




- @a131529
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
集成学习(Ensemble Learning)是一种机器学习方法,通过将多个学习器(也称为基分类器或弱分类器)组合在一起,以达到更好的预测性能。集成学习通过结合多个学习器的预测结果,可以降低单个学习器的偏差、方差或提高泛化能力,从而提高整体的预测准确性和鲁棒性。集成学习的基本思想是“三个臭皮匠,顶个诸葛亮”,即通过组合多个弱分类器来形成一个强分类器。这种思想来源于统计学中的“多数表决原则”,即通过

聚类是一种无监督学习方法,用于将数据集中的样本划分为具有相似特征的组或簇。聚类的目标是在不事先知道样本的类别标签的情况下,通过发现数据内在的结构和模式,将相似的样本归为一类,并将不相似的样本彼此分开。聚类算法的工作原理通常是基于样本之间的相似性度量或距离度量。常见的聚类算法包括K均值聚类、层次聚类、DBSCAN、高斯混合模型等。自此,可总结出 K-Means 算法的步骤:① 随机选择 k 个样本作
记录本人的机器学习历程。
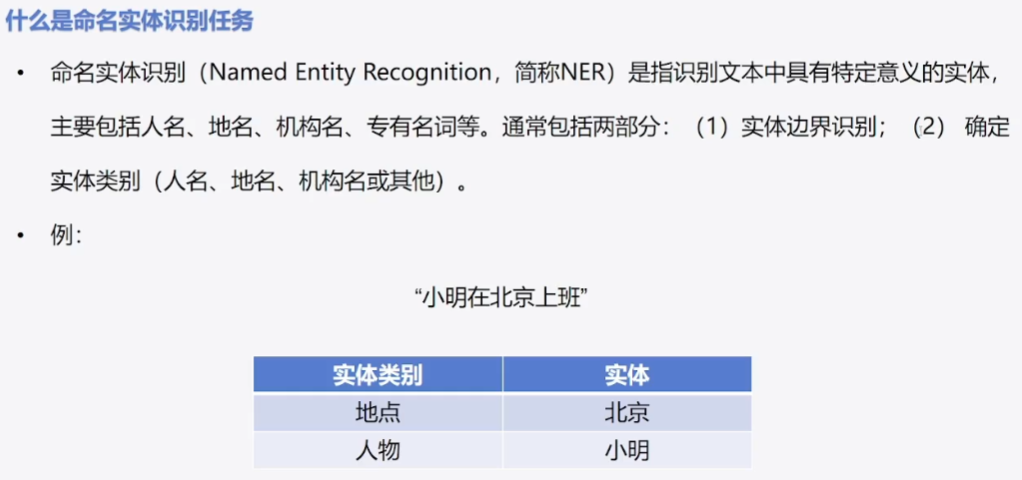
目录1 命名实体识别任务介绍2 基于Transfromers的解决方案2.1 模型结构:2.2 评估函数:3 代码实战演练1)导包:2)加载数据集3)数据预处理4)创建模型5)常见评估函数6)配置训练参数 7)创建训练器 8)模型训练 9)模型预测4 NER实战过程中需要注意的7点: 使用不同的model head用于解决不同的任务,如果说我们需要对每一个词(token)去做一个标签预测的话,这个
优点:Transformer是一种强大的模型,已在多个NLP任务中取得了成功。相比传统的循环神经网络(RNN)和卷积神经网络(CNN),Transformer在处理长序列和捕捉长距离依赖关系方面表现出色。Transformer的并行化能力很强。由于没有序列依赖性,Transformer可以同时处理输入序列中的所有位置,因此可以在多个GPU上并行计算,加速训练过程。Transformer通过引入自注

大模型就是在做迁移学习的这样一种事情:先在大规模无标注数据集中进行无监督学习训练,然后引入具体的样本(标注数据)进行参数微调,得到一个能在具体任务上表现极佳的模型。把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。
链接: https://pan.baidu.com/s/1ZboqS6D5Rc705piL0ANXog?

它的目标是要通过与环境(Environment)交互,根据环境的反馈(Reward),优化自己的策略(Policy),再根据策略行动(Action),以获得更多更好的反馈奖励(Reward)。大语言模型也不属于生成式AI,比如谷歌的BERT,不擅长长文本生成工作。有能力学习输入序列中的所有词的相关性和上下文,不会收到短时记忆的影响;并非所有的生成式AI都属于大语言模型,如图像的扩散模型,并不输出文
