




- @ZGY9542
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
现代药物发现的关键是发现,识别和准备药物分子靶标。但是,由于通量,精度和成本的影响,传统的实验方法很难广泛用于推断这些潜在的药物-靶标相互作用(DTI)。因此,迫切需要开发有效的计算方法来验证药物与靶标之间的相互作用。作者开发了基于深度学习的DTI预测模型。蛋白质的进化特征是通过特定位置评分矩阵(PSSM)和勒让德矩阵(LM)提取的,并与药物分子的亚结构指纹相关联,以形成药物-靶对的特征向量。然后
琥珀酰化后蛋白质中发生的总体局部变化已显示出与基因活性变化相对应,并受到柠檬酸循环缺陷的干扰,这些观察结果与琥珀酸在细胞呼吸过程中作为代谢中间体生成的事实一起,提示了琥珀酸蛋白可能在细胞代谢与重要细胞功能之间的相互作用中发挥作用。例如,琥珀酰化可能代表基因组调节和修复的重要方面,并且可能在许多疾病状态的病因学中产生重要影响。在这项研究中,作者开发了DeepSuccinylSite,这是一种新颖的预
提出了一种深层生成模型:深度递归注意力写入器(DRAW)(Deep Recurrent Attentive Writer),该模型具有通过重复部分生成而不是通过一次正向传播生成图像来生成单个图像的特性。模仿人眼空间注意力机制的带有视觉偏好性的,可变自动编码框架,其主要功能是用于复杂图像的迭代构造。
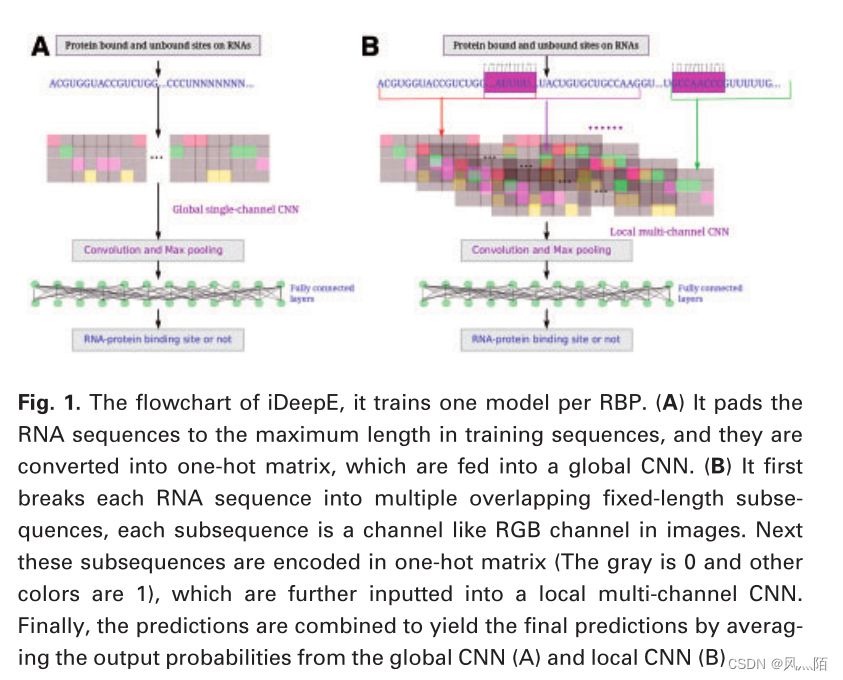
RNA 结合蛋白占真核蛋白质组的5-10%,并在许多生物过程中发挥关键作用。RBP结合位点的实验检测仍然是耗时且成本高的。而使用从现有注释知识中学习的模式对RBP结合位点进行计算预测是一种快速方法。从生物学的角度来看,源自局部序列的局部结构上下文将被特定的RBP识别。然而,在使用深度学习的计算建模中,只使用了整个RNA序列的全局表示。到目前为止,在深度模型构建过程中忽略了局部序列信息。在这项研究中
基于靶标蛋白的药物研发是一种成功的策略,但许多疾病机理或者发病机制缺乏明显的靶点来实现这种方法。为了克服这一挑战,该研究描述了一种基于深度学习和基因指纹的药效预测系统 (DLEPS),该系统使用疾病相关基因表达谱的变化作为输入来识别候选药物。DLEPS 使用 L1000 项目中化学诱导的转录谱变化进行训练。该研究发现,以前未知的转录谱的变化Pearson相关系数被预测为 0.74。该研究在3种代谢
开发一种深度学习(DL)模型,用于自动分类黄斑孔(MH)Aetiology(特发性或次要),以及在1个月内可靠地预测MH状态(关闭或打开)的多模式深融合网络(MDFN)模型玻璃体切除术和内部限制膜剥离(Vilmp)。有330 MH的眼睛具有1082个光学相干断层扫描(OCT)图像和3300个从四个眼科中心注册的临床数据,用于训练,验证和外部测试DL和MDFN模型。从三个中心的266只眼睛被患者随机
伪尿苷(Pseudouridine,Ψ)在核糖核酸、核糖核酸、转录核糖核酸和核仁核仁等多种核糖核酸修饰中广泛存在。因此,鉴定它们在学术研究、药物开发和基因治疗等方面具有重要意义。本文提出了一种采用二进制编码的多通道卷积神经网络。作者使用k折交叉验证和网格搜索来调整超参数。在独立的数据集上评估了它的性能,发现了有希望的结果。结果证明,作者的方法可以用于识别相关目的的伪尿苷位点。
作为一种新发现的蛋白质翻译后修饰,赖氨酸乳酸化(Kla)在各种细胞过程中起着举足轻重的作用。高通量质谱法是检测 Kla 位点的主要方法。然而,与计算方法相比,识别 Kla 位点的实验方法通常既耗时又费力。因此,需要开发一种强大的工具来识别 Kla 站点。为此,作者通过结合嵌入层、卷积神经网络、双向门控循环单元和注意机制层,提出了第一个称为 DeepKla 的计算框架,用于水稻中 Kla 位点预测。
现代药物发现的关键是发现,识别和准备药物分子靶标。但是,由于通量,精度和成本的影响,传统的实验方法很难广泛用于推断这些潜在的药物-靶标相互作用(DTI)。因此,迫切需要开发有效的计算方法来验证药物与靶标之间的相互作用。作者开发了基于深度学习的DTI预测模型。蛋白质的进化特征是通过特定位置评分矩阵(PSSM)和勒让德矩阵(LM)提取的,并与药物分子的亚结构指纹相关联,以形成药物-靶对的特征向量。然后
对离子通道具有高亲和力的配体肽对于调节跨质膜的离子通量至关重要。在这项工作中,作者开发了 Multi-Branch-CNN,这是一种具有多个输入分支的 CNN 方法,用于从特征内和特征间类型中识别三种类型的离子通道肽结合剂(钠、钾和钙)。为此,作者在两个测试集上测试了开发的模型:一个通用测试集,包括与训练集具有不同相似度的序列;以及一个新的测试集,仅包含与训练集序列几乎没有相似之处的序列。最终的实