




- @Walksunw
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
官方演示:一句“帮我把 Notion 里的 PRD 生成前端代码并部署到 Vercel”,K2 自动完成 Notion API→代码→GitHub→Vercel 的全链路。同时Perplexity 已抢先“二次预训练”Perplexity CEO 发推表示正基于 K2 做后训练,计划打造“搜索 Agent 2.0”。基准成绩:开源新 SOTA,部分指标碾压 GPT-4.1,代码、数学推理能力直逼c

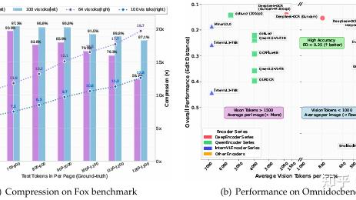
DeepSeek-OCR推出革命性"光学压缩"技术,仅30亿参数即实现10倍无损压缩,在单张A40显卡上日处理20万页文档。该技术将文本转为图像后用视觉token压缩,100个token可还原千字文档(97%精度),比传统方法节省90%资源。模型采用仿生设计模拟人类记忆遗忘曲线,支持6种分辨率模式自动切换。核心架构包含高效压缩的DeepEncoder编码器和低延迟的3B-MoE
谷歌DeepMind正式发布新一代AI模型Gemini 3.0,推出Pro专业版与Flash轻量版两个版本。该模型在代码生成和全场景适配方面实现重大突破,可一键生成完整Web操作系统,编程能力显著超越GPT-5等竞品。技术亮点包括改进的MoE架构、多模态融合和终端适配优化,使延迟降低至前代的1/3,并支持8GB显存本地部署。实测显示,Gemini 3.0能生成功能完整的Web版macOS系统,在物
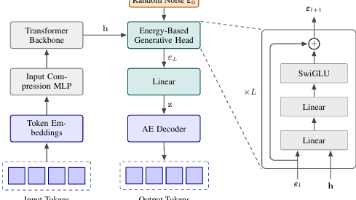
微信AI与清华大学联合发布的CALM模型突破了大语言模型的传统token预测范式,创新性地将多个token压缩为语义向量进行预测。该模型通过四个核心模块实现端到端生成,其中语义压缩模块采用自编码器实现99%准确率的无损压缩,生成模块则基于Energy Transformer实现连续向量预测。研究表明,当K=4时,CALM在保持性能相当的前提下,训练算力降低44%,推理算力降低34%,显著提升了效率
摘要:GitHub 2025年数据显示TypeScript以263.6万贡献者超越Python登顶,增长66%。这一变化反映开发范式转型:类型化语言成为AI时代的首选,现代框架默认使用TS,其严格类型系统显著提升AI代码可靠性。Python虽在AI领域仍以58.2万仓库占据主导,但TS与Python形成互补格局,分别代表工业级开发与快速迭代的不同优势。微软TS Native预览版性能提升10倍,进

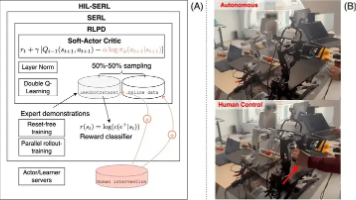
HuggingFace联合牛津大学推出《Robot Learning: A Tutorial》教程和LeRobot开源工具库,为机器人学习新手提供"理论+实践"的入门指南。教程从传统机器人学的局限切入,详细讲解强化学习、模仿学习等核心技术,并配套开源工具包,包含SOTA方法、预训练模型和模拟环境。特别推荐轻量化VLA模型SmolVLA,参数仅4.5亿,适合初学者调试。这套资源降
华为联合高校推出世界模型WorldGrow,实现室内3D场景生成技术突破。该模型能在单张A100显卡上30分钟生成272㎡高质量连贯场景,解决了传统AI建模中边缘断裂、逻辑混乱等问题。通过"双生成器搭档"和三线性插值算法,WorldGrow实现了高精度细节与逻辑化布局,测试指标FID值仅7.52。值得注意的是,这项由华为实习生主导研发的技术,已通过论文公开并集成至华为云盘古大模

本文原是github开源项目MC_thread_pool的说明文档,原文发送在此,同时本文中所有代码均在github中有完整实现,查看代码请移步github仓库!

摘要: DiC提出了一种纯卷积架构的扩散模型,在保持生成质量的同时显著降低计算成本。核心创新包括:**频率感知空洞卷积(FADC)**动态捕捉多尺度特征,**双路径残差(DPR)缓解深度梯度消失,以及混合频率采样(MFS)**优化训练效率。实验表明,DiC-B(72M参数)在512×512图像生成上FID达7.95,优于DiT-L(344M参数),且骁龙8 Gen3 NPU部署仅需0.9秒/图。开

XPath 是一门在 XML 文档中查找信息的语言。查找所有id属性等于head并且class属性等于s_down的div标签。html_tree = etree.HTML(html字符串)通过在路径表达式中使用“|”运算符,您可以选取若干个路径。谓语用来查找某个特定的节点或者包含某个指定的值的节点。选取文档中的所有 title 和 price 元素。查询所有id属性中包以he开头的div标签。查
