




- @boydfd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
看到这原因的就很明显了,因为这个EOS添加的是字符,而不是token_id,所以tokenizer有时候会把当成了分开的token,比如,模型就把这3它当成了三个token,而不是一个token,所以在推理的时候,遇到结尾,有时候就会输出。如果以为例,一般模型在推理的时候,觉得可以结束一句话了,就会输出,但是模型的脑子里肯定没有的概念呀,它只能输出数字,所以我们需要把转换成数字,这个数字就是EOS

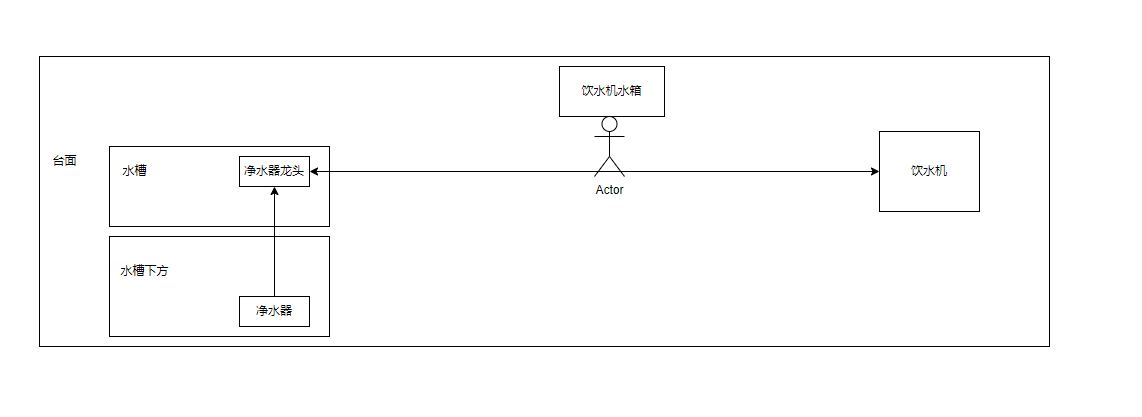
这篇博客讲述了作者在家庭日常用水管理方面的改进经历。由于家里用水量增多,作者不断优化解决方案,从最初用农夫山泉桶装水,到购买反渗透净水机,再到通过智能化手段 简化补水流程。过程中,作者不断提高设备自动化程度,最终实现了全自动化补水,并且详尽描述了每个优化步骤和使用的技术(如Node-RED、homeassistant、小米设备等)。此外,作者还介绍了如何利用压力传感器和智能控制来实现更精确的水量控
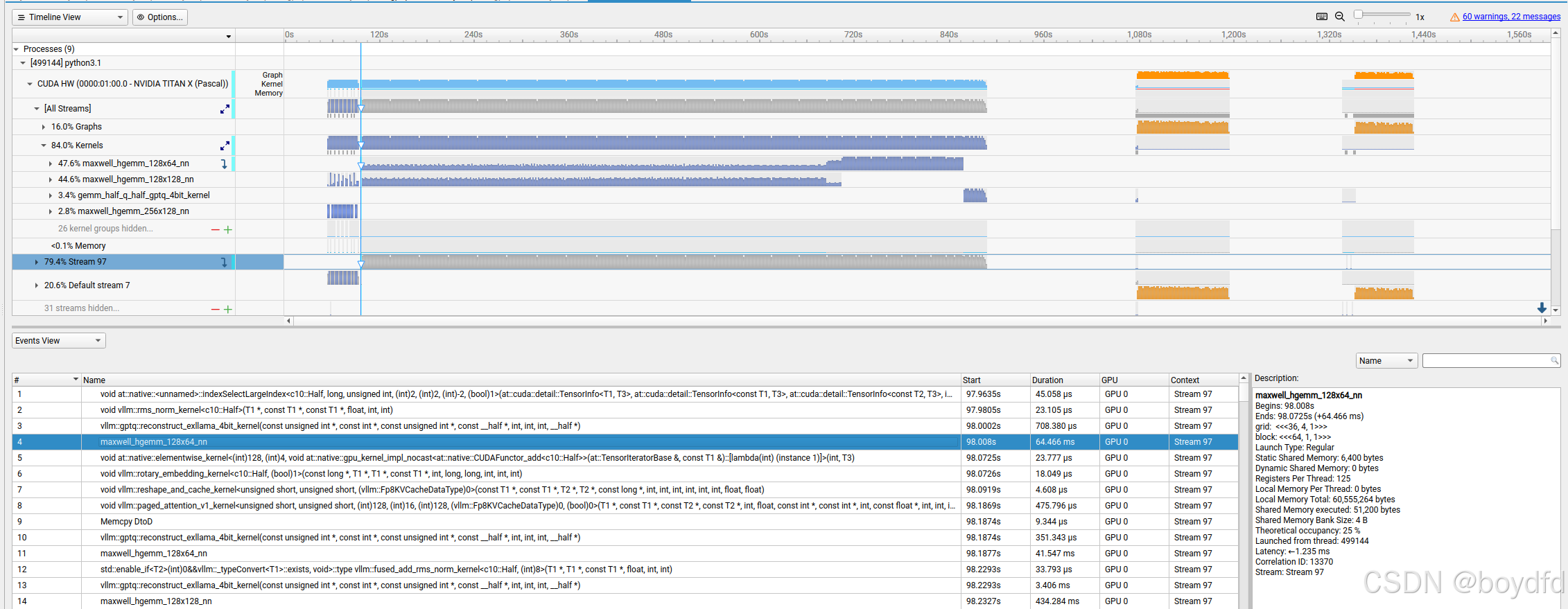
这篇博客记录了作者在家中使用Pascal显卡运行大型模型时遇到的挑战和解决方案。随着本地大型模型性能的提升,作者选择使用vllm库进行推理。然而,作者遇到了多个技术难题,需要自行编译vllm和PyTorch,以支持Pascal架构的显卡。编译过程中,作者深入研究了显卡不支持的问题,特别是在量化矩阵乘法计算中发现性能瓶颈。最终,解决了性能问题,让性能提升了43倍。这次技术探索不仅解决了具体问题,还为
看到这原因的就很明显了,因为这个EOS添加的是字符,而不是token_id,所以tokenizer有时候会把当成了分开的token,比如,模型就把这3它当成了三个token,而不是一个token,所以在推理的时候,遇到结尾,有时候就会输出。如果以为例,一般模型在推理的时候,觉得可以结束一句话了,就会输出,但是模型的脑子里肯定没有的概念呀,它只能输出数字,所以我们需要把转换成数字,这个数字就是EOS
为了解决OpenClaw使用中的痛点问题,我开发了一个开源Dashboard工具,主要功能包括:1)实时监控Agent状态和任务执行情况;2)提供直观的会话和模型调用追踪;3)引入Blueprint模板系统实现批量Agent管理;4)增加版本控制确保修改可追溯;5)优化移动端适配。该工具已在GitHub开源,旨在提升OpenClaw的使用体验和工作效率。
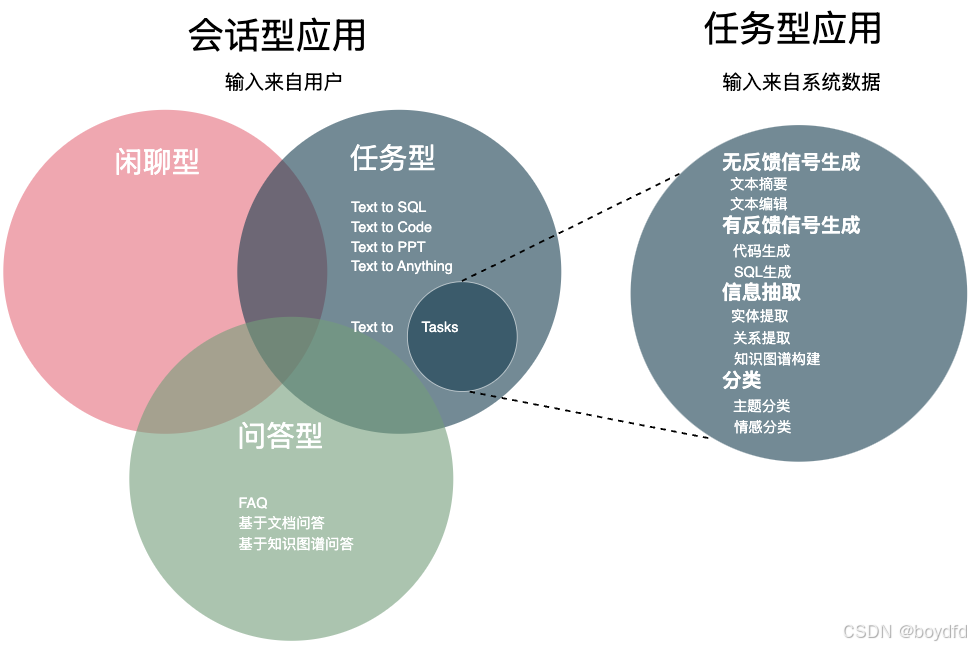
自ChatGPT诞生以来,各个企业都开始尝试引入LLM落地实施“智能”应用,而目前并没有太多文章系统地介绍应该怎么落地实施一个基于LLM的应用,到底应该做哪些步骤。本人从2023年12月份开始,陆陆续续开发了3个LLM应用的项目了。这几个项目都是会话型的应用,都借助了LLM的能力,所以想趁着记忆还算新鲜,来总结一下这类项目的一些落地实施经验。最后面我会以最近的一个项目做的事情来作为案例,供大家学习
这篇博客记录了作者在家中使用Pascal显卡运行大型模型时遇到的挑战和解决方案。随着本地大型模型性能的提升,作者选择使用vllm库进行推理。然而,作者遇到了多个技术难题,需要自行编译vllm和PyTorch,以支持Pascal架构的显卡。编译过程中,作者深入研究了显卡不支持的问题,特别是在量化矩阵乘法计算中发现性能瓶颈。最终,解决了性能问题,让性能提升了43倍。这次技术探索不仅解决了具体问题,还为
看到这原因的就很明显了,因为这个EOS添加的是字符,而不是token_id,所以tokenizer有时候会把当成了分开的token,比如,模型就把这3它当成了三个token,而不是一个token,所以在推理的时候,遇到结尾,有时候就会输出。如果以为例,一般模型在推理的时候,觉得可以结束一句话了,就会输出,但是模型的脑子里肯定没有的概念呀,它只能输出数字,所以我们需要把转换成数字,这个数字就是EOS