- @asd8705
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在我们的迷你R1实验中,我们使用了GRPO,并采用了两个基于规则的奖励,但已经需要大量的计算资源:4块H100 GPU运行6小时,才能完成一个30亿参数模型的450个训练步骤。在这个阶段,DeepSeek-R1-Zero(DeepSeek-R1的首次测试)学会了在没有任何人类反馈或描述如何进行操作的数据的情况下,通过重新评估其初始方法,为问题分配更多的思考时间。模型开始学习一种新的“格式”,它以类

1.IKAnalyzer2.中科院ICTCLAS3.FudanNLP4.The Stanford Natural LanguageProcessing Group4.1 Stanford CoreNLP4.2 Stanford Word Segmenter4.3 Stanford POS Tagger4.4 Stanford Named Entity Recognize
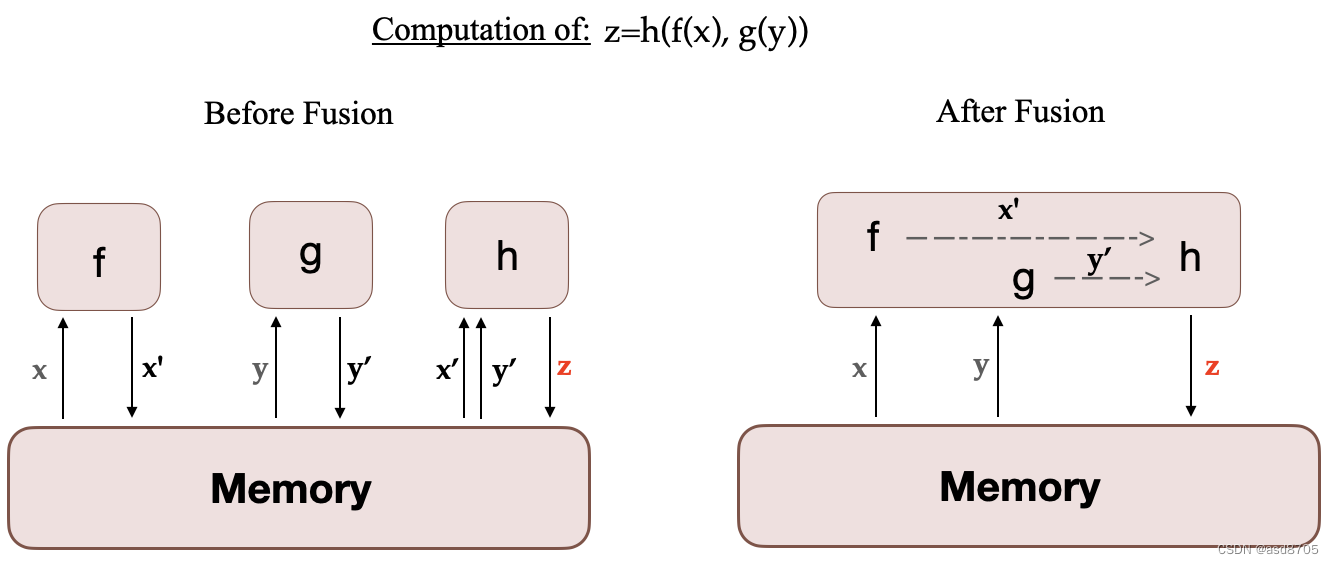
🤗 Transformers 还支持使用 Trainer API 来训练,其在 PyTorch 中提供功能完整的训练接口,甚至不需要自己编写训练的代码。第一种选择是设置张量并行,它将模型中的张量拆分到多个 GPU 上并行运算,你需要将 tensor-model-parallel-size 参数更改为所需的 GPU 数量。你可以使用如下所示配置模型架构和训练参数,或将其放入你将运行的 bash 脚
在这篇博客中,我们探索了向量嵌入的复杂世界,从传统的稀疏和密集形式到创新的学习稀疏嵌入。我们还研究了两个机器学习模型——BGE-M3和Splade——以及它们如何工作以生成学习到的稀疏嵌入。使用这些复杂嵌入来细化搜索和检索系统的可能性,为开发直观且响应迅速的平台开辟了新的可能性。请继续关注未来的帖子,展示这些技术的实际应用和案例研究,展示它们对信息检索标准的影响,承诺重新定义信息检索标准。


训练一个7B参数的大模型,显存需求大约为120-144 GB。实际需求可能因实现和硬件不同而有所变化。使用来训练模型可以显著减少显存占用,因为 BF16 每个参数仅占用2 字节(16 位),而不是 FP32 的 4 字节。使用BF16训练一个 7B 参数的大模型,显存需求大约为88-106 GB。相比 FP32 的 120-144 GB,BF16 可以节省约 25-30% 的显存。

Artificial Intelligence for IT Operations(AIOps,IT 智能运维)是指结合大数据和 Machine Learning,将包括异常检测、事件关联以及运营数据采集和处理在内的 IT 流程实现自动化。借助 AIOps,团队能够大幅减少大规模检测、了解、调查和解决事件所需的时间和精力。进而,在故障排查期间节省时间便可让 IT 团队将更多精力投入到更有价值的任务

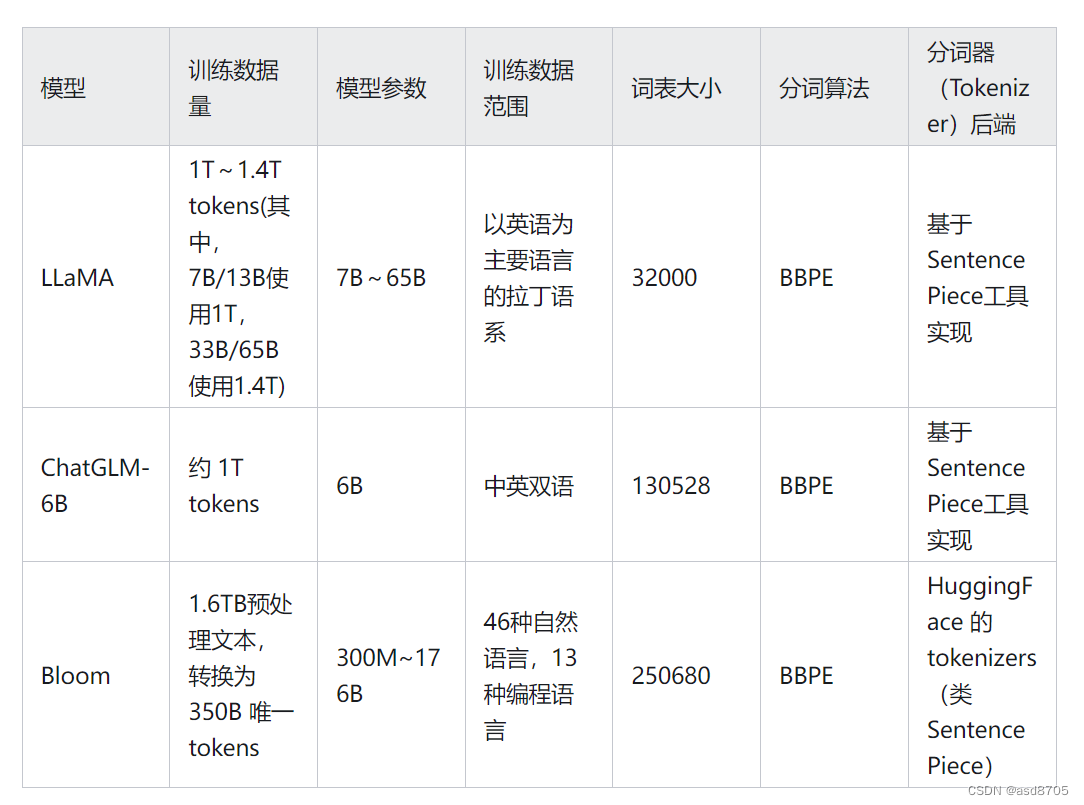
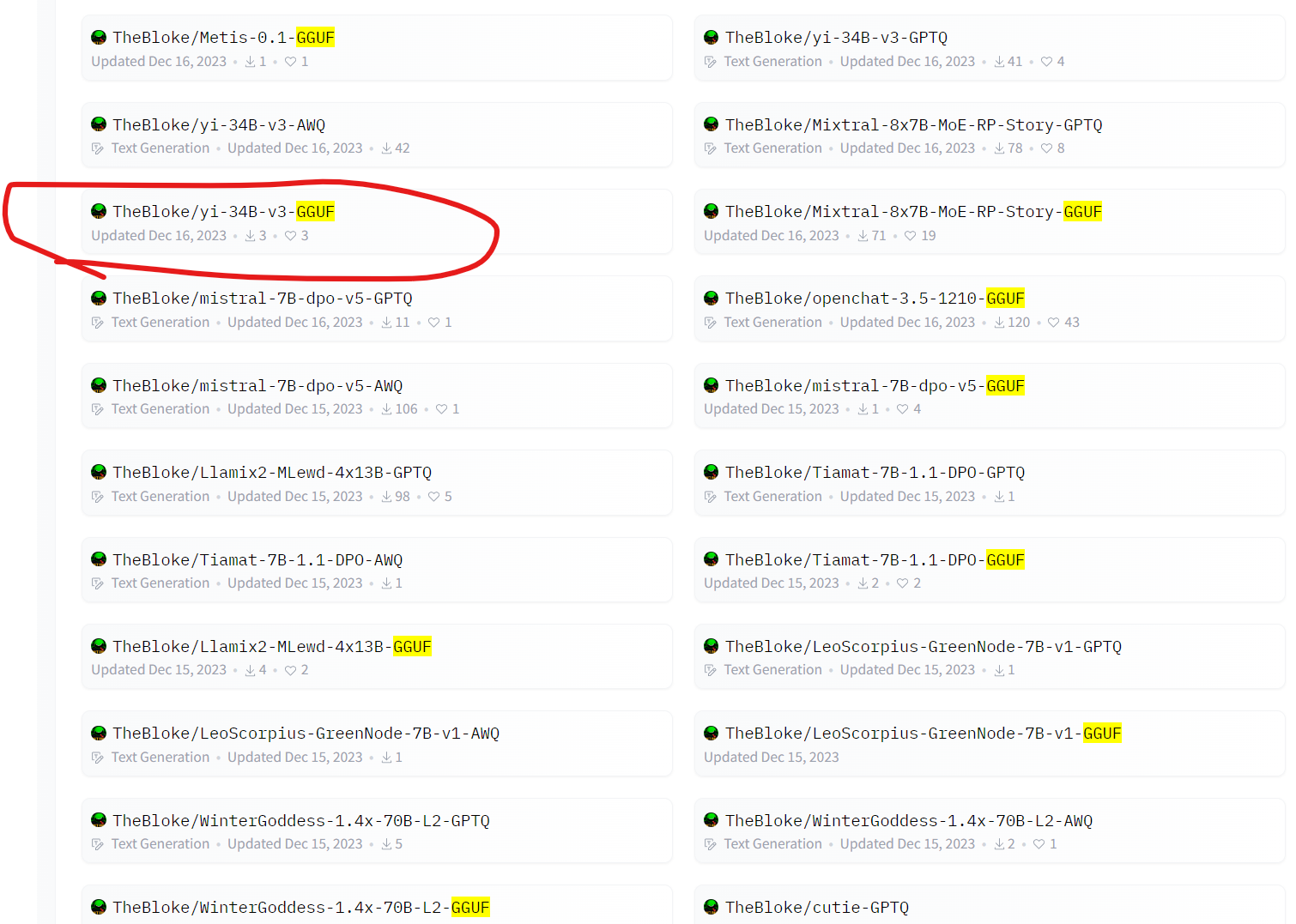
不同的计算平台可能采用不同的端序。很多模型模型,如Yi-34B、Llama2-70B等模型都有对应的GGUF版本,这些版本都模型除了文件名多了GGUF外,其它与原有的模型名称完全一致。此前,Georgi Gerganov推出了GGML工具,并推出了与之相应的大模型格式GGML,但是由于GGML设计落后于时代的发展,因此被弃用,由GGUF替代。大语言模型的开发通常使用PyTorch等框架,其预训练结
大模型量化技术通过减少模型参数的精度,显著降低了模型的存储和计算需求,同时尽量保持模型性能。不同的量化方法(如PTQ、QAT、QAF)和量化粒度(如逐层、逐通道)可以根据具体需求选择,以实现模型的高效部署。AWQ(Activation-aware Weight Quantization)和AutoAWQ是基于激活感知的权重量化技术,主要用于在不显著损失精度的情况下,将大型语言模型(LLM)的权重压

SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。这使得我们可以制作一个不依赖于特定语