- @admin_maxin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
整个过程一般可以概括为四部分,语料预处理->特征工程->模型训练->指标评价第一部分:语料预处理通过语料清洗、分词、词性标注、去停用词四个大的方面来完成语料的预处理工作。(1)语料清洗数据清洗,顾名思义就是在语料中找到我们感兴趣的东西,把不感兴趣的、视为噪音的内容清洗删除,包括对于原始文本提取标题、摘要、正文等信息。对于爬取的网页内容,去除广告、标签、HTML、JS 等代码和注释
vLLM框架针对MoE模型部署提出创新解决方案,通过分组TopK路由算法、令牌重排对齐机制和混合精度专家计算三大核心技术,有效解决了计算资源碎片化、跨设备通信瓶颈和内存管理复杂性等核心挑战。该系统支持动态专家选择策略和多模态处理,在70B参数的MoE模型上实现75%以上的GPU利用率,显存占用降低40%,吞吐量较传统方案提升3倍。未来将发展自适应专家并行和异构专家部署等功能,为万亿参数模型提供高效
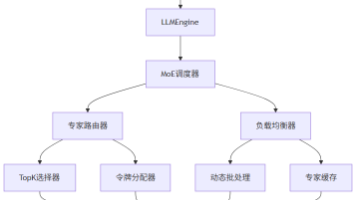
vLLM框架针对MoE模型部署提出创新解决方案,通过分组TopK路由算法、令牌重排对齐机制和混合精度专家计算三大核心技术,有效解决了计算资源碎片化、跨设备通信瓶颈和内存管理复杂性等核心挑战。该系统支持动态专家选择策略和多模态处理,在70B参数的MoE模型上实现75%以上的GPU利用率,显存占用降低40%,吞吐量较传统方案提升3倍。未来将发展自适应专家并行和异构专家部署等功能,为万亿参数模型提供高效
本文系统探讨了大模型量化技术的理论基础与实现方法。首先介绍了对称量化(absmax方法)和非对称量化(零点量化)的基本原理,分析了量化误差的产生机制。随后重点讨论了GGUF分组量化方法,通过具体示例展示了4位量化过程。在优化方法方面,详细阐述了GPTQ的后训练量化技术,包括其Hessian-based误差补偿机制和LazyBatch-Updates加速策略。最后介绍了AWQ方法,该方法通过激活感知
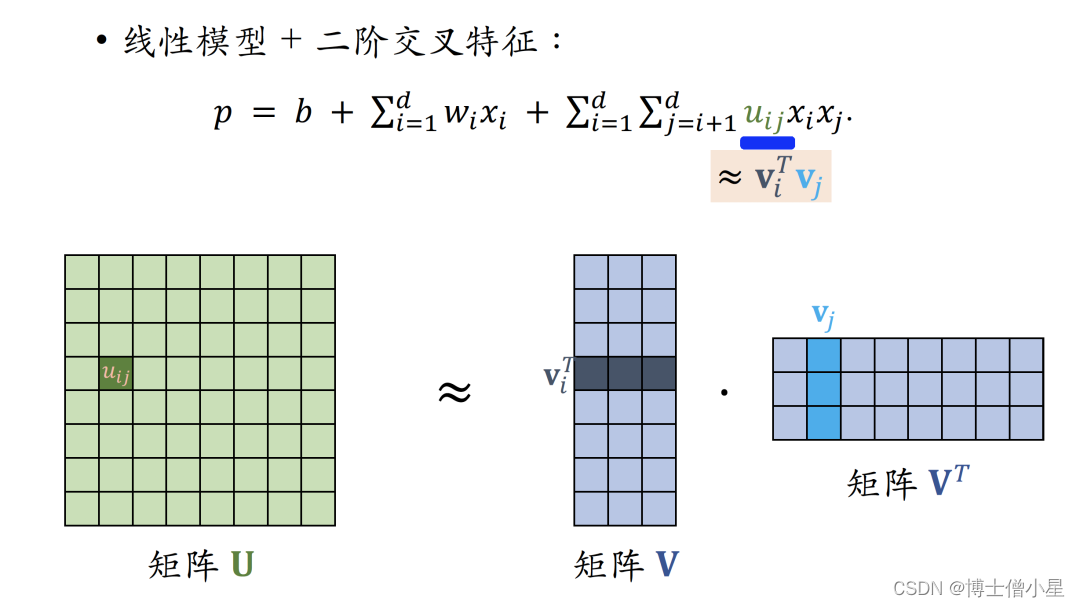
SENet 对离散特征做field-wise加权,如果有𝑚 个fields,那么权重向量是𝑚 维。FiBiNet可以理解为同时考虑了SENet 结合 Field 间特征交叉。之前提到过的召回、排序模型中的神经网络可以用任意网络结构;LHUC起源于语⾳识别,快⼿将LHUC应⽤在推荐精排,称作PPNet。深度交叉网络就是两个分支,一边是全连接,一边是交叉网络。线性模型预测是特征的加权和。交叉网络就
是一个强大的开源Python库,它专为简化和美化神经网络图的绘制而设计。
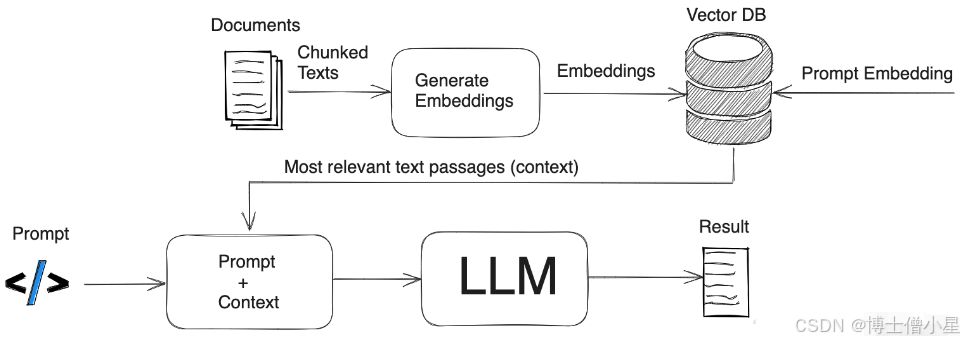
AnythingLLM 是 Mintplex Labs 开发的一款可以与任何内容聊天的私人ChatGPT,是高效、可定制、开源的企业级文档聊天机器人解决方案。它能够将任何文档、资源或内容片段转化为大语言模型(LLM)在聊天中可以利用的相关上下文。AnythingLLM 支持多种文档类型(PDF、TXT、DOCX等),具有对话和查询两种聊天模式。
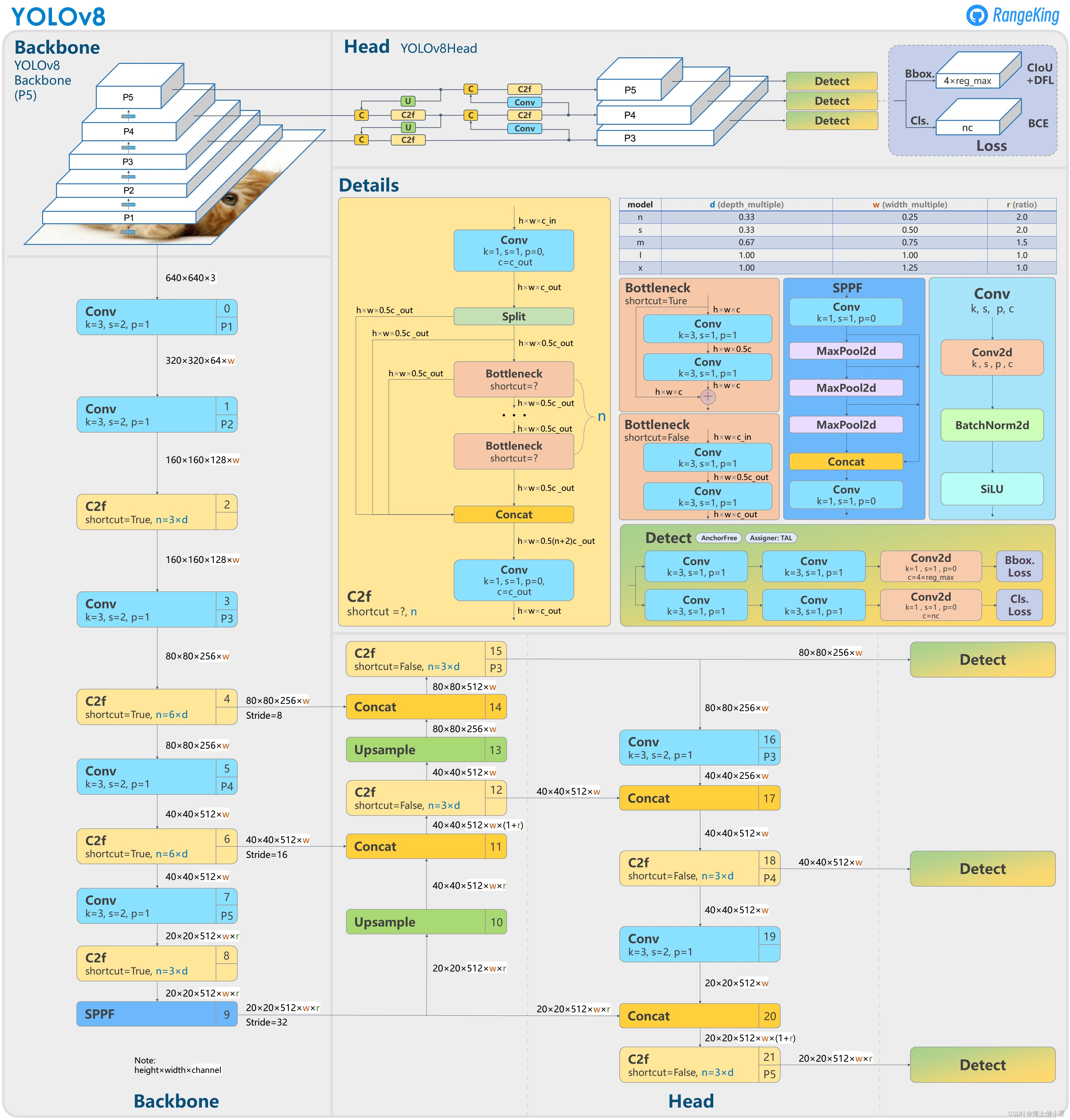
YOLOV8
离散特征可以用Embedding Layers,连续特征可以归一化、分桶等处理。Swing额外考虑重合的⽤户是否来⾃⼀个⼩圈⼦,两个⽤户重合度⼤,则可能来⾃⼀个⼩圈⼦,权重降低。简单负样本可以是全体物品(考虑非均匀采样打压热门物品)或者Batch内负样本。⽤户兴趣动态变化,⽽物品特征相对稳定,事先存储物品向量𝐛,线上现算⽤户向量𝐚。困难负样本主要考虑被召回,但是被排序淘汰的样本。一个物品的两个

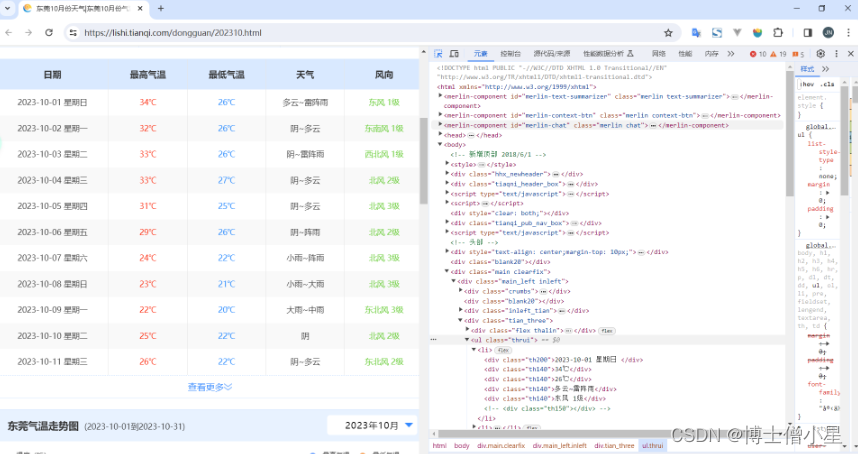
在文中,我们旨在利用爬取的历史天气数据进行可视化分析。首先,我们选择了一个可靠的数据源,并使用Python编程语言和BeautifulSoup库实现了数据的爬取。接着,我们对原始数据进行了清洗和处理,包括缺失值的处理和数据格式转换。然后,我们采用了Matplotlib可视化工具,设计了多种图表类型,如折线图、柱状图和热力图,以展示历史天气数据的趋势和变化。通过分析结果,我们发现了不同时间段内温度、