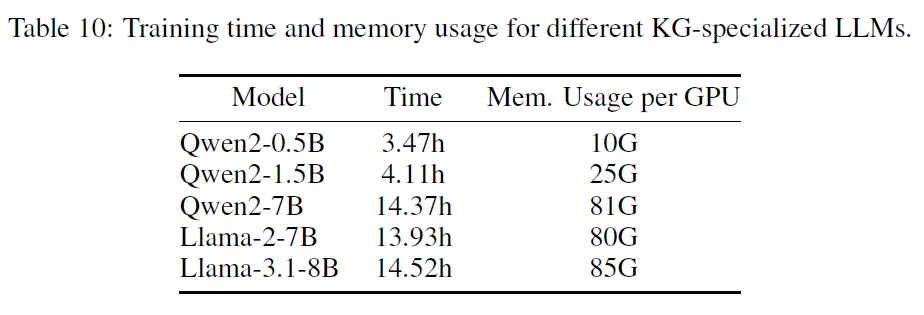
各模型配置的训练资源及时间如下:
- 推理
运行脚本:scripts/graph_constrained_decoding.sh
MODEL_PATH=rmanluo/GCR-Meta-Llama-3.1-8B-InstructMODEL_NAME=$(basename "$MODEL_PATH")python workflow/predict_paths_and_answers.py \ --data_path rmanluo \ --d {RoG-webqsp,RoG-cwq} \ --split test \ --index_path_length 2 \ --model_name ${MODEL_NAME} \ --model_path ${MODEL_PATH} \ --k 10 \ --prompt_mode zero-shot \ --generation_mode group-beam \ --attn_implementation flash_attention_2
生成的推理路径和假设答案将保存在:results/GenPaths/{dataset}/{model_name}/{split}。
- 归纳推理图
我们使用通用的 LLM 对多个推理路径和假设答案进行推理,以产生最终答案,而无需额外的训练。 运行:scripts/graph_inductive_reasoning.sh
python workflow/predict_final_answer.py \ --data_path rmanluo \ --d {RoG-webqsp,RoG-cwq} \ --split test \ --model_name {gpt-3.5-turbo, gpt-4o-mini} \ --reasoning_path {REASONING_PATH} \ --add_path True \ -n 10
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐

 18
18 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)