- @baidu_36913330
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要介绍如何将TGD特征嵌入神经网络,并提升神经网络分类的性能。

本篇实则是抛开 TGD 的理论,依靠视觉特征的直觉和过去深度学习的实践中,去理解 TGD 算子的正确性。并通过一些小实验验证TGD特征对神经网络解决视觉任务的重要性。

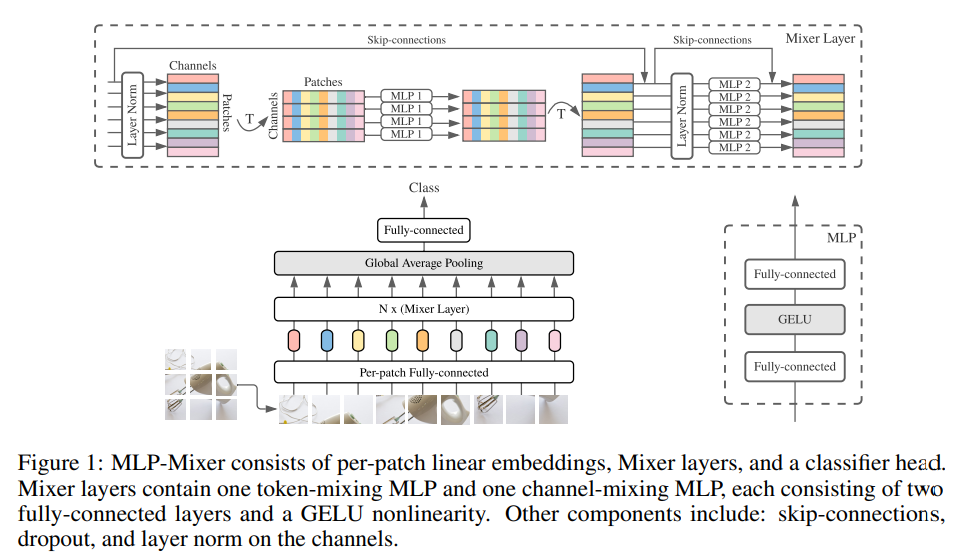
深度学习之图像分类(二十一)MLP-Mixer网络详解目录深度学习之图像分类(二十一)MLP-Mixer网络详解1. 前言2. MLP-Mixer 网络结构3. 总结4. 代码继 Transformer 之后,我们开启了一个新篇章,即无关卷积和注意力机制的最原始形态,全连接网络。在本章中我们学习全连接构成的 MLP-Mixer。(仔细发现,这个团队其实就是 ViT 团队…),作为一种“开创性”的工
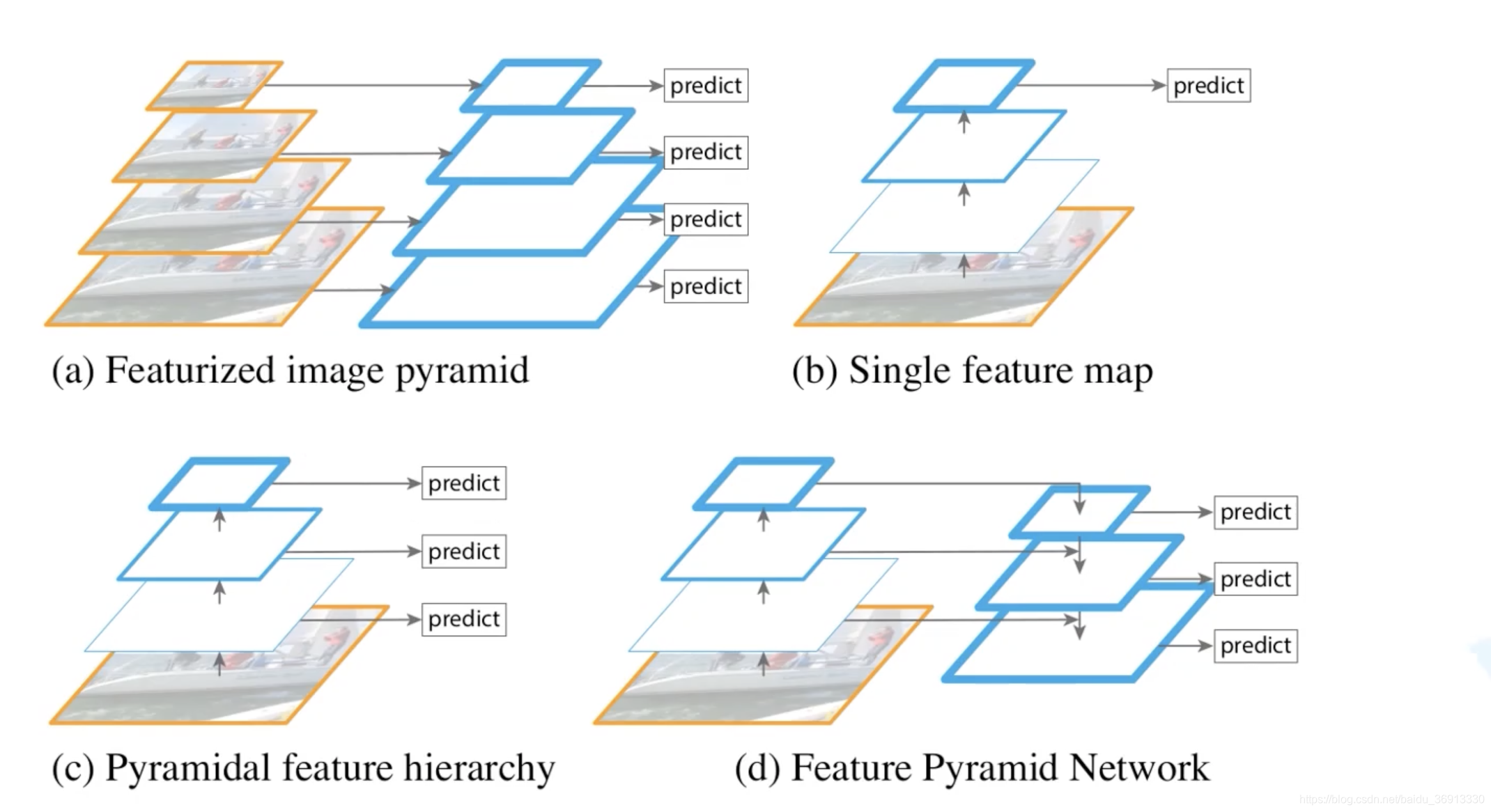
深度学习之目标检测(三)-- FPN结构详解深度学习之目标检测(三)FPN结构详解1. FPN —— 特征金字塔深度学习之目标检测(三)FPN结构详解本章学习 FPN 相关知识,学习视频源于 Bilibili。1. FPN —— 特征金字塔FPN 原始论文为发表于 2016 CVPR 的 Feature Pyramid Networks for Object Detection。针对目标检测任务,
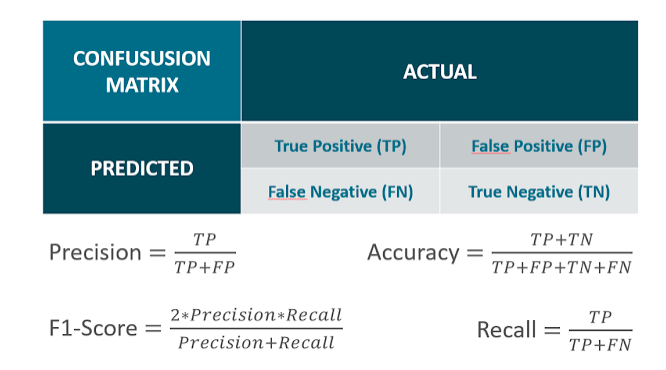
深度学习之图像分类(一)-- 分类模型的混淆矩阵深度学习之图像分类(一)分类模型的混淆矩阵1. 混淆矩阵1.1 二分类混淆矩阵1.2 混淆矩阵计算实例2. 混淆矩阵代码3. 混淆矩阵用途深度学习之图像分类(一)分类模型的混淆矩阵今天开始学习深度学习图像分类模型Backbone理论知识,首先学习分类模型的混淆矩阵,学习视频源于 Bilibili。1. 混淆矩阵混淆矩阵是评判模型结果的一种指标,属于模
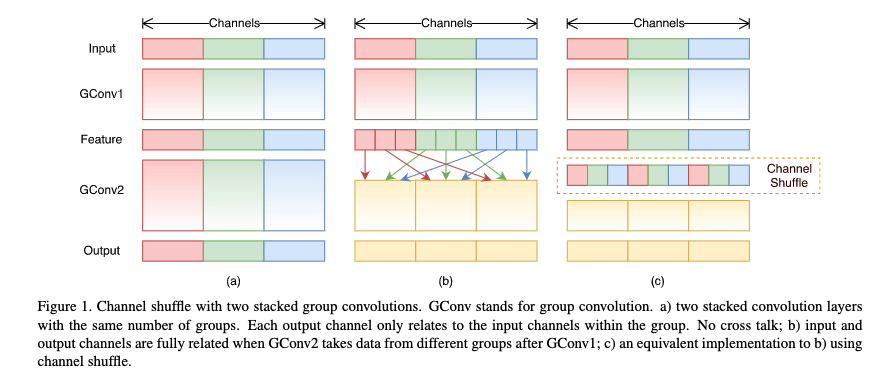
深度学习之图像分类(十三)ShuffleNetV1 网络结构目录深度学习之图像分类(十三)ShuffleNetV1 网络结构1. 前言2. Channel Shuffle3. ShuffleNetV1 网络结构4. 代码本节学习 ShuffleNetV1 网络结构。学习视频源于 Bilibili。1. 前言ShuffleNetV1 是由国产旷视科技团队在 2018 年提出的,其原始论文为 Shuf
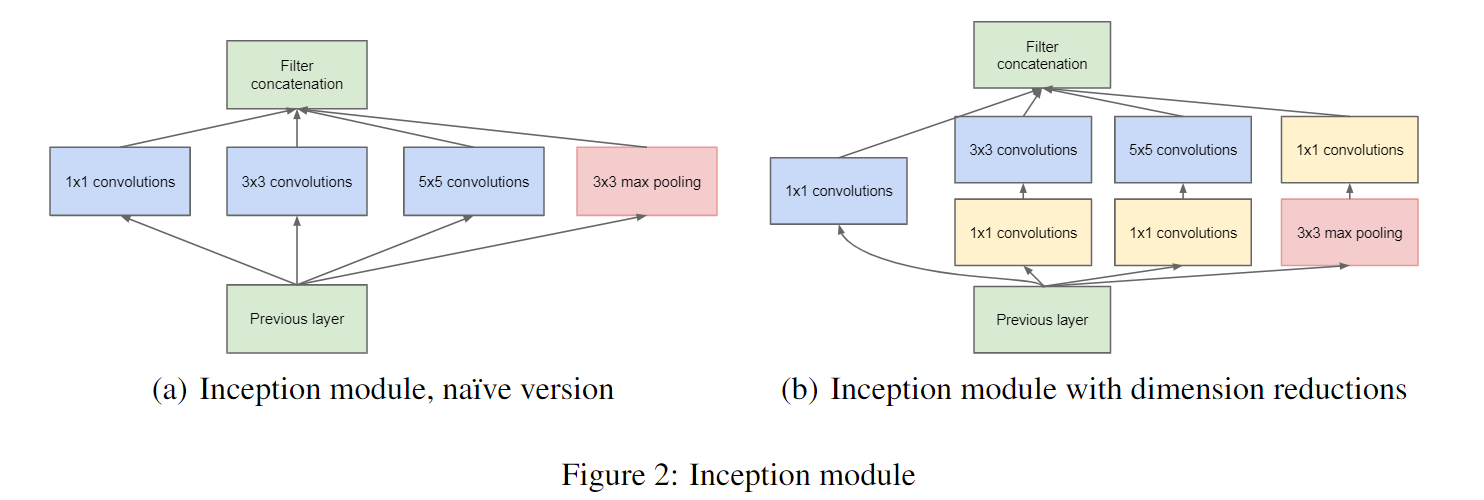
深度学习之图像分类(五)GoogLeNet网络结构目录深度学习之图像分类(五)GoogLeNet网络结构1. 前言2. Inception 结构3. 辅助分类器4. 代码本节学习 GoogLeNet 网络结构,学习视频源于 Bilibili,部分描述参考 大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)。1. 前言GoogLeNet 是 2014 年由 Google
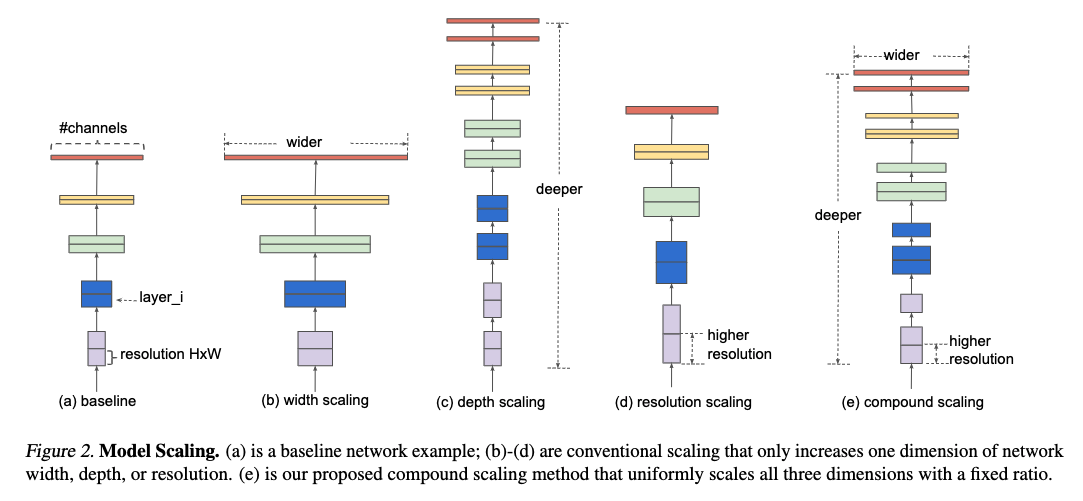
深度学习之图像分类(十五)EfficientNetV1 网络结构目录深度学习之图像分类(十五)EfficientNetV1 网络结构1. 前言2. 宽度,深度以及分辨率3. EfficientNetV1 网络结构4. 代码本节学习 EfficientNetV1 网络结构。学习视频源于 Bilibili。参考博客太阳花的小绿豆: EfficientNet网络详解.1. 前言EfficientNetV
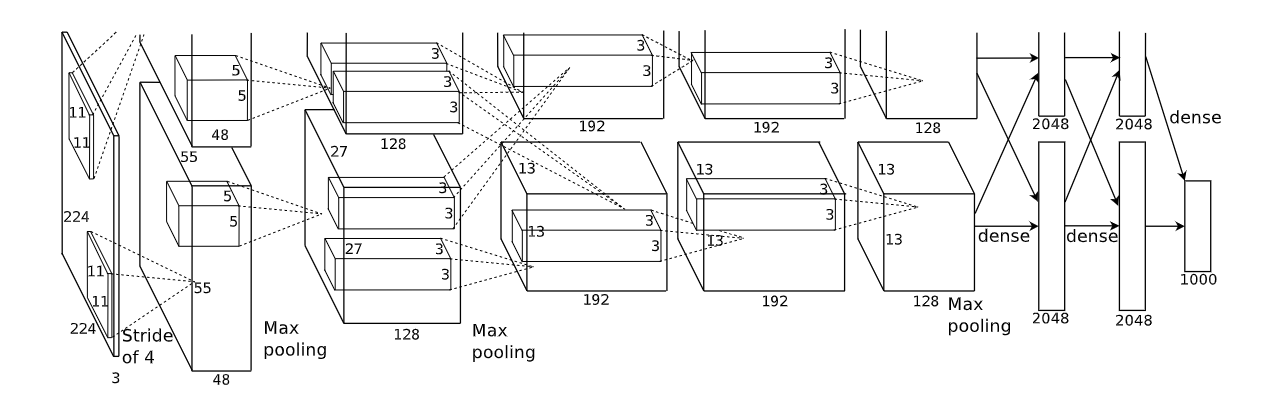
深度学习之图像分类(三)-- AlexNet网络结构深度学习之图像分类(三)AlexNet网络结构1. 前言2. 网络结构3. 其他细节3.1 Local Response Normalization (局部响应归一化)3.2 Overlapping Pooling (覆盖的池化操作)3.3 Data Augmentation (数据增强)深度学习之图像分类(三)AlexNet网络结构从本节开始,
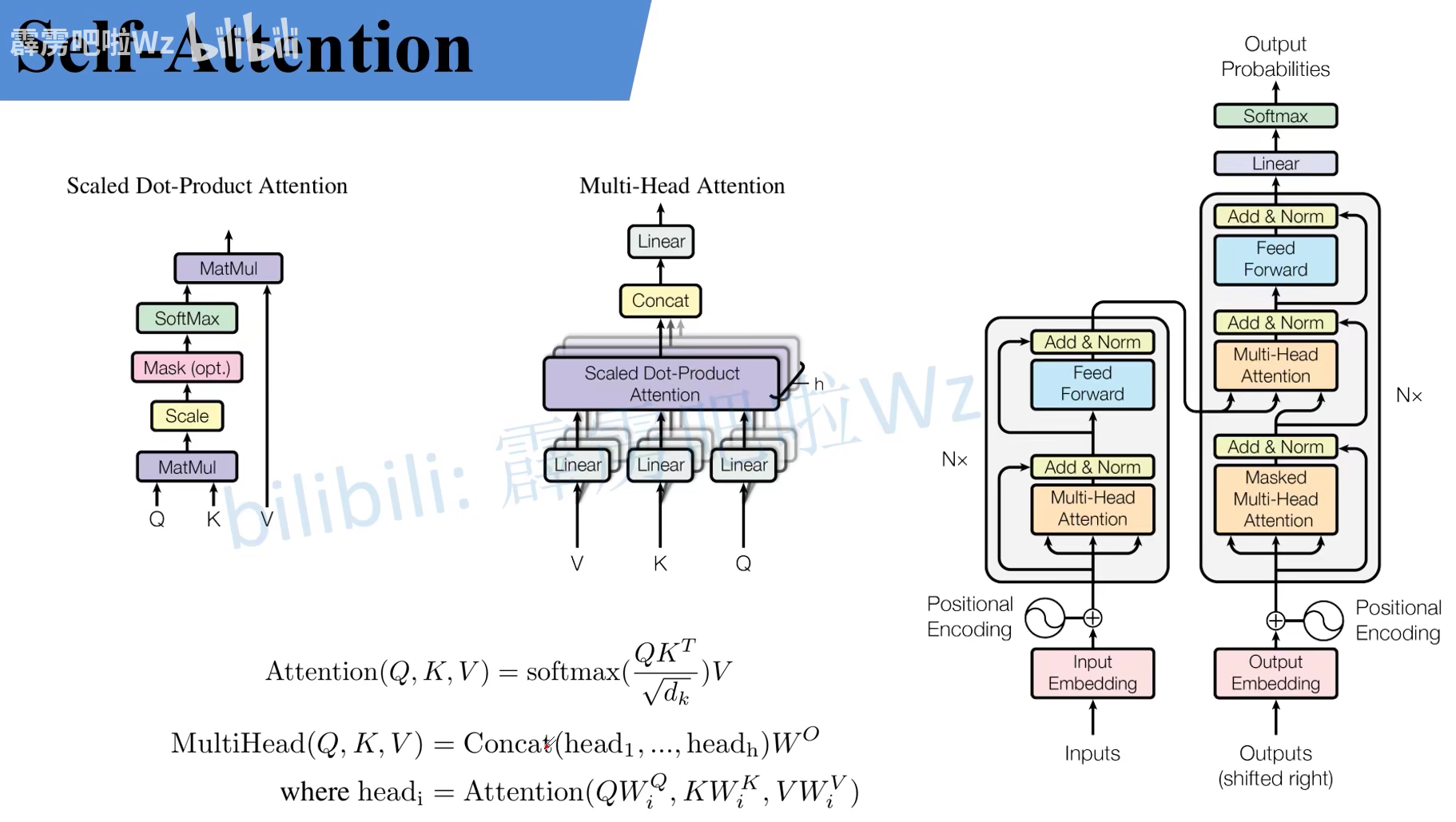
深度学习之图像分类(十七)Transformer中Self-Attention以及Multi-Head Attention详解目录深度学习之图像分类(十七)Transformer中Self-Attention以及Multi-Head Attention详解1. 前言2. Self-Attention3. Multi-head Self-Attention3. Positional Encoding